Video foundation models can paint a beautiful frame. They are still notoriously bad at remembering it. Push the camera through […]
Category: Computer Vision

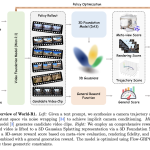
How to Build a Lightweight Vision-Language-Action-Inspired Embodied Agent with Latent World Modeling and Model Predictive Control
In this tutorial, we build an embodied simulation vision agent that learns to perceive, plan, predict, and replan directly from […]
Meta AI Releases Sapiens2: A High-Resolution Human-Centric Vision Model for Pose, Segmentation, Normals, Pointmap, and Albedo
If you’ve ever watched a motion capture system struggle with a person’s fingers, or seen a segmentation model fail to […]

Google DeepMind Introduces Vision Banana: An Instruction-Tuned Image Generator That Beats SAM 3 on Segmentation and Depth Anything V3 on Metric Depth Estimation
For years, the computer vision community has operated on two separate tracks: generative models (which produce images) and discriminative models […]

Qwen Team Open-Sources Qwen3.6-35B-A3B: A Sparse MoE Vision-Language Model with 3B Active Parameters and Agentic Coding Capabilities
The open-source AI landscape has a new entry worth paying attention to. The Qwen team at Alibaba has released Qwen3.6-35B-A3B, […]

Google DeepMind Releases Gemini Robotics-ER 1.6: Bringing Enhanced Embodied Reasoning and Instrument Reading to Physical AI
Google DeepMind research team introduced Gemini Robotics-ER 1.6, a significant upgrade to its embodied reasoning model designed to serve as […]
A Coding Implementation of MolmoAct for Depth-Aware Spatial Reasoning, Visual Trajectory Tracing, and Robotic Action Prediction
In this tutorial, we walk through MolmoAct step by step and build a practical understanding of how action-reasoning models can […]

Liquid AI Releases LFM2.5-VL-450M: a 450M-Parameter Vision-Language Model with Bounding Box Prediction, Multilingual Support, and Sub-250ms Edge Inference
Liquid AI just released LFM2.5-VL-450M, an updated version of its earlier LFM2-VL-450M vision-language model. The new release introduces bounding box […]

A Coding Guide to Markerless 3D Human Kinematics with Pose2Sim, RTMPose, and OpenSim
In this tutorial, we build and run a complete Pose2Sim pipeline on Colab to understand how markerless 3D kinematics works […]
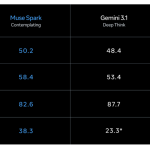
Meta Superintelligence Lab Releases Muse Spark: A Multimodal Reasoning Model With Thought Compression and Parallel Agents
Meta Superintelligence Labs recently made a significant move by unveiling ‘Muse Spark’ — the first model in the Muse family. […]