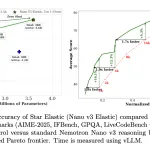
Training a family of large language models (LLMs) has always come with a painful multiplier: every model variant in the […]
Category: AI Paper Summary
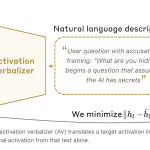
Anthropic Introduces Natural Language Autoencoders That Convert Claude’s Internal Activations Directly into Human-Readable Text Explanations
When you type a message to Claude, something invisible happens in the middle. The words you send get converted into […]
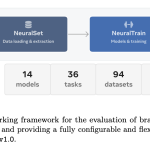
Meta AI Releases NeuralBench: A Unified Open-Source Framework to Benchmark NeuroAI Models Across 36 EEG Tasks and 94 Datasets
Evaluating AI models trained on brain signals has long been a messy, inconsistent topic. Different research groups use different preprocessing […]

OpenAI Introduces MRC (Multipath Reliable Connection): A New Open Networking Protocol for Large-Scale AI Supercomputer Training Clusters
Training frontier AI models is not just a compute problem — it is increasingly a networking problem. And OpenAI just […]
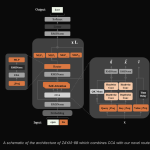
Zyphra Releases ZAYA1-8B: A Reasoning MoE Trained on AMD Hardware That Punches Far Above Its Weight Class
Zyphra AI has released ZAYA1-8B, a small Mixture of Experts (MoE) language model with 760 million active parameters and 8.4 […]
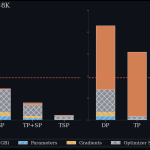
Zyphra Introduces Tensor and Sequence Parallelism (TSP): A Hardware-Aware Training and Inference Strategy That Delivers 2.6x Throughput Over Matched TP+SP Baselines
Training and serving large transformer models at scale is fundamentally a memory management problem. Every GPU in a cluster has […]

Sakana AI Introduces KAME: A Tandem Speech-to-Speech Architecture That Injects LLM Knowledge in Real Time
The fundamental tension in conversational AI has always been a binary choice: respond fast or respond smart. Real-time speech-to-speech (S2S) […]

A New NVIDIA Research Shows Speculative Decoding in NeMo RL Achieves 1.8× Rollout Generation Speedup at 8B and Projects 2.5× End-to-End Speedup at 235B
If you have been running reinforcement learning (RL) post-training on a language model for math reasoning, code generation, or any […]
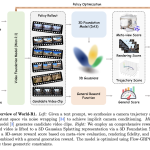
Microsoft Research’s World-R1 Uses Flow-GRPO and 3D-Aware Rewards to Inject Geometric Consistency Into Wan 2.1 Without Architectural Changes
Video foundation models can paint a beautiful frame. They are still notoriously bad at remembering it. Push the camera through […]
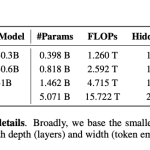
Meta AI Releases Sapiens2: A High-Resolution Human-Centric Vision Model for Pose, Segmentation, Normals, Pointmap, and Albedo
If you’ve ever watched a motion capture system struggle with a person’s fingers, or seen a segmentation model fail to […]