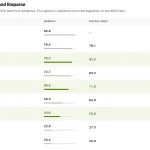
Datalab has released Marker 2, a full rewrite of its open source document conversion pipeline. Marker converts PDF, image, PPTX, […]
Category: New Releases
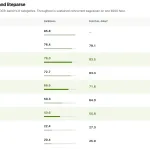
Datalab’s Marker 2 vs MinerU, Docling and LiteParse: 76.0 on olmOCR-bench at 5× MinerU’s Throughput
Datalab has released Marker 2, a full rewrite of its open source document conversion pipeline. Marker converts PDF, image, PPTX, […]

Meet the New Claude Opus 5: Frontier-Class Agentic Coding and Computer Use at Unchanged Opus Pricing
Today, Anthropic released Claude Opus 5. It replaces Claude Opus 4.8 as the Opus-tier flagship. Pricing is unchanged at $5 […]

Meet Gigatoken: A Rust BPE Tokenizer that Encodes Text at 24.53 GB/s, up to 989x Faster than HuggingFace Tokenizers
Tokenization is the one part of the language modeling stack that almost nobody profiles. Gigatoken, released by Marcel Rød (a […]

Anthropic Releases Claude Security Plugin for Claude Code in Beta: A Multi-Agent Vulnerability Scanner That Runs in Your Terminal
Anthropic has released the Claude Security plugin for Claude Code in beta. The plugin runs a multi-agent vulnerability scan of […]

Cisco Foundation AI Releases Antares: 350M and 1B Open-Weight Models That Localize Known Vulnerabilities Inside Real Codebases
Cisco Foundation AI has released Antares, a family of security small language models (SLMs) built for one narrow security task. […]

Poolside Releases Laguna S 2.1, an Open-Weight Agentic Coding Model Punching Above Its Weight Class on SWE-Bench Multilingual
Poolside has released Laguna S 2.1, a 118B-parameter open-weight model built for agentic coding. It is a Mixture-of-Experts (MoE) model […]

Google Releases Gemini 3.6 Flash, 3.5 Flash-Lite, and 3.5 Flash Cyber: A Cheaper, More Token-Efficient Flash Tier Built for Agentic Workloads
Developers building production agents need higher token efficiency, lower latency, and more reliable performance. Today, Google has released three new […]

Meta Open-Sources Astryx: An Agent-Ready React Design System With 150+ Accessible Components, Seven Themes, and a CLI
Meta has released Astryx, an open source design system that is fully customizable and built to be operated by both […]
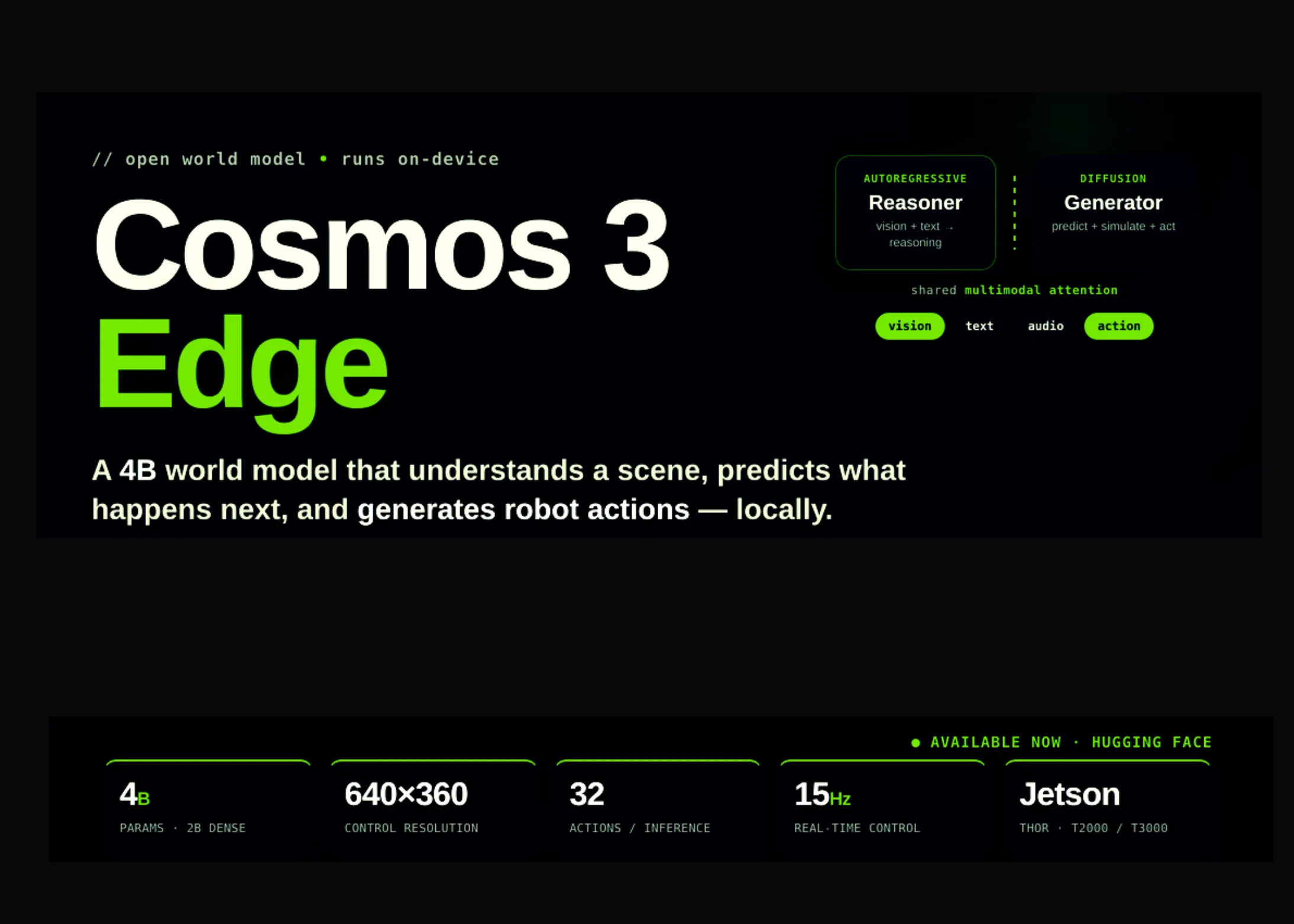
NVIDIA Releases Cosmos 3 Edge: A 4B-Parameter Open World Model That Reasons and Generates Robot Actions On-Device
NVIDIA has released Cosmos 3 Edge, a 4-billion-parameter open world model built to run on-device. It helps robots and vision […]