
Google just announced Gemini 3.5 Live Translate. It is their latest audio model for live speech-to-speech translation. Speech-to-speech means spoken […]
Category: Audio Language Model

Microsoft AI Introduces MAI-Transcribe-1.5: 2.4% WER on Artificial Analysis, Best-in-Class FLEURS Accuracy, and Up to 5x Faster Long-Audio Transcription
Last week Microsoft AI has announced MAI-Transcribe-1.5. It is the second iteration of the company’s in-house speech-to-text family. The model […]
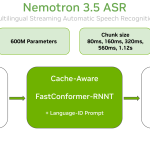
NVIDIA Releases Nemotron 3.5 ASR: A 600M-Parameter Cache-Aware Streaming Model Transcribing 40 Language-Locales in Real Time
NVIDIA’s Nemotron Speech team has released Nemotron 3.5 ASR. It is a 600M-parameter streaming Automatic Speech Recognition (ASR) model. A […]
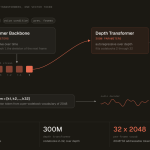
Miso Labs Releases MisoTTS: An 8B Emotive Text-to-Speech Model with Open Weights
Miso Labs has released MisoTTS, an open-weights 8-billion-parameter text-to-speech model. It generates expressive speech from both text and audio context. […]

Best Text-to-Speech TTS Models in 2026: A Benchmark-Based Comparison
Text-to-speech TTS moved fast over the past year. The line between synthetic and human speech narrowed. Latency dropped below 100 […]
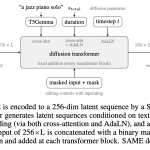
Stability AI Releases Stable Audio 3: A Family of Fast Latent Diffusion Models for Audio Generation and Editing
Stability AI has released open weights for Stable Audio 3 along with a technical research paper. Stable Audio 3 is […]

Meet OmniVoice Studio: A Local, Open-Source Alternative to ElevenLabs
ElevenLabs charges between $5 and $330 per month for voice AI services. Every audio file you process goes through their […]
StepFun Releases StepAudio 2.5 Realtime: An End-to-End Voice Model with Roleplay-Specific RLHF and Paralinguistic Comprehension
StepFun, the Shanghai-based AI lab, released StepAudio 2.5 Realtime. It is an end-to-end real-time speech large language model with fully […]
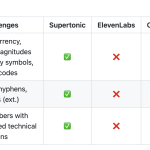
Supertone Releases Supertonic v3: On-Device Text-to-Speech Model with 31-Language Support, Fewer Reading Failures, and Expression Tags
Supertone released Supertonic 3, the third generation of its on-device, ONNX-based text-to-speech system. Supertonic 3 ships with 31-language support, improved […]

OpenAI Releases Three Realtime Audio Models: GPT-Realtime-2, GPT-Realtime-Translate, and GPT-Realtime-Whisper in the Realtime API
OpenAI released three new audio models through its Realtime API, each targeting a distinct capability in live voice applications: GPT-Realtime-2 […]