
In this tutorial, we implement an end-to-end workflow for Salesforce CodeGen. We load a CodeGen model from Hugging Face, prepare […]
Category: Large Language Model

OpenAI Releases LifeSciBench, a 750-Task Benchmark Grading AI Models on Real Life-Science Research With Expert-Written Rubric
Most biology benchmarks ask narrow, fact-based questions with clean answers. Scientists weigh imperfect evidence and make decisions. OpenAI released LifeSciBench […]

Z.ai Launches GLM-5.2 With a Usable 1M-Token Context, Two Thinking-Effort Levels, and No Benchmarks at Launch
GLM-5.2 is the latest large language model from Z.ai, becoming the third major release in the GLM-5 line. It follows […]

Moonshot AI Releases Kimi K2.7-Code: a Coding Model Reporting +21.8% on Kimi Code Bench v2 Over K2.6
This week, Moonshot AI released Kimi K2.7-Code. It is a coding-focused, agentic model. The model weights ship on Hugging Face […]
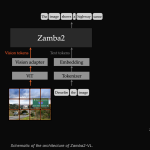
Zyphra Release Zamba2-VL: Hybrid Mamba2–Transformer Vision-Language Models That Cut Time-to-First-Token by About an Order of Magnitude
Zyphra has released Zamba2-VL, a family of open vision-language models. The release covers three sizes: 1.2B, 2.7B, and 7B parameters. […]

Google AI Releases DiffusionGemma, a 26B MoE Open Model Using Text Diffusion for Up to 4x Faster Generation
Google AI team including the Google DeepMind researchers have just released DiffusionGemma, an experimental open model for text generation. It […]

Anthropic Releases Claude Fable 5 and Claude Mythos 5: Same Underlying Model, Different Safeguards, New Mythos-Class Tier
Anthropic released two models on June 9, 2026: Claude Fable 5 and Claude Mythos 5. Both belong to a tier […]

Building Reflective Prompt Optimization with GEPA: Multi-Component Prompts, Structured Feedback, and Held-Out Validation
In this tutorial, we use GEPA as a reflective prompt-evolution framework to improve the way a language model solves arithmetic […]

Google DeepMind Releases Gemma 4 QAT Checkpoints: Q4_0 and a New Mobile Format Cut On-Device Memory
Google DeepMind released Quantization-Aware Training (QAT) checkpoints for the Gemma 4 family. The release targets local deployment on edge devices […]

NVIDIA AI Releases Dynamo Snapshot: A CRIU-Based Fast Startup System for AI Inference on Kubernetes
In production inference deployments, demand fluctuates over time, requiring inference replicas to scale elastically. Cold-starting inference workloads on Kubernetes can […]