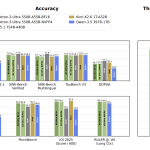
NVIDIA has released Nemotron 3 Ultra, the largest model in its Nemotron 3 family. It targets a specific problem: long-running […]
Category: Large Language Model
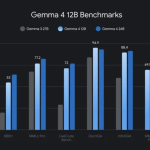
Google DeepMind Releases Gemma 4 12B: An Encoder-Free Multimodal Model with Native audio that runs on a 16 GB laptop
Google DeepMind just released Gemma 4 12B, a dense multimodal model that strips out traditional encoders entirely. Vision and audio […]
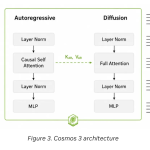
NVIDIA Releases Cosmos 3: A Two-Tower Mixture-of-Transformers Foundation Model Unifying Physical Reasoning, World Generation, and Action Generation
NVIDIA AI team have released Cosmos 3. It is a family of omnimodal world models for physical AI. The models […]

How to Fine-Tune LFM2 Using QLoRA and DPO: A Complete Step-by-Step Coding Tutorial on Google Colab
In this tutorial, we fine-tune Liquid AI’s LFM2 model through a complete open-source workflow. We start by loading the base […]

Alibaba’s Qwen Team Launches Qwen3.7-Plus, Adding Vision, Deep Reasoning, Tool Invocation, and Autonomous Iteration on the Bailian Platform
Alibaba’s Qwen team has released Qwen3.7-Plus. The model is now available through Alibaba Cloud’s Bailian platform. Bailian is the console […]
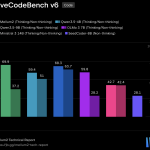
JetBrains Releases Mellum2: A 12B MoE Model for Fast, Specialized Tasks in Multi-Model AI Pipelines
JetBrains released Mellum2, open-sourcing the weights under the Apache 2.0 license. The first version of Mellum was a completion-focused 4B […]

MiniMax Releases MiniMax M3 with MSA Architecture Supporting 1M-Token Context, Native Multimodality, and Agentic Coding
MiniMax officially released MiniMax M3 on June 1, 2026. The model introduces MSA (MiniMax Sparse Attention), a new sparse attention […]

Trajectory Releases a Concurrent Multi-LoRA Training Stack for Continual Learning, Reporting a 2.81× Experiment-Throughput Gain
Trajectory’s concurrent multi-LoRA stack reports a 2.81× experiment-throughput gain over single-tenant RL, with all code in the NovaSky-AI/SkyRL GitHub repository. […]
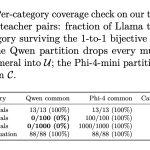
NVIDIA Introduces X-Token: Projection-Guided Cross-Tokenizer KD That Outperforms GOLD by +3.82 Average Points on Llama-3.2-1B
Knowledge distillation (KD) transfers “dark knowledge” from a large teacher model to a smaller student. The student learns from the […]

StepFun Releases Step 3.7 Flash: A 198B MoE Vision-Language Model for Coding Agents and Search Workflows
StepFun today released Step 3.7 Flash, a multimodal Mixture-of-Experts model targeting agentic use cases. It adds native vision input and […]