
Google DeepMind has released Gemini Robotics 2, the intelligence layer for its next generation of robots. The release moves the […]
Category: Vision Language Model
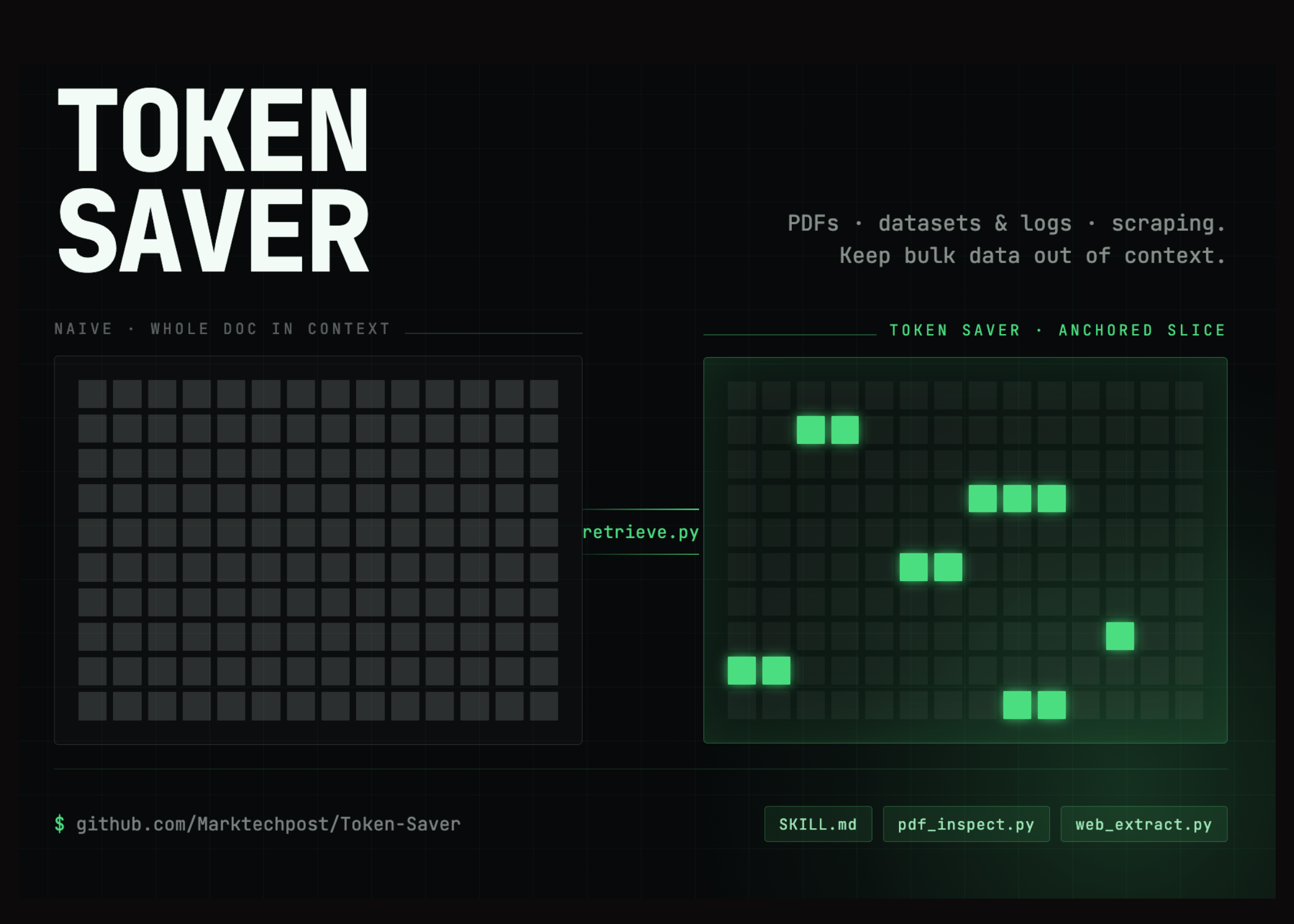
Meet Token Saver: An Open-Source MCP Extension Using Local Hybrid RAG to Cut Claude PDF Token Costs 90-99%
AI developers, researchers, and professionals frequently hit a frustrating wall when analyzing large documents with LLMs: the hidden, compounding cost […]
Datalab Marker v2 vs MinerU, Docling, and Liteparse: Benchmark Breakdown
Datalab has released Marker 2, a full rewrite of its open source document conversion pipeline. Marker converts PDF, image, PPTX, […]
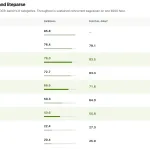
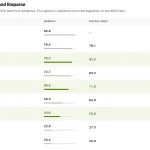
Datalab’s Marker 2 vs MinerU, Docling and LiteParse: 76.0 on olmOCR-bench at 5× MinerU’s Throughput
Datalab has released Marker 2, a full rewrite of its open source document conversion pipeline. Marker converts PDF, image, PPTX, […]

Best Local LLMs You Can Run on a Single 24GB GPU in 2026: Qwen, Gemma, Mistral, DeepSeek Compared
A single 24GB card is the practical floor for serious local inference. It is enough for genuinely capable models, and […]
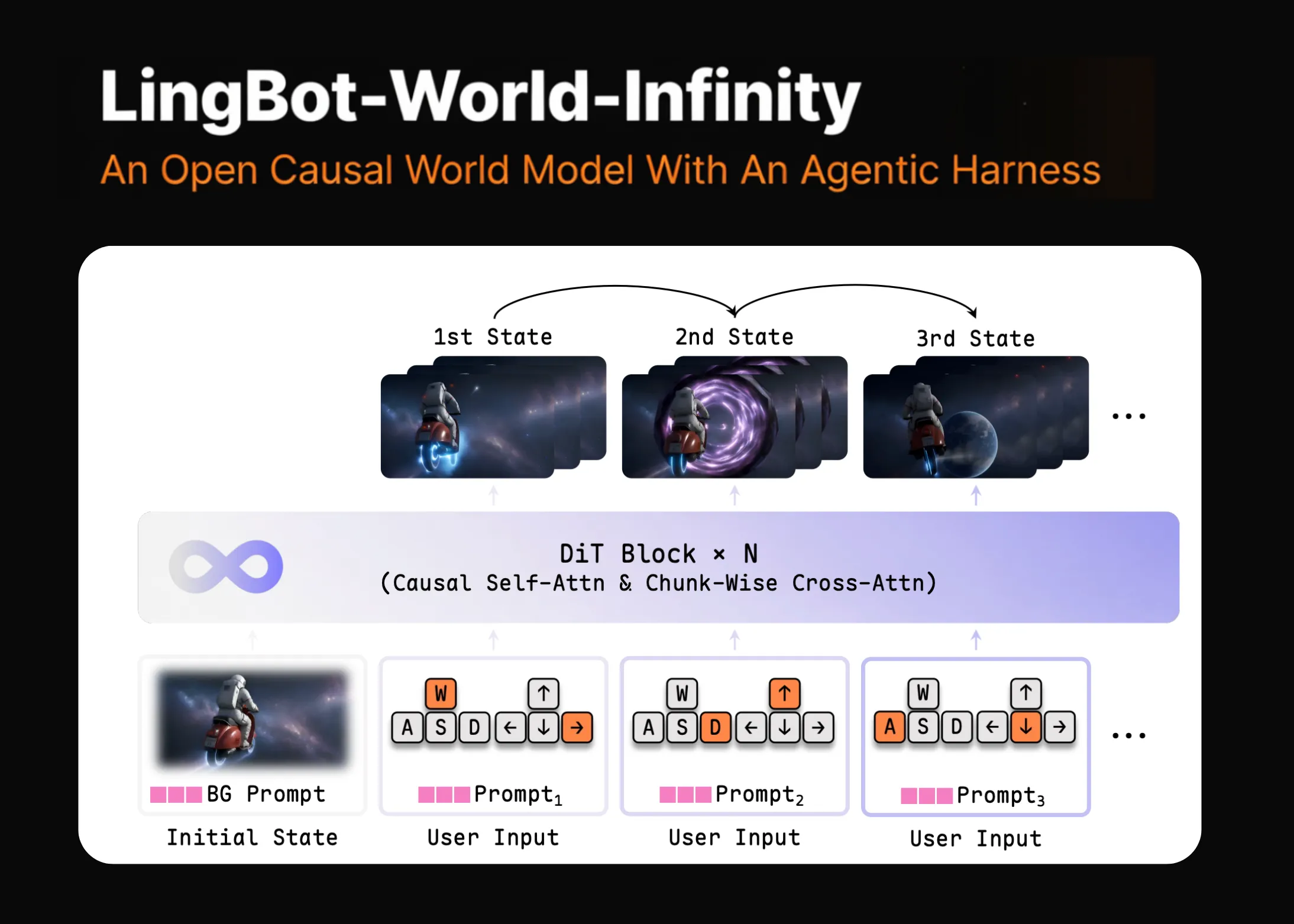
Meet LingBot-World-Infinity: An Open Causal World Model With An Agentic Harness
Robbyant, Ant Group’s embodied-intelligence unit, has released LingBot-World-Infinity (LingBot-World 2.0). It is a causal video generation model that behaves as […]

Ant Group’s Robbyant Open-Sources LingBot-Vision: A 1B Boundary-Centric Vision Foundation Model for Dense Spatial Perception
Robbyant, the embodied-AI company within Ant Group, has open-sourced LingBot-Vision, a family of self-supervised Vision Transformers built for dense spatial […]
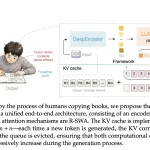
Baidu Releases Unlimited OCR, a 3B Model That Keeps the KV Cache Flat for Long-Document Parsing
Most end-to-end OCR models slow down as output grows. Each generated token adds to the KV cache. Memory rises and […]
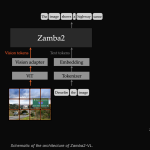
Zyphra Release Zamba2-VL: Hybrid Mamba2–Transformer Vision-Language Models That Cut Time-to-First-Token by About an Order of Magnitude
Zyphra has released Zamba2-VL, a family of open vision-language models. The release covers three sizes: 1.2B, 2.7B, and 7B parameters. […]

StepFun Releases Step 3.7 Flash: A 198B MoE Vision-Language Model for Coding Agents and Search Workflows
StepFun today released Step 3.7 Flash, a multimodal Mixture-of-Experts model targeting agentic use cases. It adds native vision input and […]