
Text-to-speech TTS moved fast over the past year. The line between synthetic and human speech narrowed. Latency dropped below 100 […]
Category: Text to Audio
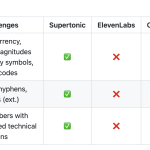
Supertone Releases Supertonic v3: On-Device Text-to-Speech Model with 31-Language Support, Fewer Reading Failures, and Expression Tags
Supertone released Supertonic 3, the third generation of its on-device, ONNX-based text-to-speech system. Supertonic 3 ships with 31-language support, improved […]
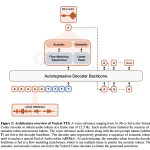
Mistral AI Releases Voxtral TTS: A 4B Open-Weight Streaming Speech Model for Low-Latency Multilingual Voice Generation
Mistral AI has released Voxtral TTS, an open-weight text-to-speech model that marks the company’s first major move into audio generation. […]

Google DeepMind Releases Lyria 3: An Advanced Music Generation AI Model that Turns Photos and Text into Custom Tracks with Included Lyrics and Vocals
Google DeepMind is pushing the boundaries of generative AI again. This time, the focus is not on text or images. […]