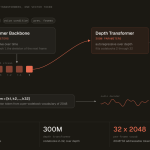
Miso Labs has released MisoTTS, an open-weights 8-billion-parameter text-to-speech model. It generates expressive speech from both text and audio context. […]
Category: TTS

Best Text-to-Speech TTS Models in 2026: A Benchmark-Based Comparison
Text-to-speech TTS moved fast over the past year. The line between synthetic and human speech narrowed. Latency dropped below 100 […]

Meet OmniVoice Studio: A Local, Open-Source Alternative to ElevenLabs
ElevenLabs charges between $5 and $330 per month for voice AI services. Every audio file you process goes through their […]
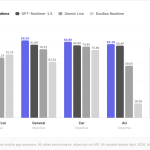
StepFun Releases StepAudio 2.5 Realtime: An End-to-End Voice Model with Roleplay-Specific RLHF and Paralinguistic Comprehension
StepFun, the Shanghai-based AI lab, released StepAudio 2.5 Realtime. It is an end-to-end real-time speech large language model with fully […]

IBM Releases Two Granite Speech 4.1 2B Models: Autoregressive ASR with Translation and Non-Autoregressive Editing for Fast Inference
IBM released two new open speech recognition models— Granite Speech 4.1 2B and Granite Speech 4.1 2B-NAR — and they […]
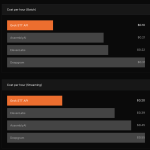
xAI Launches Standalone Grok Speech-to-Text and Text-to-Speech APIs, Targeting Enterprise Voice Developers
Elon Musk’s AI company xAI has launched two standalone audio APIs — a Speech-to-Text (STT) API and a Text-to-Speech (TTS) […]

Google AI Launches Gemini 3.1 Flash TTS: A New Benchmark in Expressive and Controllable AI Voice
Google has introduced Gemini 3.1 Flash TTS, a preview text-to-speech model focused on improving speech quality, expressive control, and multilingual […]

A Hands-On Coding Tutorial for Microsoft VibeVoice Covering Speaker-Aware ASR, Real-Time TTS, and Speech-to-Speech Pipelines
In this tutorial, we explore Microsoft VibeVoice in Colab and build a complete hands-on workflow for both speech recognition and […]
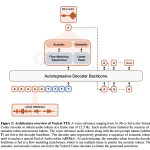
Mistral AI Releases Voxtral TTS: A 4B Open-Weight Streaming Speech Model for Low-Latency Multilingual Voice Generation
Mistral AI has released Voxtral TTS, an open-weight text-to-speech model that marks the company’s first major move into audio generation. […]
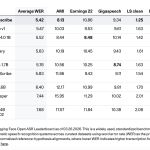
Cohere AI Releases Cohere Transcribe: A SOTA Automatic Speech Recognition (ASR) Model Powering Enterprise Speech Intelligence
In the landscape of enterprise AI, the bridge between unstructured audio and actionable text has often been a bottleneck of […]