
The open-source AI landscape has a new entry worth paying attention to. The Qwen team at Alibaba has released Qwen3.6-35B-A3B, […]
Category: Computer Vision

Google DeepMind Releases Gemini Robotics-ER 1.6: Bringing Enhanced Embodied Reasoning and Instrument Reading to Physical AI
Google DeepMind research team introduced Gemini Robotics-ER 1.6, a significant upgrade to its embodied reasoning model designed to serve as […]
A Coding Implementation of MolmoAct for Depth-Aware Spatial Reasoning, Visual Trajectory Tracing, and Robotic Action Prediction
In this tutorial, we walk through MolmoAct step by step and build a practical understanding of how action-reasoning models can […]

Liquid AI Releases LFM2.5-VL-450M: a 450M-Parameter Vision-Language Model with Bounding Box Prediction, Multilingual Support, and Sub-250ms Edge Inference
Liquid AI just released LFM2.5-VL-450M, an updated version of its earlier LFM2-VL-450M vision-language model. The new release introduces bounding box […]

A Coding Guide to Markerless 3D Human Kinematics with Pose2Sim, RTMPose, and OpenSim
In this tutorial, we build and run a complete Pose2Sim pipeline on Colab to understand how markerless 3D kinematics works […]
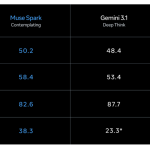
Meta Superintelligence Lab Releases Muse Spark: A Multimodal Reasoning Model With Thought Compression and Parallel Agents
Meta Superintelligence Labs recently made a significant move by unveiling ‘Muse Spark’ — the first model in the Muse family. […]

Meta AI Releases EUPE: A Compact Vision Encoder Family Under 100M Parameters That Rivals Specialist Models Across Image Understanding, Dense Prediction, and VLM Tasks
Running powerful AI on your smartphone isn’t just a hardware problem — it’s a model architecture problem. Most state-of-the-art vision […]
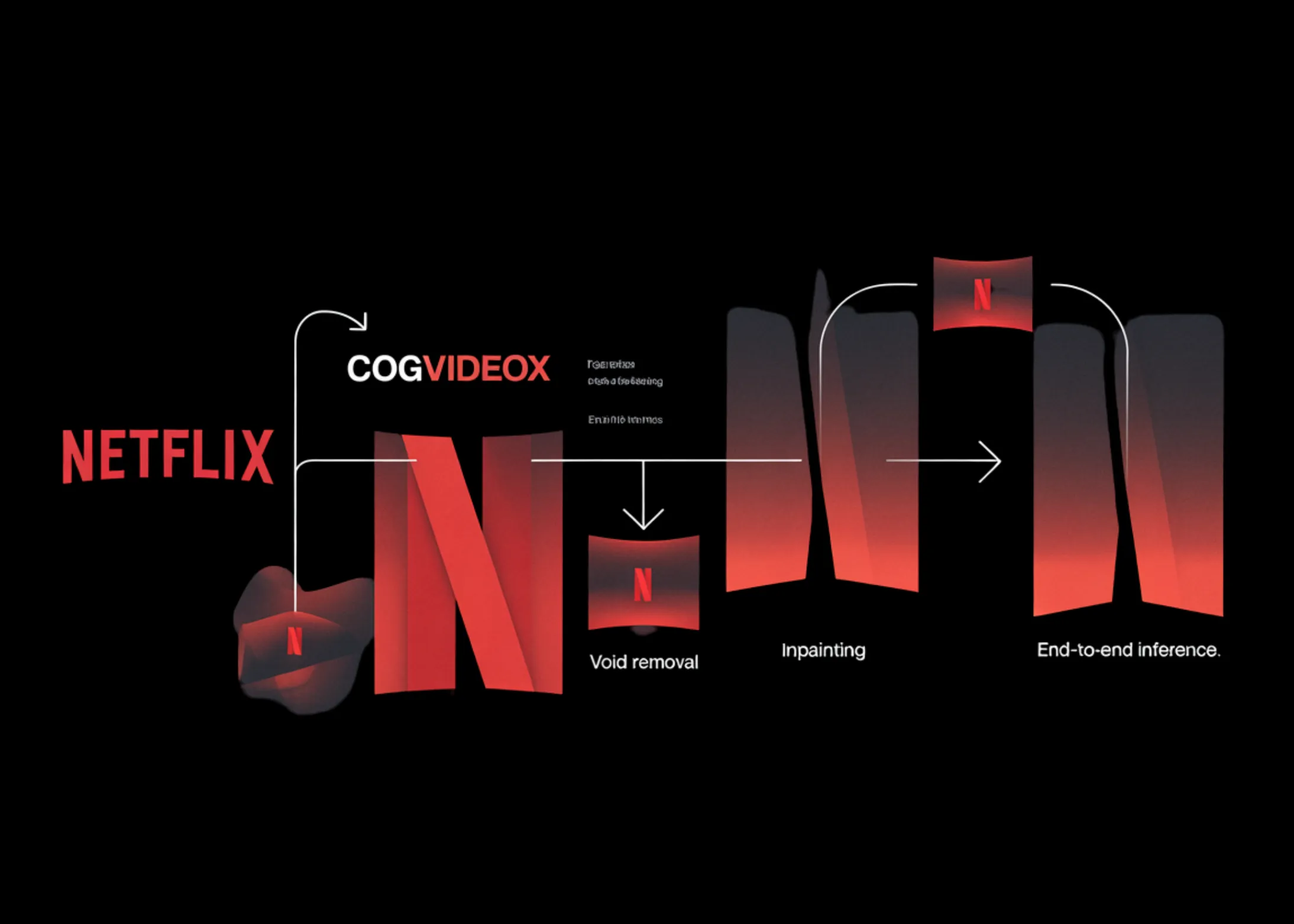
How to Build a Netflix VOID Video Object Removal and Inpainting Pipeline with CogVideoX, Custom Prompting, and End-to-End Sample Inference
In this tutorial, we build and run an advanced pipeline for Netflix’s VOID model. We set up the environment, install […]

Netflix AI Team Just Open-Sourced VOID: an AI Model That Erases Objects From Videos — Physics and All
Video editing has always had a dirty secret: removing an object from footage is easy; making the scene look like […]

TII Releases Falcon Perception: A 0.6B-Parameter Early-Fusion Transformer for Open-Vocabulary Grounding and Segmentation from Natural Language Prompts
In the current landscape of computer vision, the standard operating procedure involves a modular ‘Lego-brick’ approach: a pre-trained vision encoder […]