
DeepReinforce has released Ornith-1.0, an open-source model family built for agentic coding. The lineup spans four sizes, from a 9B […]
Category: Large Language Model
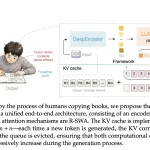
Baidu Releases Unlimited OCR, a 3B Model That Keeps the KV Cache Flat for Long-Document Parsing
Most end-to-end OCR models slow down as output grows. Each generated token adds to the KV cache. Memory rises and […]
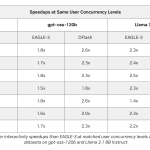
DFlash Speculative Decoding Drafts Whole Token Blocks in Parallel for Up to 15x Higher Throughput on NVIDIA Blackwell
Autoregressive large language models generate text one token at a time. Each token waits for the one before it. This […]
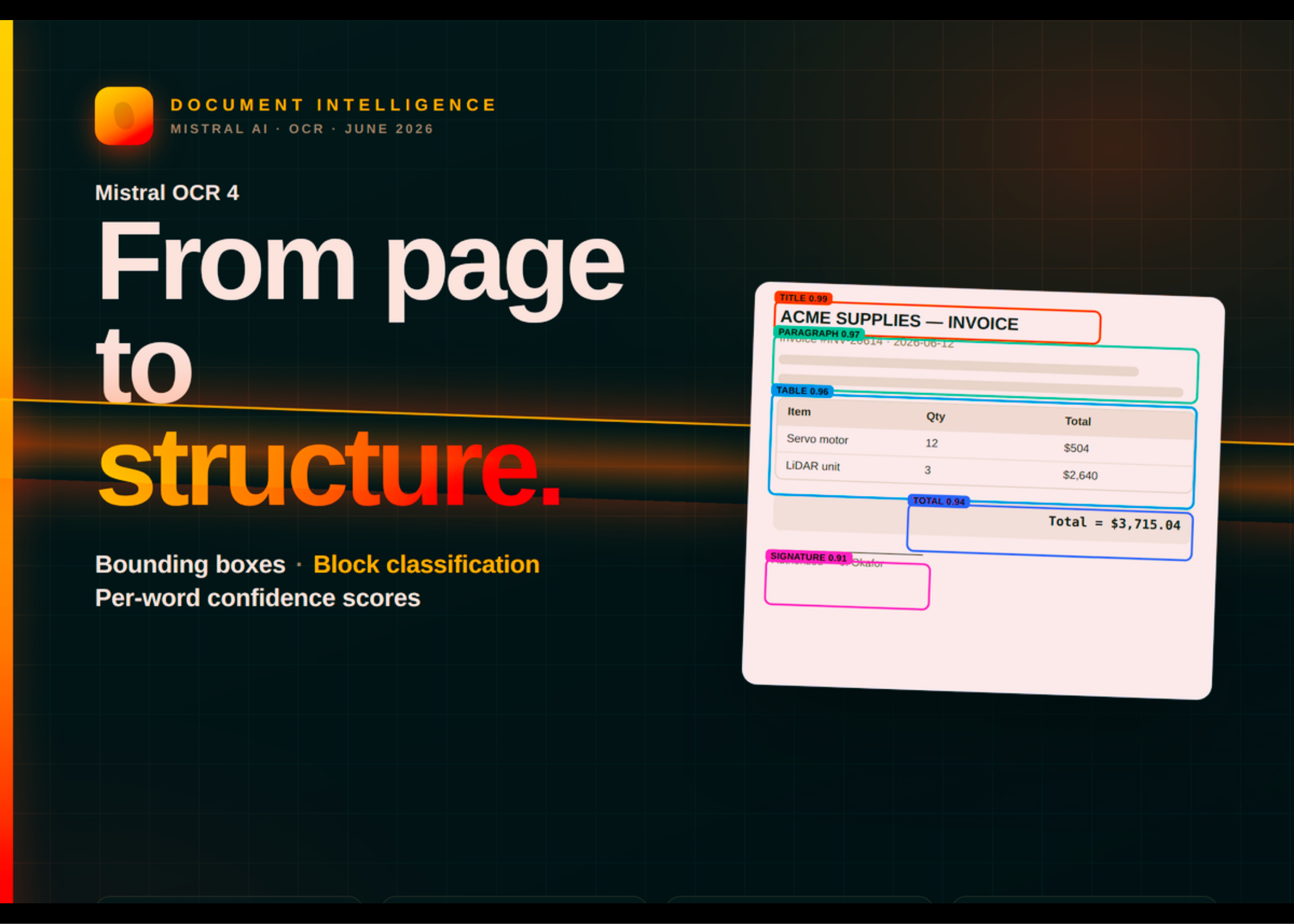
Mistral OCR 4 Brings Citation-Ready Structured Output to RAG, Agentic, and Enterprise Search Pipelines
Today, Mistral AI released OCR 4, its latest document-understanding model. This new release adds bounding boxes, block classification, and inline […]

Datalab Releases lift: A 9B Open-Weights Vision Model That Extracts Structured JSON From PDFs Using Schemas
Datalab has released lift, a 9B open-weights vision model for structured extraction. You pass it a JSON schema, and it […]

GLM-5.2 OpenAI-Compatible API: A Hands-On Guide to Reasoning Effort, Function Calling, and Long-Context Retrieval
In this tutorial, we work with GLM-5.2 and use its hosted, OpenAI-compatible API instead of running the full model locally. […]

Sakana AI Launches Sakana Fugu: An Orchestration Model That Routes Tasks Across a Swappable Pool of Frontier LLMs
Today, Sakana AI launched Sakana Fugu. It is a multi-agent orchestration system that behaves like one model. You send a […]
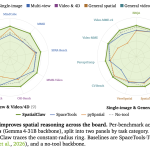
NVIDIA AI Introduce SpatialClaw: A Training-Free Agent That Treats Code as the Action Interface for Spatial Reasoning
NVIDIA Research has released SpatialClaw, a training-free framework for spatial reasoning. It targets a persistent weakness in vision-language models (VLMs). […]

VibeThinker-3B: A 3B Dense Reasoning Model Built on Qwen2.5-Coder-3B With the Spectrum-to-Signal Post-Training Pipeline
While recent breakthroughs in AI reasoning have largely been driven by massive scale, pouring in billions of parameters to cross […]

Liquid AI Introduces LFM2.5-Embedding-350M and LFM2.5-ColBERT-350M: Dense Bi-Encoder and Late-Interaction Models for Fast Multilingual Search Across 11 Languages
This week, Liquid AI released two new retrieval models. They are LFM2.5-ColBERT-350M and LFM2.5-Embedding-350M. Both hold 350M parameters. Both are […]