
Musk has also apparently used the Grok chatbots as an automated extension of his trolling habits, showing examples of Grok […]
Category: Multimodal AI

ReVisual-R1: An Open-Source 7B Multimodal Large Language Model (MLLMs) that Achieves Long, Accurate and Thoughtful Reasoning
The Challenge of Multimodal Reasoning Recent breakthroughs in text-based language models, such as DeepSeek-R1, have demonstrated that RL can aid […]

Google Researchers Advance Diagnostic AI: AMIE Now Matches or Outperforms Primary Care Physicians Using Multimodal Reasoning with Gemini 2.0 Flash
LLMs have shown impressive promise in conducting diagnostic conversations, particularly through text-based interactions. However, their evaluation and application have largely […]

Multimodal AI on Developer GPUs: Alibaba Releases Qwen2.5-Omni-3B with 50% Lower VRAM Usage and Nearly-7B Model Performance
Multimodal foundation models have shown substantial promise in enabling systems that can reason across text, images, audio, and video. However, […]

OpenAI’s new AI image generator is potent and bound to provoke
The visual apocalypse is probably nigh, but perhaps seeing was never believing. A trio of AI-generated images created using OpenAI’s […]

Farewell Photoshop? Google’s new AI lets you edit images by asking
Multimodal output opens up new possibilities Having true multimodal output opens up interesting new possibilities in chatbots. For example, Gemini […]
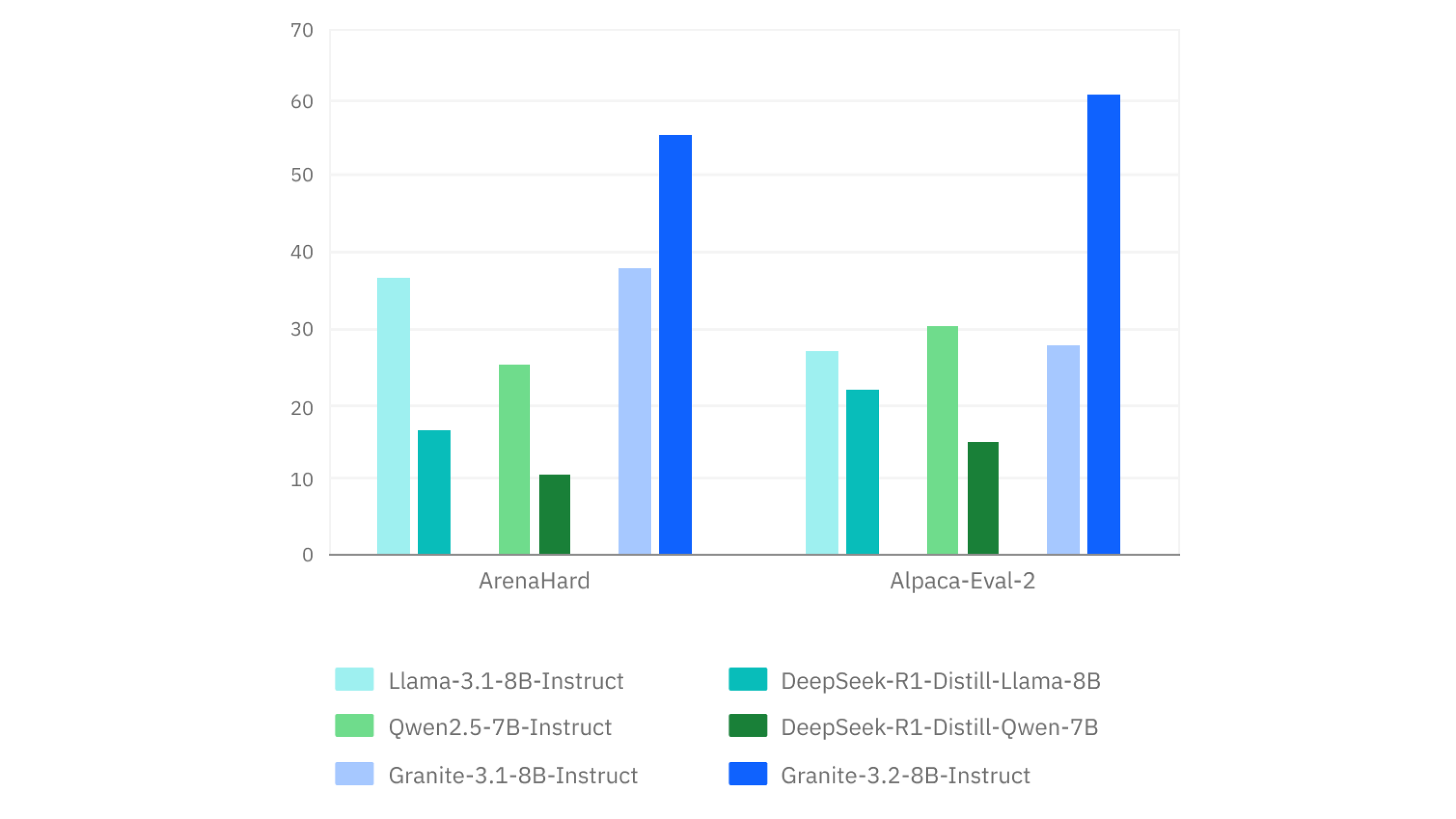
IBM AI Releases Granite 3.2 8B Instruct and Granite 3.2 2B Instruct Models: Offering Experimental Chain-of-Thought Reasoning Capabilities
Large language models (LLMs) leverage deep learning techniques to understand and generate human-like text, making them invaluable for various applications […]

Microsoft’s new AI agent can control software and robots
The researchers’ explanations about how “Set-of-Mark” and “Trace-of-Mark” work. Credit: Microsoft Research The Magma model introduces two technical components: Set-of-Mark, […]

Google DeepMind Releases PaliGemma 2 Mix: New Instruction Vision Language Models Fine-Tuned on a Mix of Vision Language Tasks
Vision‐language models (VLMs) have long promised to bridge the gap between image understanding and natural language processing. Yet, practical challenges […]
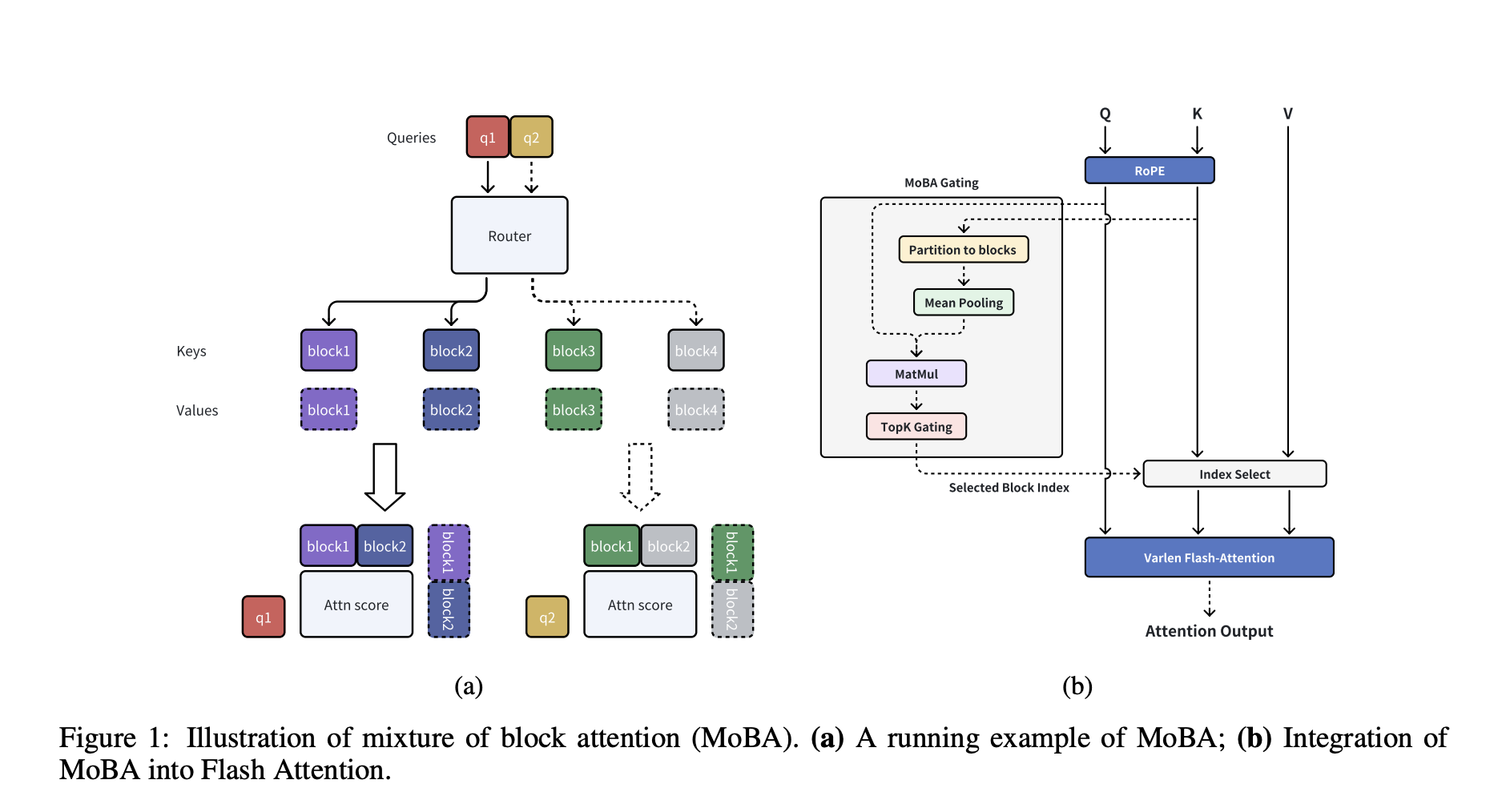
Moonshot AI Research Introduce Mixture of Block Attention (MoBA): A New AI Approach that Applies the Principles of Mixture of Experts (MoE) to the Attention Mechanism
Efficiently handling long contexts has been a longstanding challenge in natural language processing. As large language models expand their capacity […]