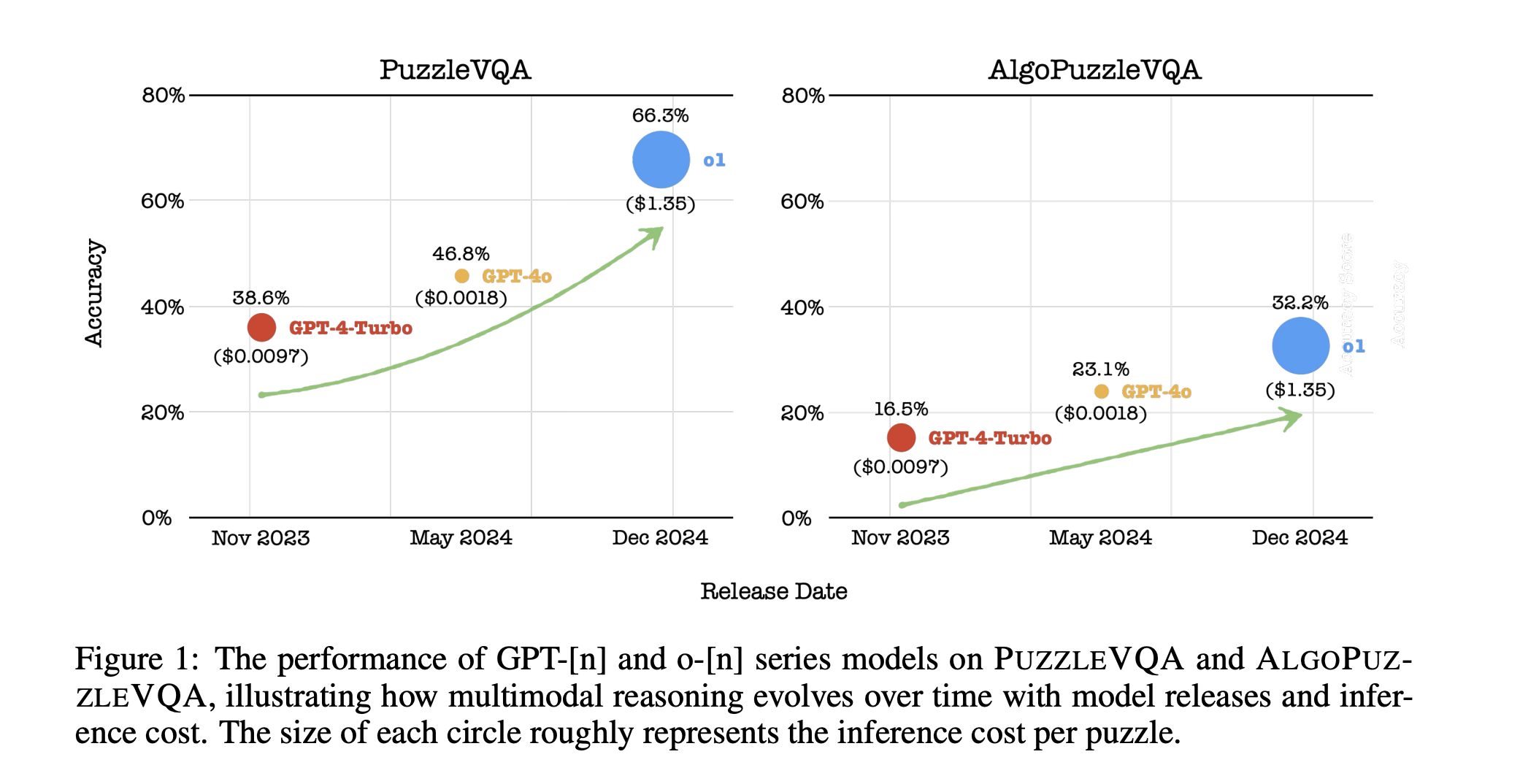
After the success of large language models (LLMs), the current research extends beyond text-based understanding to multimodal reasoning tasks. These […]
Category: Computer Vision
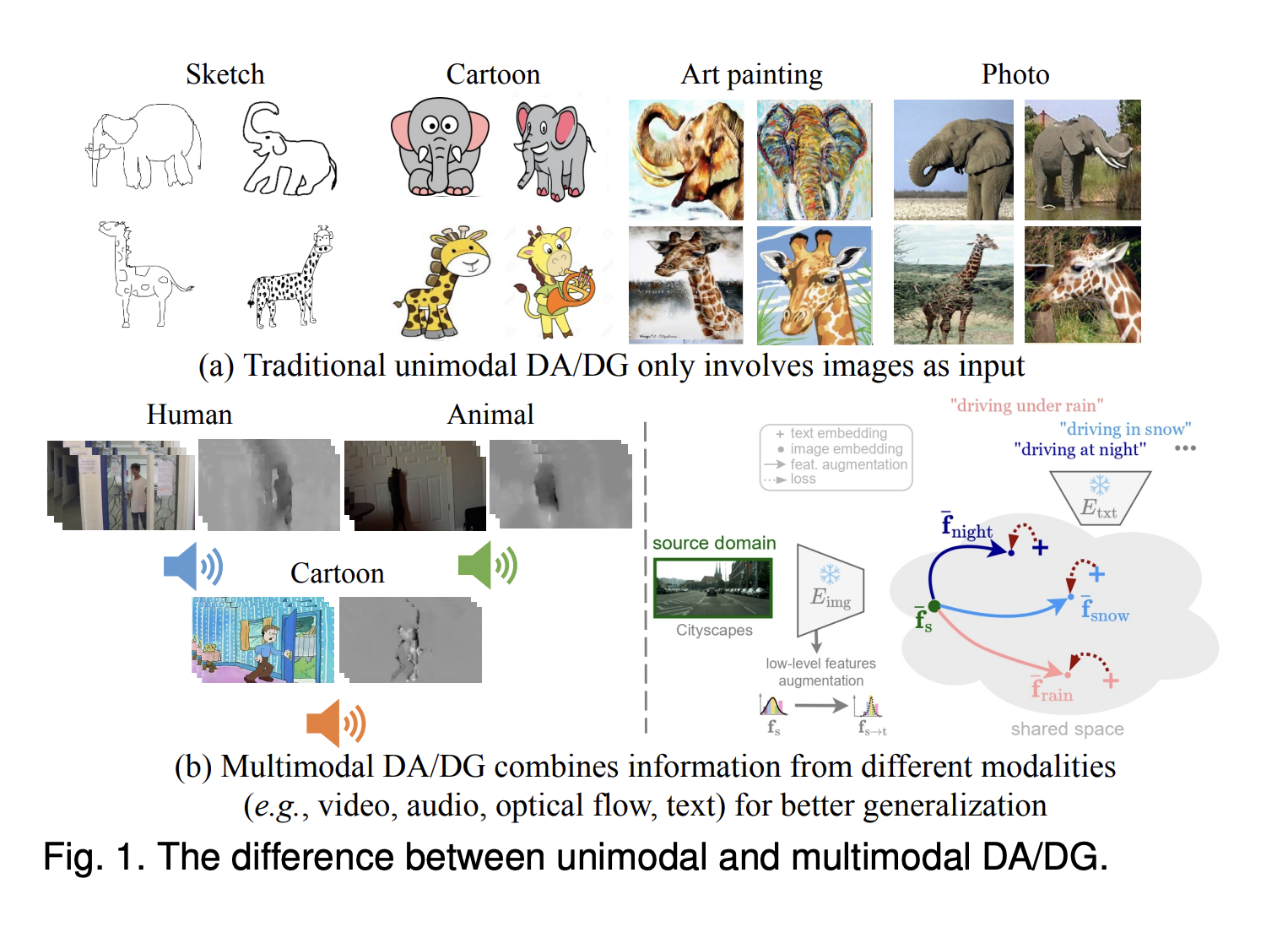
Researchers from ETH Zurich and TUM Share Everything You Need to Know About Multimodal AI Adaptation and Generalization
There is no gainsaying that artificial intelligence has developed tremendously in various fields. However, the accurate evaluation of its progress […]

Meta AI Introduces MILS: A Training-Free Multimodal AI Framework for Zero-Shot Image, Video, and Audio Understanding
Large Language Models (LLMs) are primarily designed for text-based tasks, limiting their ability to interpret and generate multimodal content such […]

Meta AI Introduces VideoJAM: A Novel AI Framework that Enhances Motion Coherence in AI-Generated Videos
Despite recent advancements, generative video models still struggle to represent motion realistically. Many existing models focus primarily on pixel-level reconstruction, […]
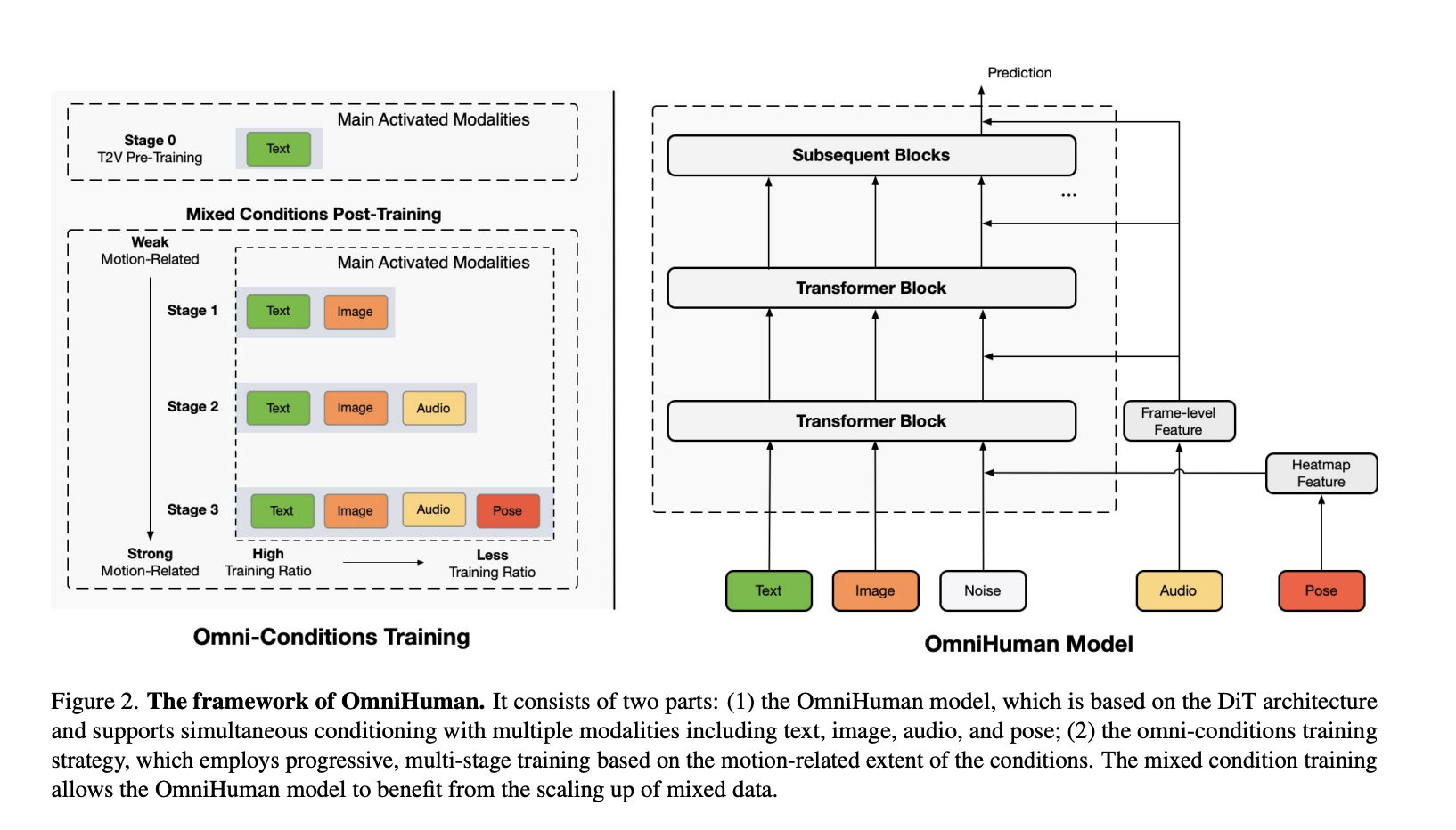
ByteDance Proposes OmniHuman-1: An End-to-End Multimodality Framework Generating Human Videos based on a Single Human Image and Motion Signals
Despite progress in AI-driven human animation, existing models often face limitations in motion realism, adaptability, and scalability. Many models struggle […]
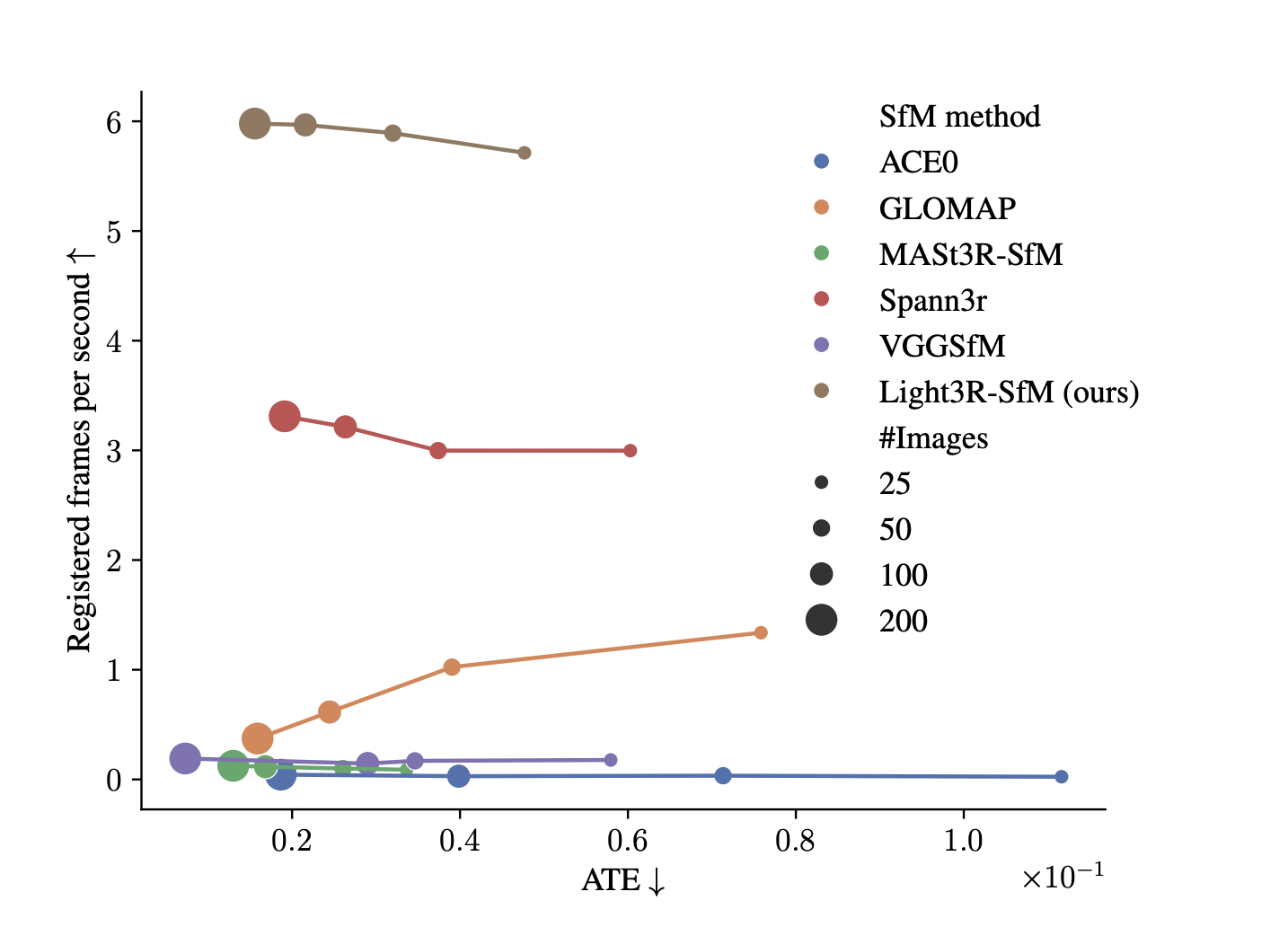
Light3R-SfM: A Scalable and Efficient Feed-Forward Approach to Structure-from-Motion
Structure-from-motion (SfM) focuses on recovering camera positions and building 3D scenes from multiple images. This process is important for tasks […]

InternVideo2.5: Hierarchical Token Compression and Task Preference Optimization for Video MLLMs
Multimodal large language models (MLLMs) have emerged as a promising approach towards artificial general intelligence, integrating diverse sensing signals into […]

This AI Paper Introduces IXC-2.5-Reward: A Multi-Modal Reward Model for Enhanced LVLM Alignment and Performance
Artificial intelligence has grown significantly with the integration of vision and language, allowing systems to interpret and generate information across […]

Netflix Introduces Go-with-the-Flow: Motion-Controllable Video Diffusion Models Using Real-Time Warped Noise
Generative modeling challenges in motion-controllable video generation present significant research hurdles. Current approaches in video generation struggle with precise motion […]
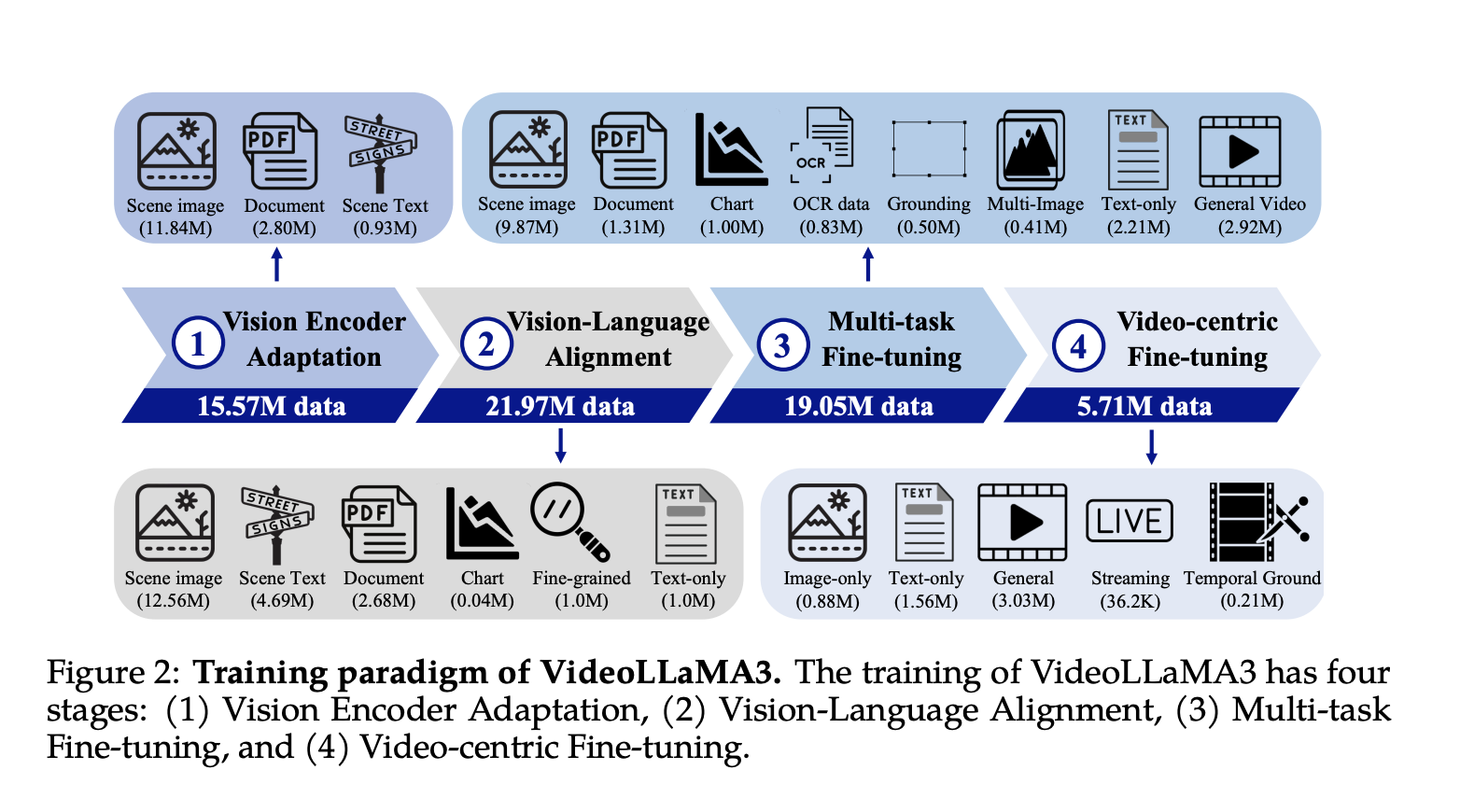
Alibaba Researchers Propose VideoLLaMA 3: An Advanced Multimodal Foundation Model for Image and Video Understanding
Advancements in multimodal intelligence depend on processing and understanding images and videos. Images can reveal static scenes by providing information […]