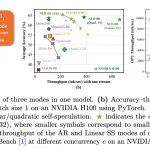
NVIDIA researchers have released Nemotron-Labs-Diffusion, a language model family that unifies three decoding modes in one architecture. The model supports […]
Category: AI Paper Summary
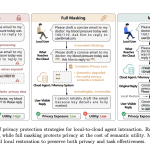
Meet MemPrivacy: An Edge-Cloud Framework that Uses Local Reversible Pseudonymization to Protect User Data Without Breaking Memory Utility
As LLM-powered agents move from research to production, one design tension is becoming harder to ignore: the more useful cloud-hosted […]

NVIDIA Introduces a 4-Bit Pretraining Methodology Using NVFP4, Validated on a 12B Hybrid Mamba-Transformer at 10T Token Horizon
Pretraining frontier-scale LLMs in FP8 is now standard practice, but moving to 4-bit floating point has remained an open research […]
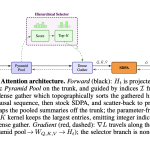
Nous Research Proposes Lighthouse Attention: A Training-Only Selection-Based Hierarchical Attention That Delivers 1.4–1.7× Pretraining Speedup at Long Context
Training large language models on long sequences has a well-known problem: attention is expensive. The scaled dot-product attention (SDPA) at […]
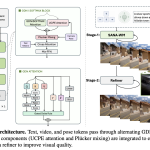
NVIDIA Introduces SANA-WM: A 2.6B-Parameter Open-Source World Model That Generates Minute-Scale 720p Video on a Single GPU
World models (systems that synthesize realistic video sequences from an initial image and a set of actions) are becoming central […]

Nous Research Releases Token Superposition Training to Speed Up LLM Pre-Training by Up to 2.5x Across 270M to 10B Parameter Models
Pre-training large language models is expensive enough that even modest efficiency improvements can translate into meaningful cost and time savings. […]
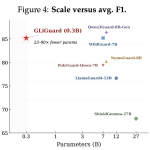
Fastino Labs Open-Sources GLiGuard: A 300M Parameter Safety Moderation Model That Matches or Exceeds Accuracy of Models 23–90x Its Size
As LLM-powered applications move into production — and as AI agents take on more consequential tasks like browsing the web, […]

Tilde Research Introduces Aurora: A Leverage-Aware Optimizer That Fixes a Hidden Neuron Death Problem in Muon
Researchers at Tilde Research have released Aurora, a new optimizer for training neural networks that addresses a structural flaw in […]
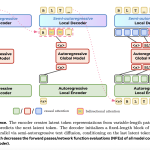
Meta and Stanford Researchers Propose Fast Byte Latent Transformer That Reduces Inference Memory Bandwidth by Over 50% Without Tokenization
A team of researchers from Meta, Stanford University, and the University of Washington have introduced three new methods that substantially […]
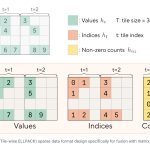
Sakana AI and NVIDIA Introduce TwELL with CUDA Kernels for 20.5% Inference and 21.9% Training Speedup in LLMs
Scaling large language models (LLMs) is expensive. Every token processed during inference and every gradient computed during training flows through […]