
Backpropagation dominates deep learning, yet it uses a mechanism the brain likely cannot. Specifically, the backward pass needs exact transposes […]
Category: AI Paper Summary

Soofi Consortium Releases Soofi S 30B-A3B: An Open Hybrid Mamba-Transformer MoE Foundation Model For German And English
A German research consortium has published the pretraining report for Soofi S 30B-A3B. It is an open base model for […]

Skyfall AI Releases MORPHEUS: A Persistent Enterprise Simulation Benchmark That Makes Continual Reinforcement Learning Necessary Under Structured Non-Stationarity
Most reinforcement learning benchmarks reset the world after every episode. Real operations never reset. Skyfall AI’s MORPHEUS targets that gap. […]

Stanford Researchers Introduce TRACE: A Capability-Targeted Agentic Training System That Turns Recurrent Agent Failures Into Synthetic RL Environment
Agentic LLMs often fail the same way, again and again. A Stanford research team traced this to missing, reusable capabilities. […]

Meet NeuroVFM: A New Neuroimaging Foundation Model Trained With Vol-JEPA on Uncurated Clinical MRI and CT Volumes
Frontier models learn mostly from public internet data. However, clinical neuroimaging rarely appears there, because MRI and CT scans contain […]
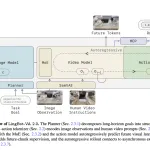
Ant Group’s Robbyant Unveils LingBot-VA 2.0: A Causal Video-Action Model Built Natively for Physical AI
Robbyant, the embodied AI unit inside Ant Group, has released the LingBot-VA 2.0.The first embodied-native foundation model. It describes a […]
Kyutai Releases MuScriptor: An Open-Weight Decoder-Only Transformer for Multi-Instrument Music Transcription to MIDI
Automatic Music Transcription (AMT) converts an audio recording into symbolic notes, usually MIDI. Single-instrument transcription already works reasonably well. However, […]

Google Research Introduces SensorFM: A Wearable Health Foundation Model Pretrained on One Trillion Minutes of Sensor Data
Most wearable health models are built one outcome at a time. That approach breaks down at thirty-five endpoints. Labels are […]
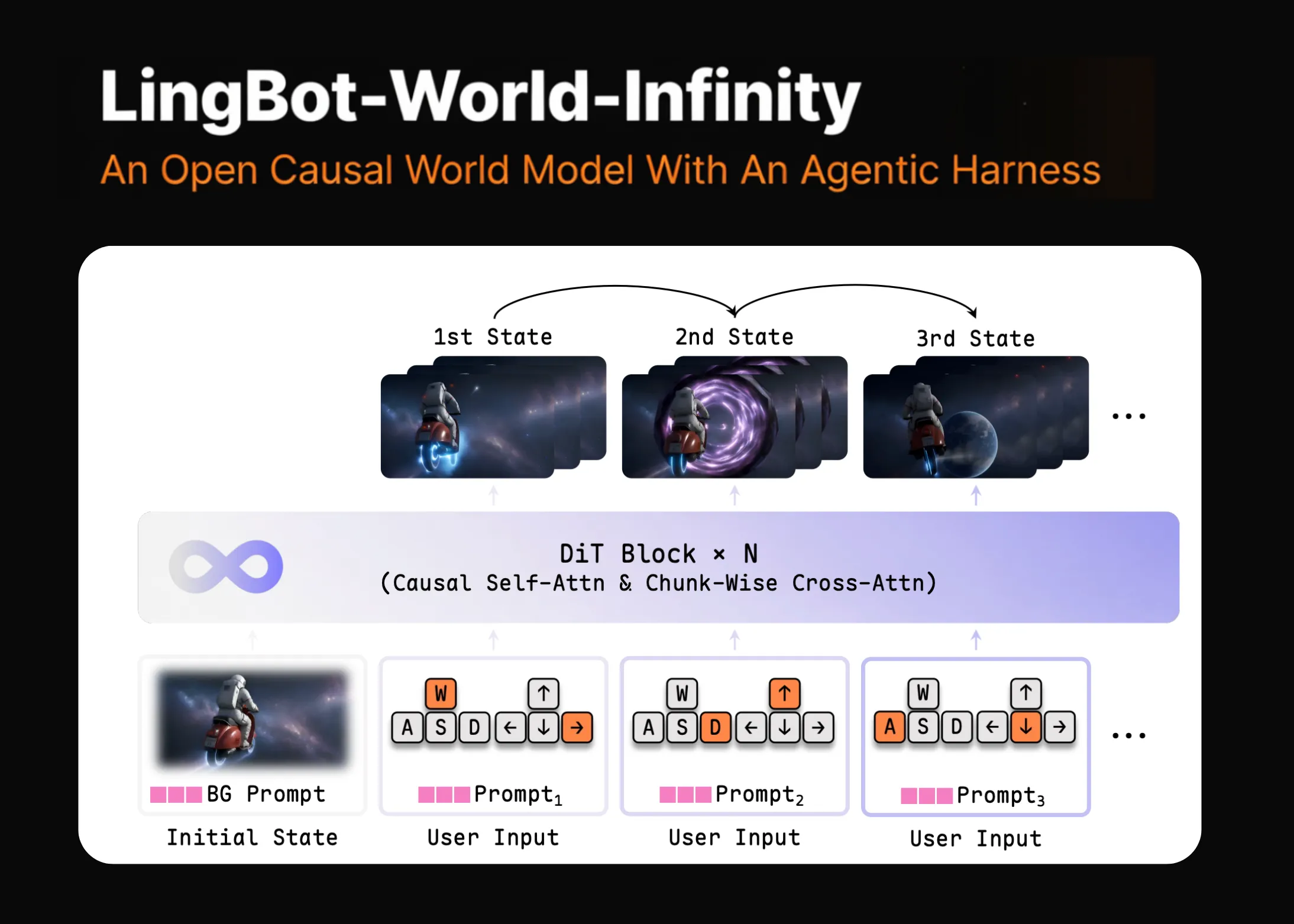
Meet LingBot-World-Infinity: An Open Causal World Model With An Agentic Harness
Robbyant, Ant Group’s embodied-intelligence unit, has released LingBot-World-Infinity (LingBot-World 2.0). It is a causal video generation model that behaves as […]
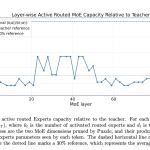
Meet Nemotron Labs 3 Puzzle 75B A9B: A Compressed Hybrid MoE LLM Delivering 2.03x Server Throughput
Large hybrid MoE models like Nemotron-3-Super are accurate but expensive to serve. Their active parameters, KV cache, and Mamba state […]