
In this tutorial, we build a complete workflow for running Baidu’s Unlimited-OCR model on document images and multi-page PDFs. We […]
Category: Editors Pick

Andrew Ng Just Released OpenWorker: An Open-Source, Local-First Desktop AI Coworker That Returns Finished Deliverables Instead of Chat
Andrew Ng has announced OpenWorker, an open-source desktop agent that produces finished work rather than conversation. OpenWorker asks the user […]

You Didn’t Get the AI Model You Paid For
The line in the response object You call the API. You pass model: “claude-fable-5”. You get back a completion, a […]

Best Open Speech Recognition (ASR) Models in 2026: WER, Languages, Latency, and License Compared
Open speech recognition stopped being a Whisper monoculture some time in the last twelve months. In March 2026 Cohere released […]

Meet Gigatoken: A Rust BPE Tokenizer that Encodes Text at 24.53 GB/s, up to 989x Faster than HuggingFace Tokenizers
Tokenization is the one part of the language modeling stack that almost nobody profiles. Gigatoken, released by Marcel Rød (a […]

Anthropic Releases Claude Security Plugin for Claude Code in Beta: A Multi-Agent Vulnerability Scanner That Runs in Your Terminal
Anthropic has released the Claude Security plugin for Claude Code in beta. The plugin runs a multi-agent vulnerability scan of […]

Cursor Releases Cursor Router: A Request-Level Classifier Delivering Frontier Coding Quality at 30–50% Lower Cost
Cursor has made Cursor Router generally available for Teams and Enterprise plans. The system is a classifier that inspects each […]

Research-Grade EdgeBench Analysis: AI Agent Benchmarking, Leaderboard Analytics, Scaling Laws, and Evaluation Metrics
In this tutorial, we explore EdgeBench as a practical benchmark for evaluating advanced AI agents across diverse task categories, runtime […]
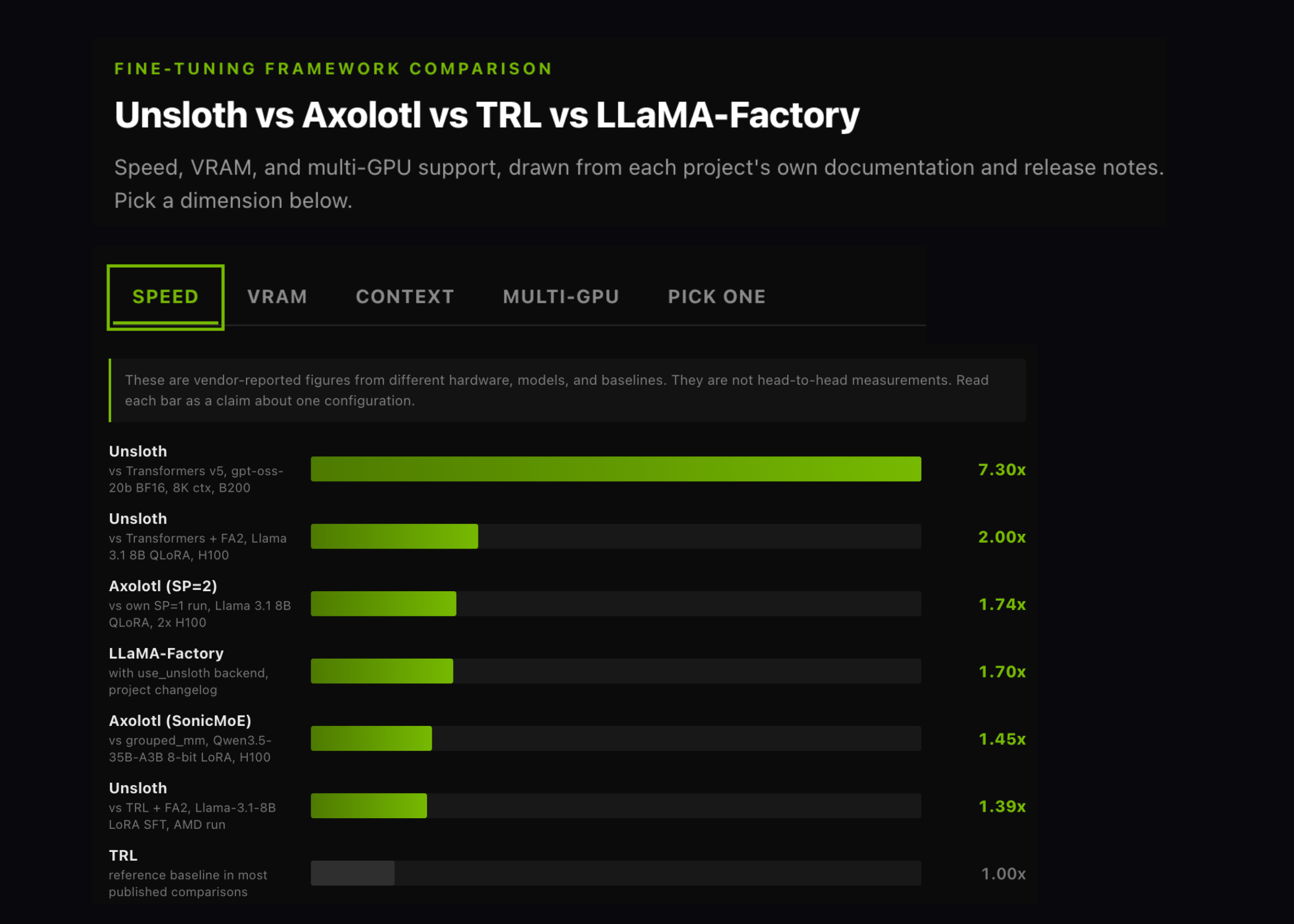
Unsloth vs Axolotl vs TRL vs LLaMA-Factory: A Fine-Tuning Framework Comparison on Speed, VRAM, and Multi-GPU
Four open source projects dominate LLM fine-tuning today. Unsloth, Axolotl, TRL, and LLaMA-Factory all wrap the same underlying PyTorch and […]

Cisco Foundation AI Releases Antares: 350M and 1B Open-Weight Models That Localize Known Vulnerabilities Inside Real Codebases
Cisco Foundation AI has released Antares, a family of security small language models (SLMs) built for one narrow security task. […]