
In the current landscape of computer vision, the standard operating procedure involves a modular ‘Lego-brick’ approach: a pre-trained vision encoder […]
Category: New Releases
Arcee AI Releases Trinity Large Thinking: An Apache 2.0 Open Reasoning Model for Long-Horizon Agents and Tool Use
The landscape of open-source artificial intelligence has shifted from purely generative models toward systems capable of complex, multi-step reasoning. While […]
Defeating the ‘Token Tax’: How Google Gemma 4, NVIDIA, and OpenClaw are Revolutionizing Local Agentic AI: From RTX Desktops to DGX Spark
Run Google’s latest omni-capable open models faster on NVIDIA RTX AI PCs, from NVIDIA Jetson Orin Nano, GeForce RTX desktops […]

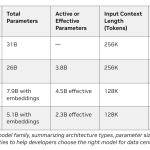
IBM Releases Granite 4.0 3B Vision: A New Vision Language Model for Enterprise Grade Document Data Extraction
IBM has announced the release of Granite 4.0 3B Vision, a vision-language model (VLM) engineered specifically for enterprise-grade document data […]
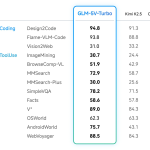
Z.ai Launches GLM-5V-Turbo: A Native Multimodal Vision Coding Model Optimized for OpenClaw and High-Capacity Agentic Engineering Workflows Everywhere
In the field of vision-language models (VLMs), the ability to bridge the gap between visual perception and logical code execution […]
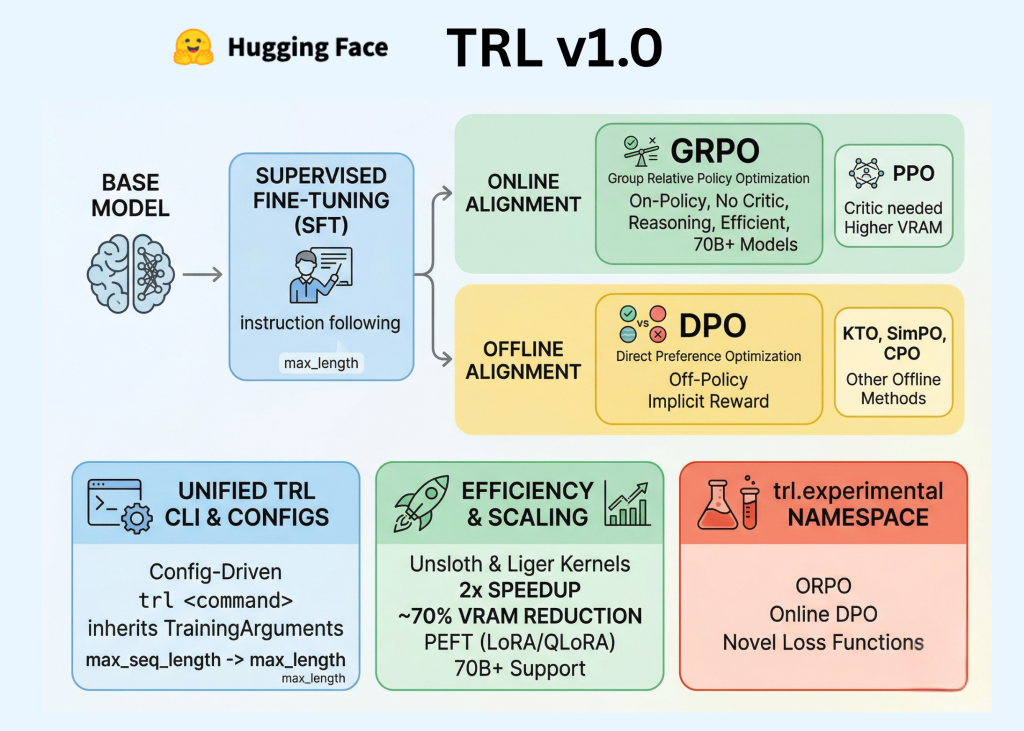
Hugging Face Releases TRL v1.0: A Unified Post-Training Stack for SFT, Reward Modeling, DPO, and GRPO Workflows
Hugging Face has officially released TRL (Transformer Reinforcement Learning) v1.0, marking a pivotal transition for the library from a research-oriented […]

Google AI Releases Veo 3.1 Lite: Giving Developers Low Cost High Speed Video Generation via The Gemini API
Google has announced the release of Veo 3.1 Lite, a new model tier within its generative video portfolio designed to […]

Liquid AI Released LFM2.5-350M: A Compact 350M Parameter Model Trained on 28T Tokens with Scaled Reinforcement Learning
In the current landscape of generative AI, the ‘scaling laws’ have generally dictated that more parameters equal more intelligence. However, […]
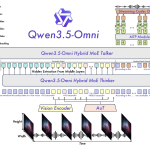
Alibaba Qwen Team Releases Qwen3.5 Omni: A Native Multimodal Model for Text, Audio, Video, and Realtime Interaction
The landscape of multimodal large language models (MLLMs) has shifted from experimental ‘wrappers’—where separate vision or audio encoders are stitched […]
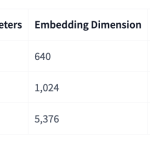
Microsoft AI Releases Harrier-OSS-v1: A New Family of Multilingual Embedding Models Hitting SOTA on Multilingual MTEB v2
Microsoft has announced the release of Harrier-OSS-v1, a family of three multilingual text embedding models designed to provide high-quality semantic […]