
Experts explain how they work, what they can do, and what’s still unsettled. Credit: Aurich Lawson | Getty Images Credit: […]
Category: Deep Learning

How to Build Memory-Efficient Transformers with xFormers Using Packed Sequences, GQA, ALiBi, SwiGLU, and Causal Attention
In this tutorial, we implement xFormers: a practical toolkit for building fast, memory-efficient Transformer models on GPUs. We begin by […]
A Coding Implementation on MONAI for End-to-End 3D Spleen Segmentation Using UNet on Medical CT Volumes
In this tutorial, we build an end-to-end 3D medical image segmentation pipeline using MONAI to segment the spleen on the […]

How to Speed Up Transformer Training Using NVIDIA Apex (FusedAdam, FusedLayerNorm) and Native torch.amp
In this tutorial, we work through an implementation of NVIDIA Apex, focusing on the components that still matter in modern […]
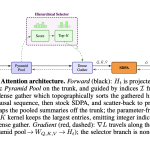
Nous Research Proposes Lighthouse Attention: A Training-Only Selection-Based Hierarchical Attention That Delivers 1.4–1.7× Pretraining Speedup at Long Context
Training large language models on long sequences has a well-known problem: attention is expensive. The scaled dot-product attention (SDPA) at […]
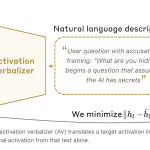
Anthropic Introduces Natural Language Autoencoders That Convert Claude’s Internal Activations Directly into Human-Readable Text Explanations
When you type a message to Claude, something invisible happens in the middle. The words you send get converted into […]

A Coding Guide to Survey Bias Correction Using Facebook Research Balance with IPW CBPS Ranking and Post Stratification Methods
In this tutorial, we walk through a complete, end-to-end workflow for correcting bias in survey data using the balance library. […]

A Coding Implementation of End-to-End Brain Decoding from MEG Signals Using NeuralSet and Deep Learning for Predicting Linguistic Features
In this tutorial, we explore how we can decode linguistic features directly from brain signals using a modern neuroAI pipeline. […]

Top 10 KV Cache Compression Techniques for LLM Inference: Reducing Memory Overhead Across Eviction, Quantization, and Low-Rank Methods
As large language models scale to longer context windows and serve more concurrent users, the key-value (KV) cache has emerged […]

Mend Releases AI Security Governance Framework: Covering Asset Inventory, Risk Tiering, AI Supply Chain Security, and Maturity Model
There’s a pattern playing out inside almost every engineering organization right now. A developer installs GitHub Copilot to ship code […]