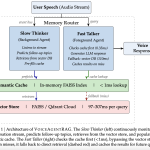
In the world of voice AI, the difference between a helpful assistant and an awkward interaction is measured in milliseconds. […]
Category: New Releases
Agent-Infra Releases AIO Sandbox: An All-in-One Runtime for AI Agents with Browser, Shell, Shared Filesystem, and MCP
In the development of autonomous agents, the technical bottleneck is shifting from model reasoning to the execution environment. While Large […]
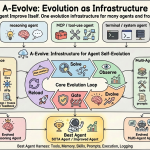
Meet A-Evolve: The PyTorch Moment For Agentic AI Systems Replacing Manual Tuning With Automated State Mutation And Self-Correction
A team of researchers associated with Amazon has released A-Evolve, a universal infrastructure designed to automate the development of autonomous […]

Chroma Releases Context-1: A 20B Agentic Search Model for Multi-Hop Retrieval, Context Management, and Scalable Synthetic Task Generation
In the current AI landscape, the ‘context window’ has become a blunt instrument. We’ve been told that if we simply […]
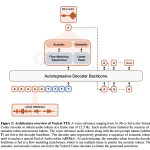
Mistral AI Releases Voxtral TTS: A 4B Open-Weight Streaming Speech Model for Low-Latency Multilingual Voice Generation
Mistral AI has released Voxtral TTS, an open-weight text-to-speech model that marks the company’s first major move into audio generation. […]
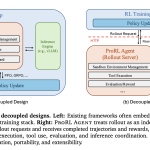
NVIDIA AI Unveils ProRL Agent: A Decoupled Rollout-as-a-Service Infrastructure for Reinforcement Learning of Multi-Turn LLM Agents at Scale
NVIDIA researchers introduced ProRL AGENT, a scalable infrastructure designed for reinforcement learning (RL) training of multi-turn LLM agents. By adopting […]
openJiuwen Community Releases ‘JiuwenClaw’: A Self Evolving AI Agent for Task Management
Over the past year, AI agents have evolved from merely answering questions to attempting to get real tasks done. However, […]

Meta Releases TRIBE v2: A Brain Encoding Model That Predicts fMRI Responses Across Video, Audio, and Text Stimuli
Neuroscience has long been a field of divide and conquer. Researchers typically map specific cognitive functions to isolated brain regions—like […]
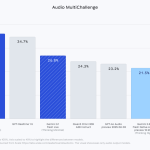
Google Releases Gemini 3.1 Flash Live: A Real-Time Multimodal Voice Model for Low-Latency Audio, Video, and Tool Use for AI Agents
Google has released Gemini 3.1 Flash Live in preview for developers through the Gemini Live API in Google AI Studio. […]
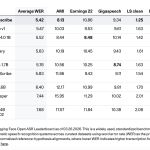
Cohere AI Releases Cohere Transcribe: A SOTA Automatic Speech Recognition (ASR) Model Powering Enterprise Speech Intelligence
In the landscape of enterprise AI, the bridge between unstructured audio and actionable text has often been a bottleneck of […]