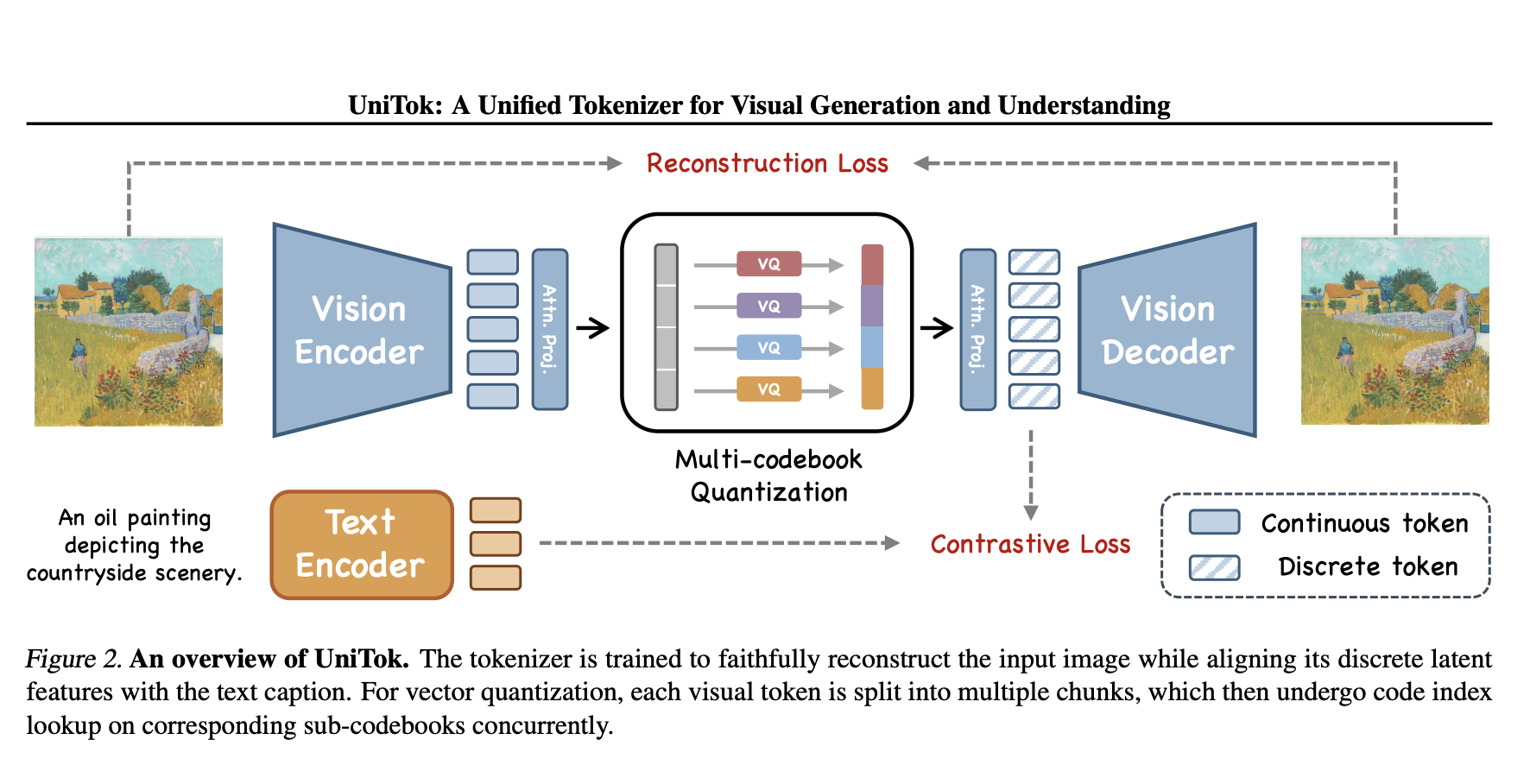
With researchers aiming to unify visual generation and understanding into a single framework, multimodal artificial intelligence is evolving rapidly. Traditionally, […]
Category: Computer Vision

Simplifying Self-Supervised Vision: How Coding Rate Regularization Transforms DINO & DINOv2
Learning useful features from large amounts of unlabeled images is important, and models like DINO and DINOv2 are designed for […]
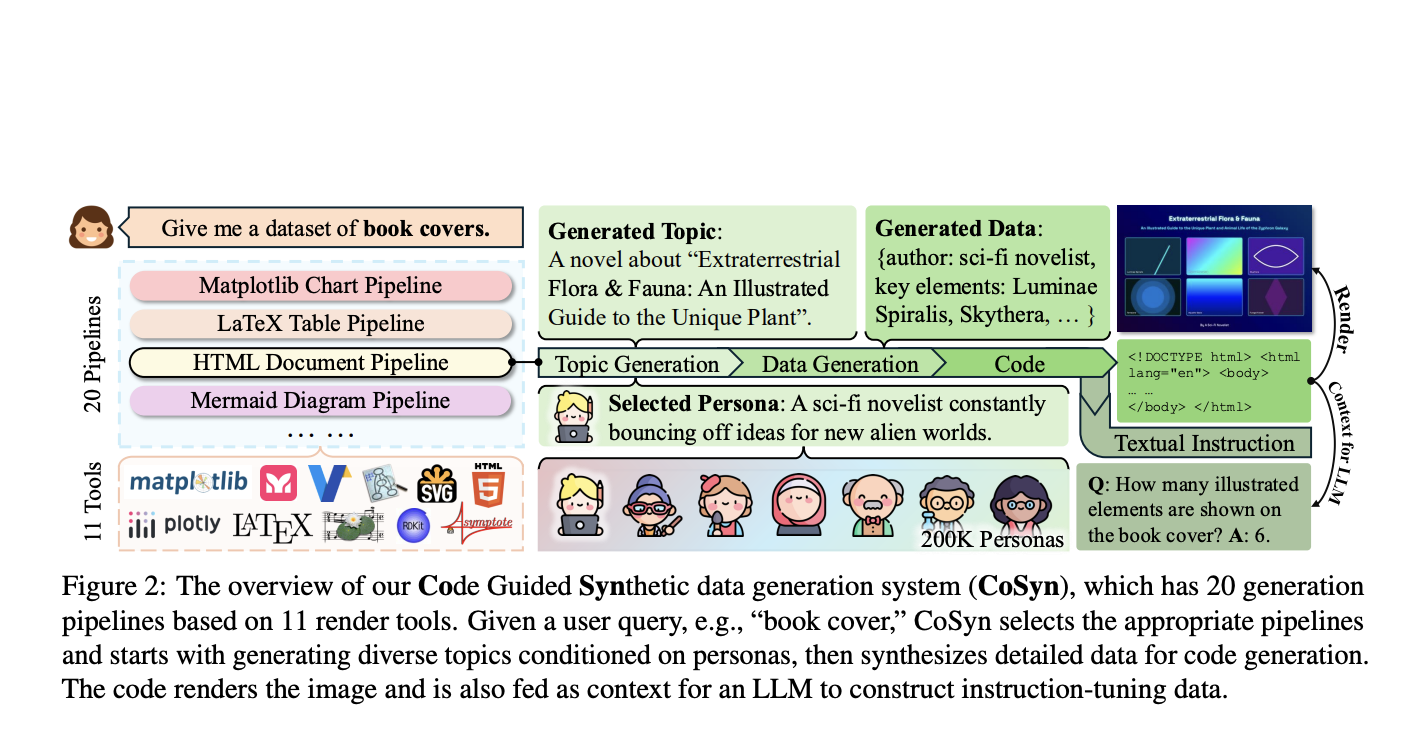
CoSyn: An AI Framework that Leverages the Coding Capabilities of Text-only Large Language Models (LLMs) to Automatically Create Synthetic Text-Rich Multimodal Data
Vision-language models (VLMs) have demonstrated impressive capabilities in general image understanding, but face significant challenges when processing text-rich visual content […]
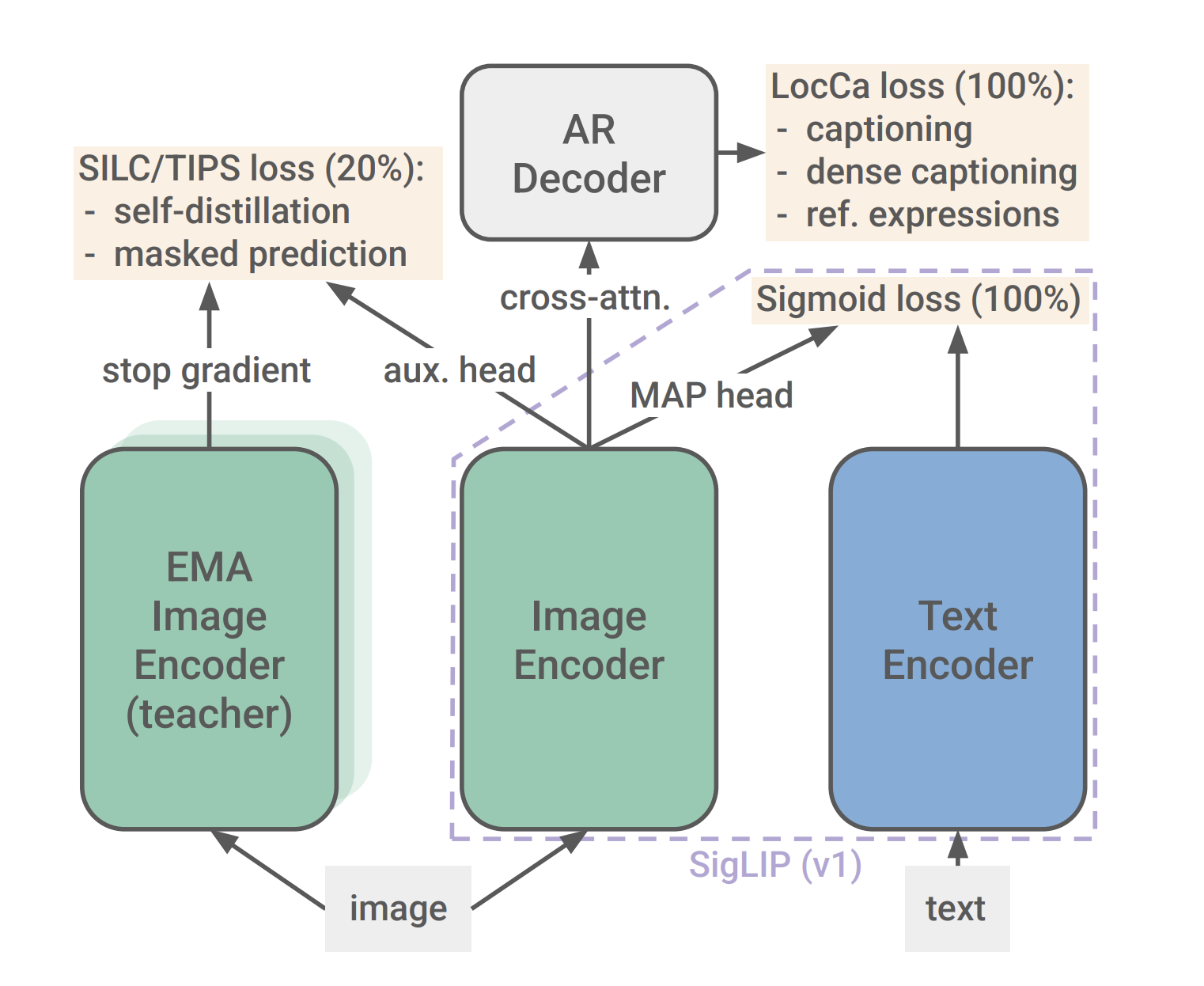
Google DeepMind Research Releases SigLIP2: A Family of New Multilingual Vision-Language Encoders with Improved Semantic Understanding, Localization, and Dense Features
Modern vision-language models have transformed how we process visual data, yet they often fall short when it comes to fine-grained […]

Microsoft Researchers Present Magma: A Multimodal AI Model Integrating Vision, Language, and Action for Advanced Robotics, UI Navigation, and Intelligent Decision-Making
Multimodal AI agents are designed to process and integrate various data types, such as images, text, and videos, to perform […]
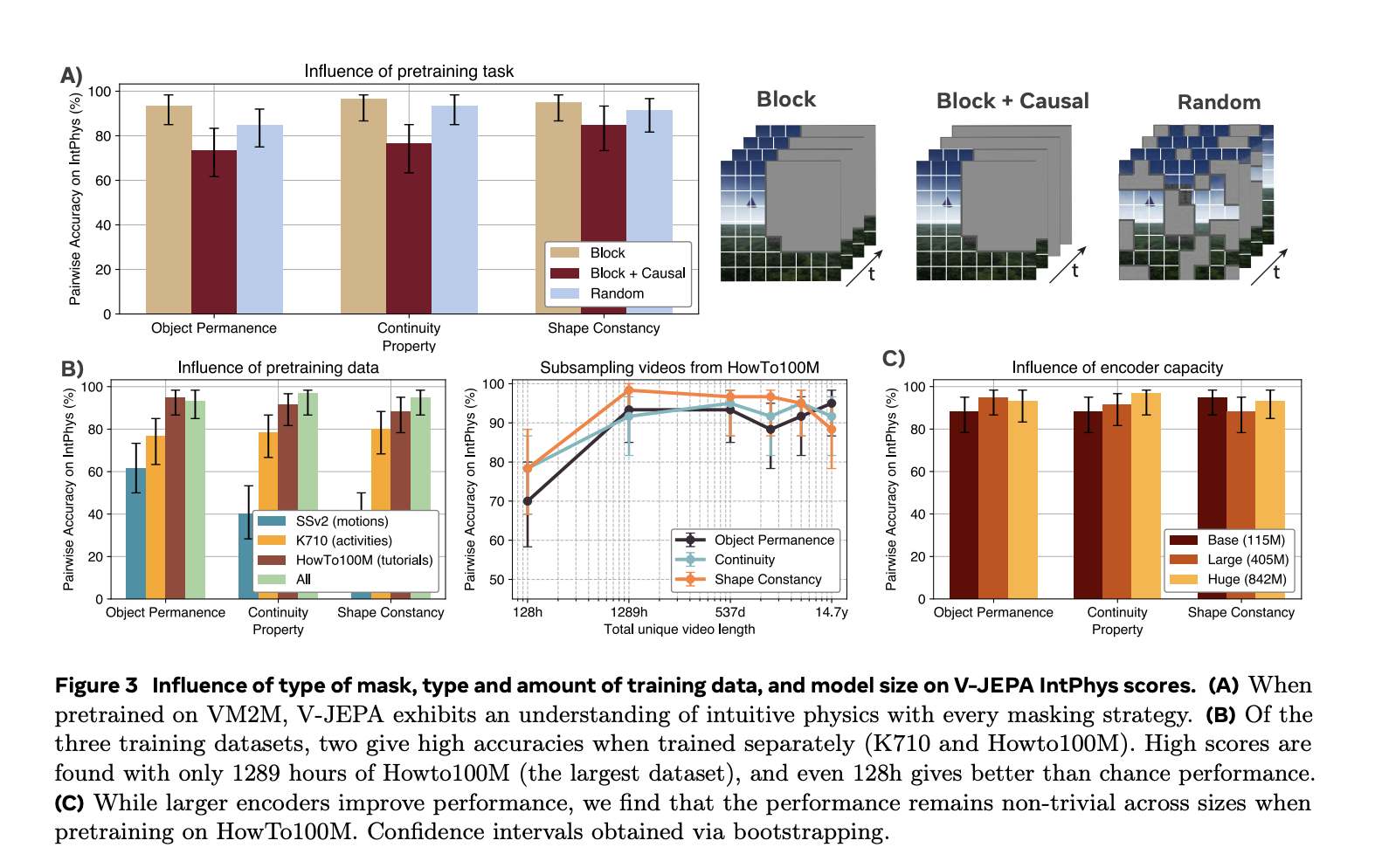
Learning Intuitive Physics: Advancing AI Through Predictive Representation Models
Humans possess an innate understanding of physics, expecting objects to behave predictably without abrupt changes in position, shape, or color. […]
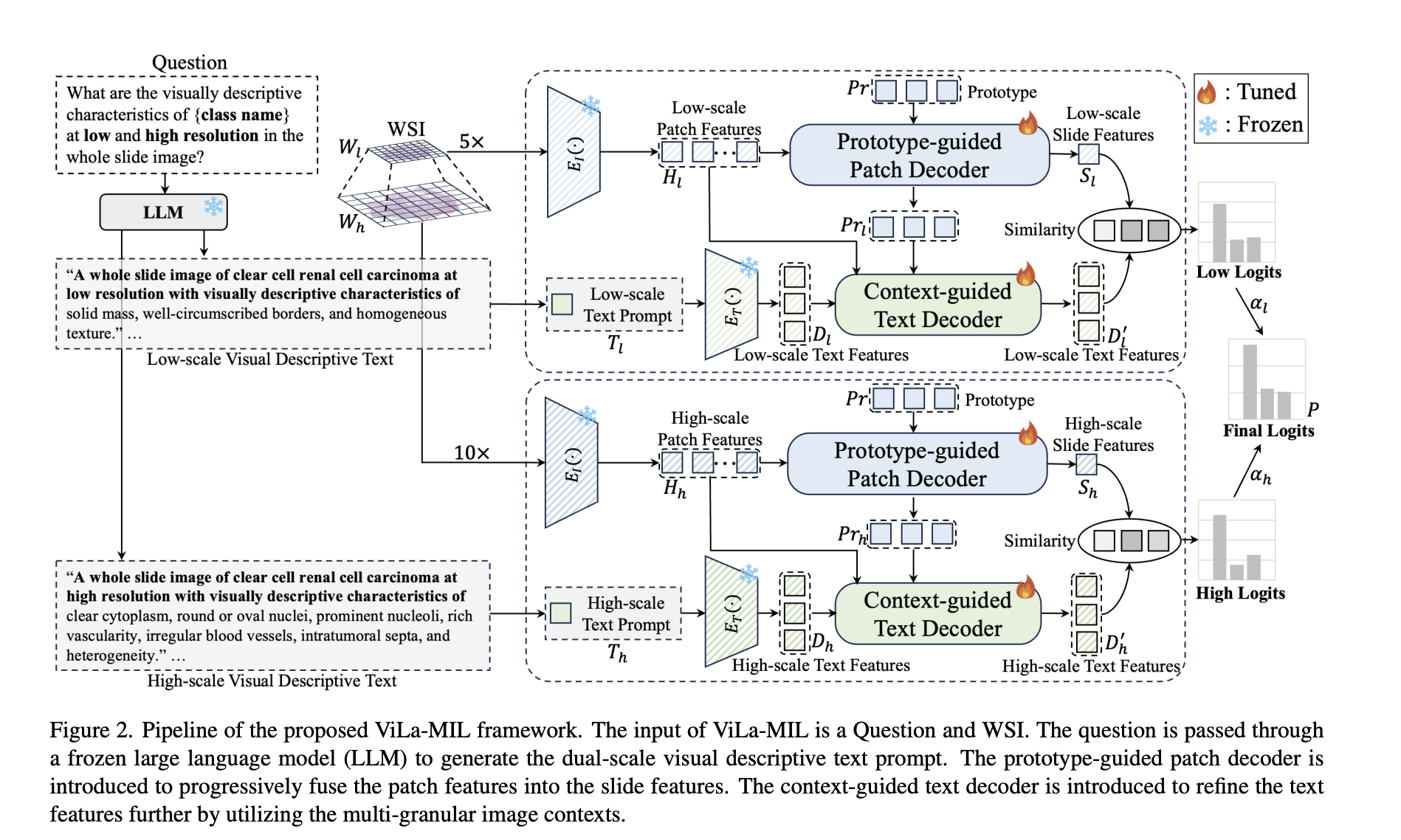
ViLa-MIL: Enhancing Whole Slide Image Classification with Dual-Scale Vision-Language Multiple Instance Learning
Whole Slide Image (WSI) classification in digital pathology presents several critical challenges due to the immense size and hierarchical nature […]

Ola: A State-of-the-Art Omni-Modal Understanding Model with Advanced Progressive Modality Alignment Strategy
Understanding different data types like text, images, videos, and audio in one model is a big challenge. Large language models […]
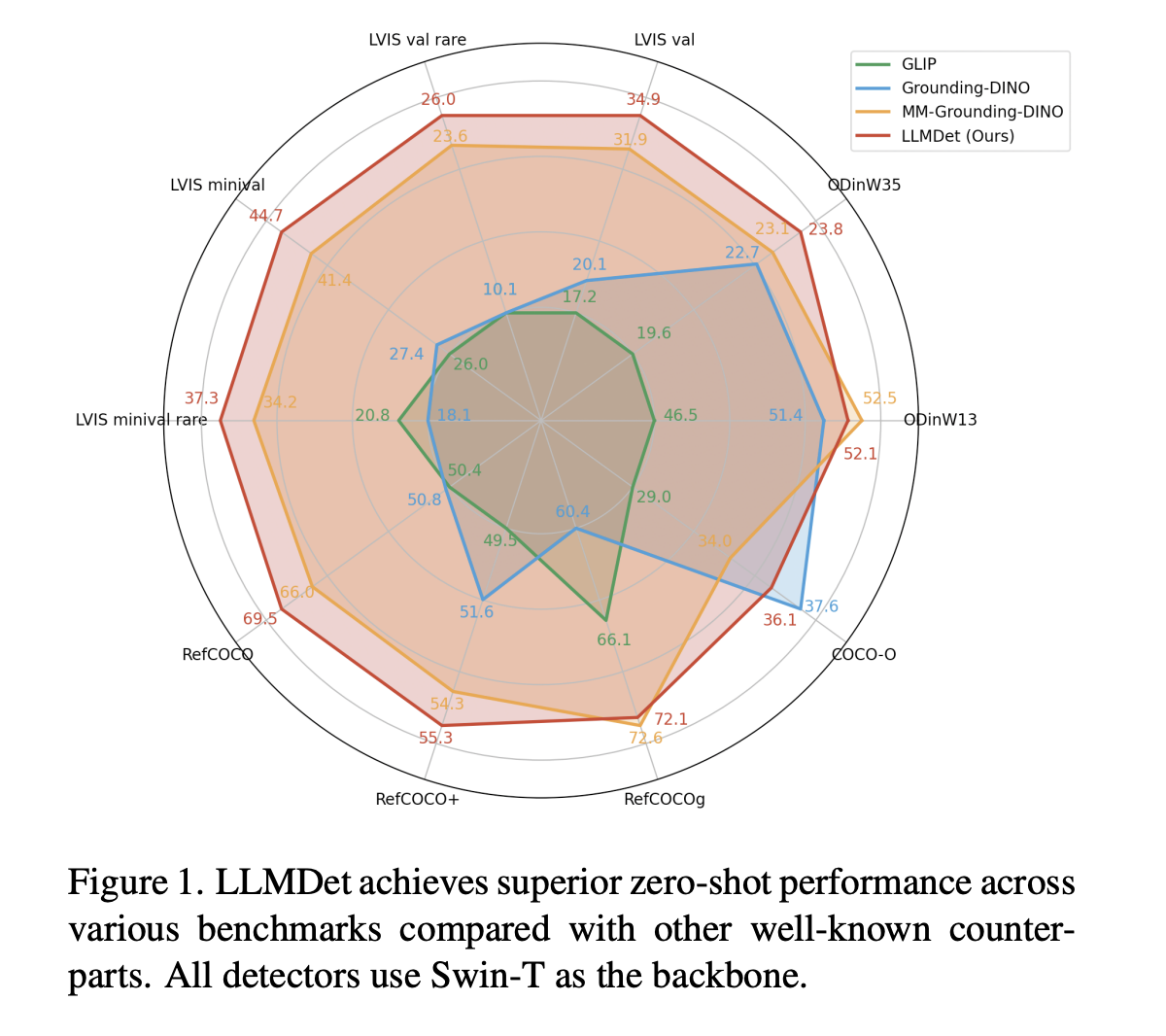
LLMDet: How Large Language Models Enhance Open-Vocabulary Object Detection
Open-vocabulary object detection (OVD) aims to detect arbitrary objects with user-provided text labels. Although recent progress has enhanced zero-shot detection […]
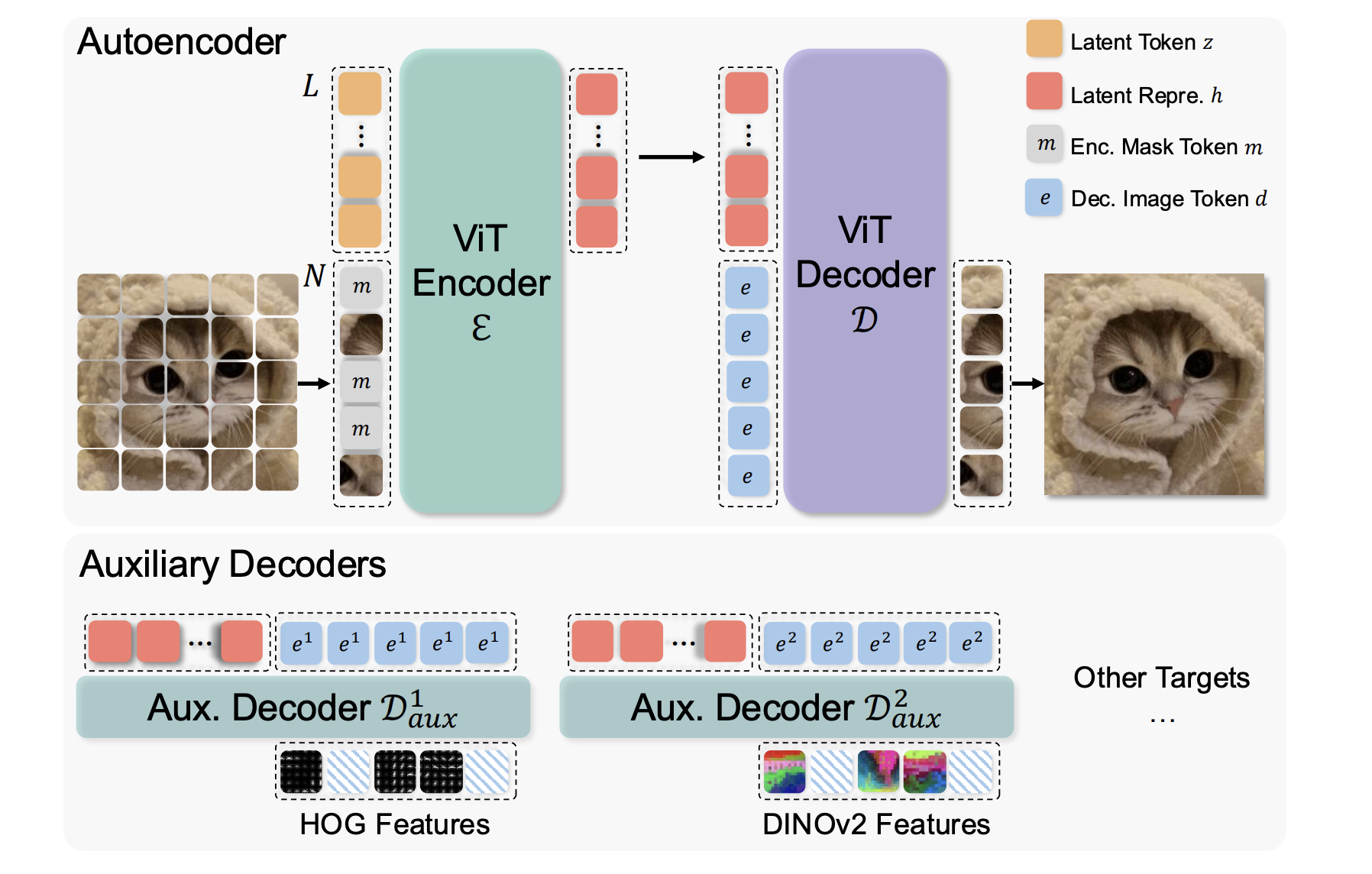
This AI Paper Introduces MAETok: A Masked Autoencoder-Based Tokenizer for Efficient Diffusion Models
Diffusion models generate images by progressively refining noise into structured representations. However, the computational cost associated with these models remains […]