
Foundation models keep getting stronger, yet they still stall on the same thing: context. A model can write code or […]
Category: Context Engineering
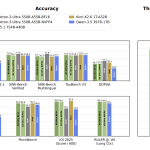
NVIDIA AI Releases Nemotron 3 Ultra: An Open 550B Mixture-of-Experts Hybrid Mamba-Transformer for Long-Running Agents
NVIDIA has released Nemotron 3 Ultra, the largest model in its Nemotron 3 family. It targets a specific problem: long-running […]
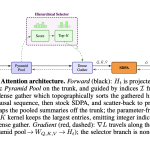
Nous Research Proposes Lighthouse Attention: A Training-Only Selection-Based Hierarchical Attention That Delivers 1.4–1.7× Pretraining Speedup at Long Context
Training large language models on long sequences has a well-known problem: attention is expensive. The scaled dot-product attention (SDPA) at […]

A Coding Implementation to Build Agent-Native Memory Infrastructure with Memori for Persistent Multi-User and Multi-Session LLM Applications
In this tutorial, we implement how Memori serves as an agent-native memory infrastructure layer for building more persistent, context-aware LLM […]
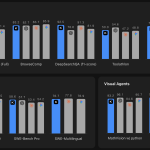
Moonshot AI Releases Kimi K2.6 with Long-Horizon Coding, Agent Swarm Scaling to 300 Sub-Agents and 4,000 Coordinated Steps
Moonshot AI, the Chinese AI lab behind the Kimi assistant, today open-sourced Kimi K2.6 — a native multimodal agentic model […]

How to Build Multi-Layered LLM Safety Filters to Defend Against Adaptive, Paraphrased, and Adversarial Prompt Attacks
In this tutorial, we build a robust, multi-layered safety filter designed to defend large language models against adaptive and paraphrased […]
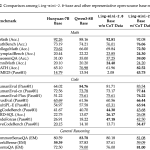
Ant Group Releases Ling 2.0: A Reasoning-First MoE Language Model Series Built on the Principle that Each Activation Enhances Reasoning Capability
How do you build a language model that grows in capacity but keeps the computation for each token almost unchanged? The […]

A Guide for Effective Context Engineering for AI Agents
Anthropic recently released a guide on effective Context Engineering for AI Agents — a reminder that context is a critical […]

Building a Context-Folding LLM Agent for Long-Horizon Reasoning with Memory Compression and Tool Use
In this tutorial, we explore how to build a Context-Folding LLM Agent that efficiently solves long, complex tasks by intelligently […]
Case Studies: Real-World Applications of Context Engineering
Context engineering has become a transformative force in moving from experimental AI demos to robust, production-grade systems across various industries. […]