
Why Document OCR Still Remains a Hard Engineering Problem? What does it take to make OCR useful for real documents […]
Category: OCR

FireRedTeam Releases FireRed-OCR-2B Utilizing GRPO to Solve Structural Hallucinations in Tables and LaTeX for Software Developers
Document digitization has long been a multi-stage problem: first detect the layout, then extract the text, and finally try to […]
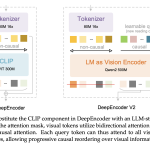
DeepSeek AI Releases DeepSeek-OCR 2 with Causal Visual Flow Encoder for Layout Aware Document Understanding
DeepSeek AI released DeepSeek-OCR 2, an open source document OCR and understanding system that restructures its vision encoder to read […]
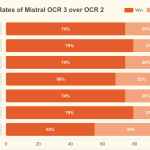
Mistral AI Releases OCR 3: A Smaller Optical Character Recognition (OCR) Model for Structured Document AI at Scale
Mistral AI has released Mistral OCR 3, its latest optical character recognition service that powers the company’s Document AI stack. […]
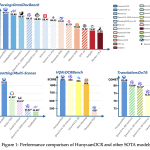
Tencent Hunyuan Releases HunyuanOCR: a 1B Parameter End to End OCR Expert VLM
Tencent Hunyuan has released HunyuanOCR, a 1B parameter vision language model that is specialized for OCR and document understanding. The […]

Comparing the Top 6 OCR (Optical Character Recognition) Models/Systems in 2025
Optical character recognition has moved from plain text extraction to document intelligence. Modern systems must read scanned and digital PDFs […]

DeepSeek Just Released a 3B OCR Model: A 3B VLM Designed for High-Performance OCR and Structured Document Conversion
DeepSeek-AI released 3B DeepSeek-OCR, an end to end OCR and document parsing Vision-Language Model (VLM) system that compresses long text […]

How to Build a Multilingual OCR AI Agent in Python with EasyOCR and OpenCV
In this tutorial, we build an Advanced OCR AI Agent in Google Colab using EasyOCR, OpenCV, and Pillow, running fully […]
What are Optical Character Recognition (OCR) Models? Top Open-Source OCR Models
Optical Character Recognition (OCR) is the process of turning images that contain text—such as scanned pages, receipts, or photographs—into machine-readable […]

Meet dots.ocr: A New 1.7B Vision-Language Model that Achieves SOTA Performance on Multilingual Document Parsing
dots.ocr is an open-source vision-language transformer model developed for multilingual document layout parsing and optical character recognition (OCR). It performs […]