Most end-to-end OCR models slow down as output grows. Each generated token adds to the KV cache. Memory rises and […]
Category: OCR
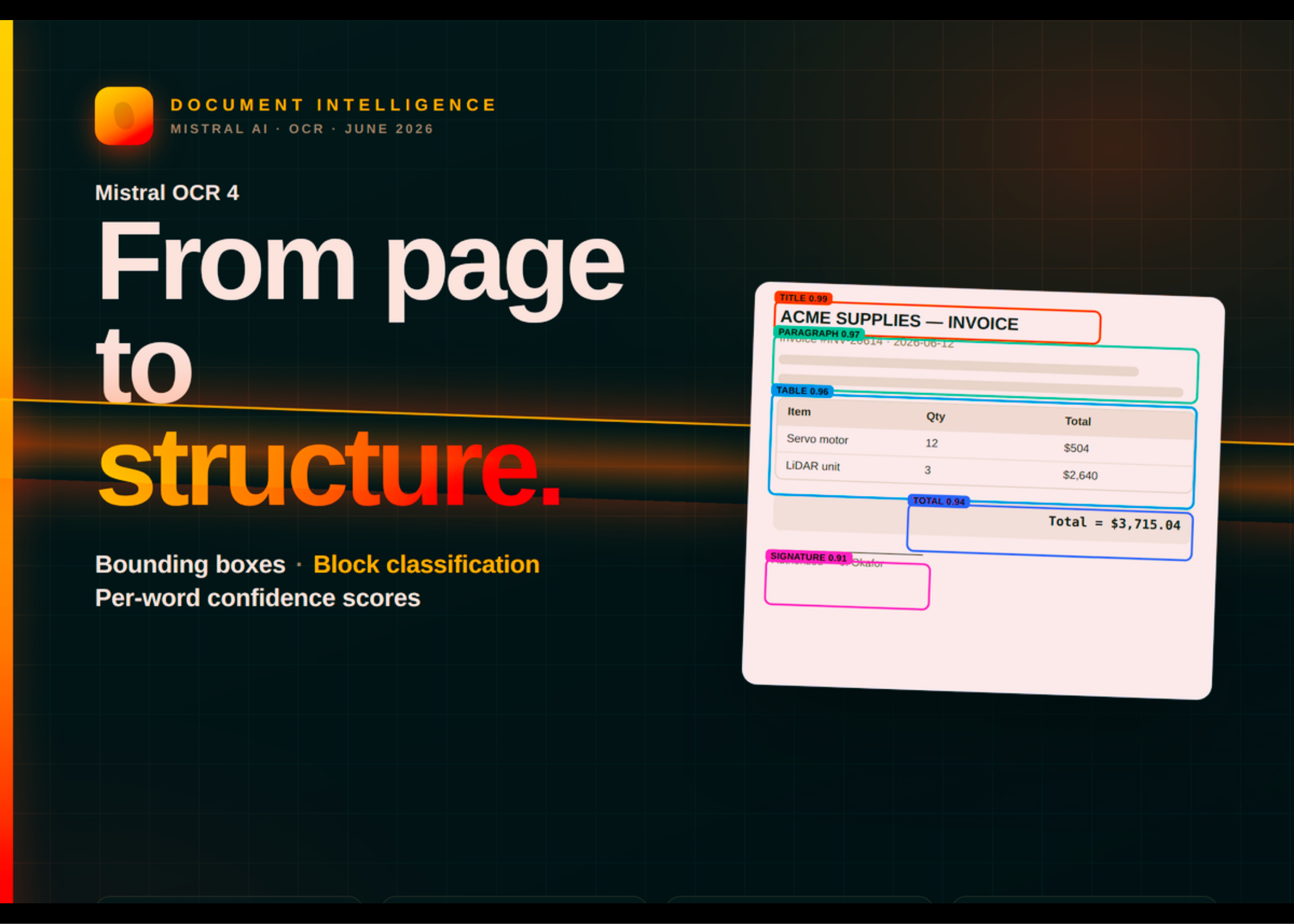
Mistral OCR 4 Brings Citation-Ready Structured Output to RAG, Agentic, and Enterprise Search Pipelines
Today, Mistral AI released OCR 4, its latest document-understanding model. This new release adds bounding boxes, block classification, and inline […]

Datalab Releases lift: A 9B Open-Weights Vision Model That Extracts Structured JSON From PDFs Using Schemas
Datalab has released lift, a 9B open-weights vision model for structured extraction. You pass it a JSON schema, and it […]

A Coding Guide to Build Advanced Document Intelligence Pipelines with Google LangExtract, OpenAI Models, Structured Extraction, and Interactive Visualization
In this tutorial, we explore how to use Google’s LangExtract library to transform unstructured text into structured, machine-readable information. We […]

TII Releases Falcon Perception: A 0.6B-Parameter Early-Fusion Transformer for Open-Vocabulary Grounding and Segmentation from Natural Language Prompts
In the current landscape of computer vision, the standard operating procedure involves a modular ‘Lego-brick’ approach: a pre-trained vision encoder […]

IBM Releases Granite 4.0 3B Vision: A New Vision Language Model for Enterprise Grade Document Data Extraction
IBM has announced the release of Granite 4.0 3B Vision, a vision-language model (VLM) engineered specifically for enterprise-grade document data […]
Alibaba Qwen Team Releases Qwen3.5 Omni: A Native Multimodal Model for Text, Audio, Video, and Realtime Interaction
The landscape of multimodal large language models (MLLMs) has shifted from experimental ‘wrappers’—where separate vision or audio encoders are stitched […]

LlamaIndex Releases LiteParse: A CLI and TypeScript-Native Library for Spatial PDF Parsing in AI Agent Workflows
In the current landscape of Retrieval-Augmented Generation (RAG), the primary bottleneck for developers is no longer the large language model […]
Baidu Qianfan Team Releases Qianfan-OCR: A 4B-Parameter Unified Document Intelligence Model
The Baidu Qianfan Team introduced Qianfan-OCR, a 4B-parameter end-to-end model designed to unify document parsing, layout analysis, and document understanding […]

New “vibe coded” AI translation tool splits the video game preservation community
Creator apologizes after using Patreon funds for Gemini-powered magazine scan processor. Translating the letter “A” is just one of many […]