Alibaba’s Qwen Team has released Qwen3.6-27B, the first dense open-weight model in the Qwen3.6 family — and arguably the most capable 27-billion-parameter model available today for coding agents. It brings substantial improvements in agentic coding, a novel Thinking Preservation mechanism, and a hybrid architecture that blends Gated DeltaNet linear attention with traditional self-attention — all under an Apache 2.0 license.
The release comes weeks after the Qwen3.6-35B-A3B, a sparse Mixture-of-Experts (MoE) model with only 3B active parameters which itself followed the broader Qwen3.5 series. Qwen3.6-27B is the family’s second model and the first fully dense variant — and on several key benchmarks, it actually outperforms both Qwen3.6-35B-A3B and the much larger Qwen3.5-397B-A17B MoE model. The Qwen team describes the release as prioritizing “stability and real-world utility,” shaped by direct community feedback rather than benchmark optimization.
The Qwen team releases two weight variants on Hugging Face Hub: Qwen/Qwen3.6-27B in BF16 and Qwen/Qwen3.6-27B-FP8, a quantized version using fine-grained FP8 quantization with a block size of 128, with performance metrics nearly identical to the original model. Both variants are compatible with SGLang (>=0.5.10), vLLM (>=0.19.0), KTransformers, and Hugging Face Transformers.
What’s New: Two Key Features
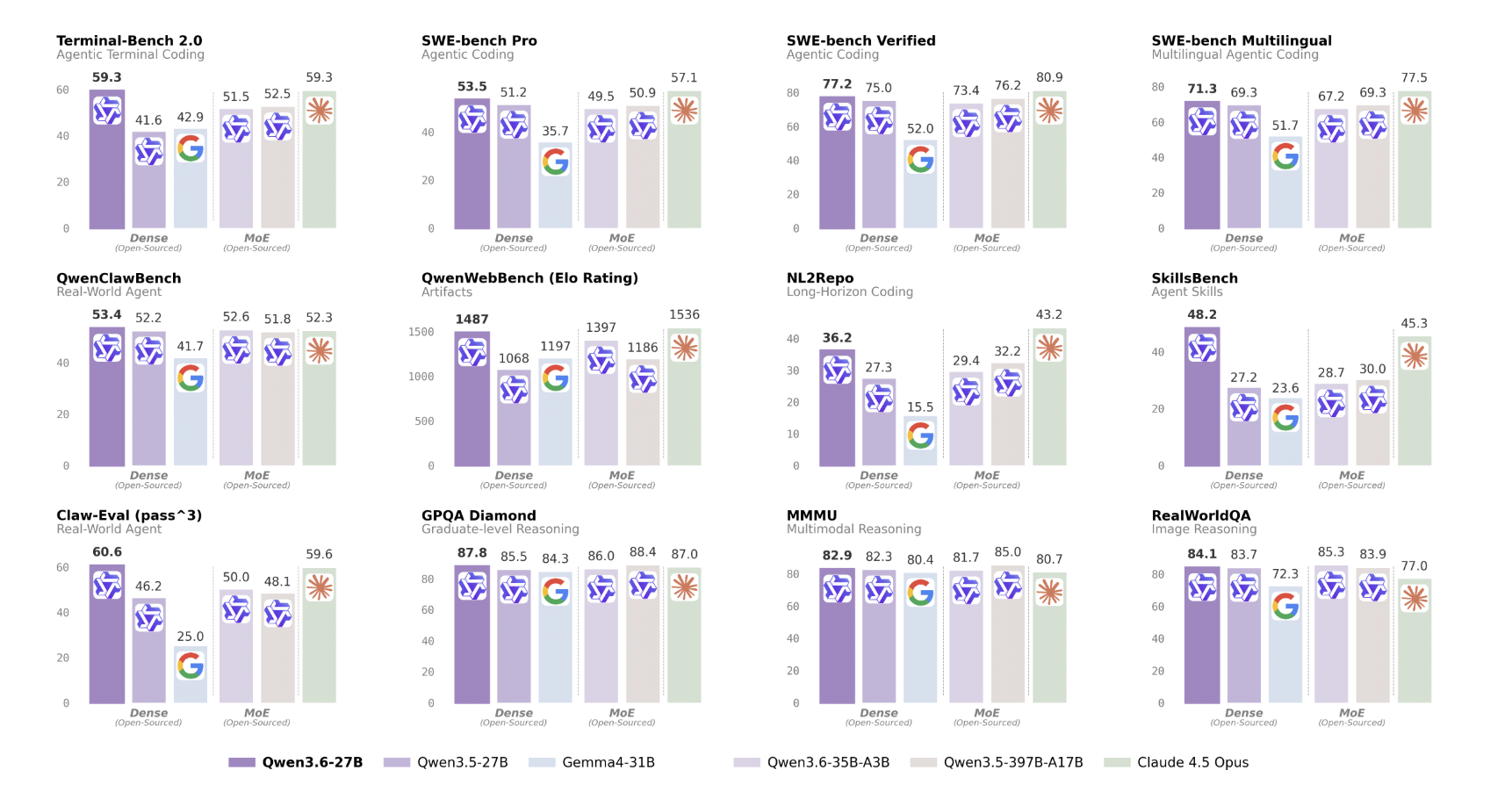
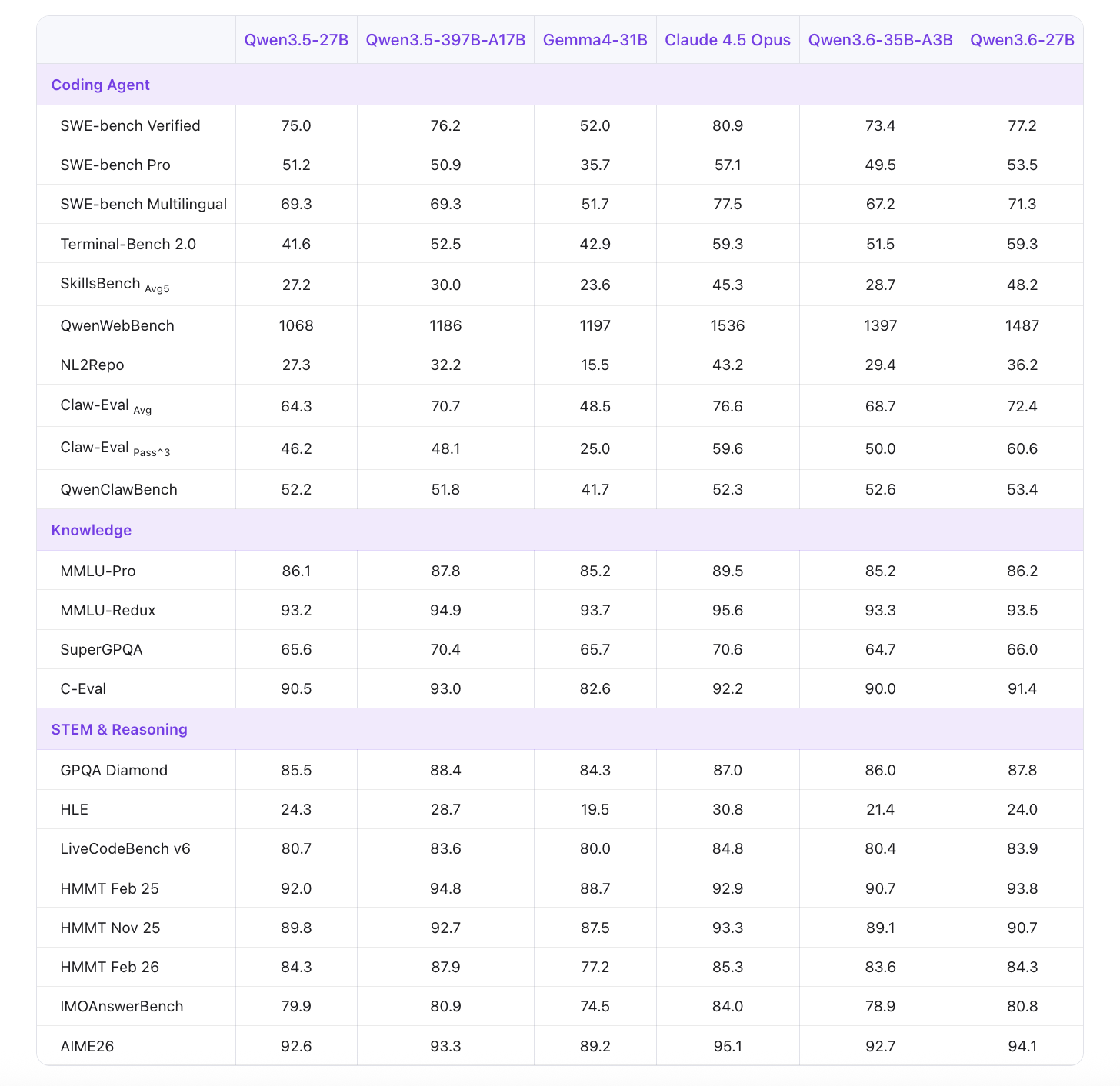
Agentic Coding is the first major upgrade. The model has been specifically optimized to handle frontend workflows and repository-level reasoning — tasks that require understanding a large codebase, navigating file structures, editing across multiple files, and producing consistent, runnable output. On QwenWebBench, an internal bilingual (EN/CN) front-end code generation benchmark spanning seven categories — Web Design, Web Apps, Games, SVG, Data Visualization, Animation, and 3D — Qwen3.6-27B scores 1487, a significant jump from 1068 for Qwen3.5-27B and 1397 for Qwen3.6-35B-A3B. On NL2Repo, which tests repository-level code generation, the model scores 36.2 versus 27.3 for Qwen3.5-27B. On SWE-bench Verified — the community standard for autonomous software engineering agents — it reaches 77.2, up from 75.0, and competitive with Claude 4.5 Opus’s 80.9.
Thinking Preservation is the second, and arguably more architecturally interesting, addition. By default, most LLMs only retain the chain-of-thought (CoT) reasoning generated for the current user message; reasoning from earlier turns is discarded. Qwen3.6 introduces a new option — enabled via "chat_template_kwargs": {"preserve_thinking": True} in the API — to retain and leverage thinking traces from historical messages across the entire conversation. For iterative agent workflows, this is practically significant: the model carries forward previous reasoning context rather than re-deriving it each turn. This can reduce overall token consumption by minimizing redundant reasoning and also improve KV cache utilization.
Under the Hood: A Hybrid Architecture
Qwen3.6-27B is a Causal Language Model with a Vision Encoder. It is natively multimodal, supporting text, image, and video inputs — trained through both pre-training and post-training stages.
The model has 27B parameters distributed across 64 layers, with a hidden dimension of 5120 and a token embedding space of 248,320 (padded). The hidden layout follows a distinctive repeating pattern: 16 blocks, each structured as 3 × (Gated DeltaNet → FFN) → 1 × (Gated Attention → FFN). This means three out of every four sublayers use Gated DeltaNet — a form of linear attention — with only every fourth sublayer using standard Gated Attention.
What is Gated DeltaNet? Traditional self-attention computes relationships between every token pair, which scales quadratically (O(n²)) with sequence length — expensive for long contexts. Linear attention mechanisms like DeltaNet approximate this with linear complexity (O(n)), making them significantly faster and more memory-efficient. Gated DeltaNet adds a gating mechanism on top, essentially learning when to update or retain information, similar in spirit to LSTM gating but applied to the attention computation. In Qwen3.6-27B, Gated DeltaNet sublayers use 48 linear attention heads for values (V) and 16 for queries and keys (QK), with a head dimension of 128.
The Gated Attention sublayers use 24 attention heads for queries (Q) and only 4 for keys and values (KV) — a configuration that significantly reduces KV cache memory at inference time. These layers have a head dimension of 256 and use Rotary Position Embedding (RoPE) with a rotation dimension of 64. The FFN intermediate dimension is 17,408.
The model also uses Multi-Token Prediction (MTP), trained with multi-steps. At inference time, this enables speculative decoding — where the model generates multiple candidate tokens simultaneously and verifies them in parallel — improving throughput without compromising quality.
Context Window: 262K Native, 1M with YaRN
Natively, Qwen3.6-27B supports a context length of 262,144 tokens — enough to hold a large codebase or a book-length document. For tasks exceeding this, the model supports YaRN (Yet another RoPE extension) scaling, extensible up to 1,010,000 tokens. The Qwen team advises keeping context at least 128K tokens to preserve the model’s thinking capabilities.
Benchmark Performance
On agentic coding benchmarks, the gains over Qwen3.5-27B are substantial. SWE-bench Pro scores 53.5 versus 51.2 for Qwen3.5-27B and 50.9 for the much larger Qwen3.5-397B-A17B — meaning the 27B dense model exceeds a 397B MoE on this task. SWE-bench Multilingual scores 71.3 versus 69.3 for Qwen3.5-27B. Terminal-Bench 2.0, evaluated under a 3-hour timeout with 32 CPUs and 48 GB RAM, reaches 59.3 — matching Claude 4.5 Opus exactly, and outperforming Qwen3.6-35B-A3B (51.5). SkillsBench Avg5 shows the most striking gain: 48.2 versus 27.2 for Qwen3.5-27B, a 77% relative improvement, also well above Qwen3.6-35B-A3B’s 28.7.
On reasoning benchmarks, GPQA Diamond reaches 87.8 (up from 85.5), AIME26 hits 94.1 (up from 92.6), and LiveCodeBench v6 scores 83.9 (up from 80.7).
Vision-language benchmarks show consistent parity or improvement over Qwen3.5-27B. VideoMME (with subtitles) reaches 87.7, AndroidWorld (visual agent benchmark) scores 70.3, and VlmsAreBlind — which probes for common visual understanding failure modes — scores 97.0.
Key Takeaways
- Qwen3.6-27B is Alibaba’s first dense open-weight model in the Qwen3.6 family, built to prioritize real-world coding utility over benchmark performance — licensed under Apache 2.0.
- The model introduces Thinking Preservation, a new feature that retains reasoning traces across conversation history, reducing redundant token generation and improving KV cache efficiency in multi-turn agent workflows.
- Agentic coding performance is the key strength — Qwen3.6-27B scores 77.2 on SWE-bench Verified, 59.3 on Terminal-Bench 2.0 (matching Claude 4.5 Opus), and 1487 on QwenWebBench, outperforming both its predecessor Qwen3.5-27B and the larger Qwen3.5-397B-A17B MoE model on several tasks.
- The architecture uses a hybrid Gated DeltaNet + Gated Attention layout across 64 layers — three out of every four sublayers use efficient linear attention (Gated DeltaNet), with Multi-Token Prediction (MTP) enabling speculative decoding at serving time.
- Two weight variants are available on Hugging Face Hub —
Qwen3.6-27B(BF16) andQwen3.6-27B-FP8(fine-grained FP8 with block size 128) — both supporting SGLang, vLLM, KTransformers, and Hugging Face Transformers, with a native 262,144-token context window extensible to 1,010,000 tokens via YaRN.
Check out the Technical details, Qwen/Qwen3.6-27B and Qwen/Qwen3.6-27B-FP8. Also, feel free to follow us on Twitter and don’t forget to join our 130k+ ML SubReddit and Subscribe to our Newsletter. Wait! are you on telegram? now you can join us on telegram as well.
Need to partner with us for promoting your GitHub Repo OR Hugging Face Page OR Product Release OR Webinar etc.? Connect with us