
Google has introduced Gemini 3.1 Flash TTS, a preview text-to-speech model focused on improving speech quality, expressive control, and multilingual […]
Category: New Releases

Google DeepMind Releases Gemini Robotics-ER 1.6: Bringing Enhanced Embodied Reasoning and Instrument Reading to Physical AI
Google DeepMind research team introduced Gemini Robotics-ER 1.6, a significant upgrade to its embodied reasoning model designed to serve as […]

Google Launches ‘Skills’ in Chrome: Turning Reusable AI Prompts into One-Click Browser Workflows
Google just announced the release of Skills in Chrome, a new feature built into Gemini in Chrome that lets users […]

TinyFish AI Releases Full Web Infrastructure Platform for AI Agents: Search, Fetch, Browser, and Agent Under One API Key
AI agents struggle with tasks that require interacting with the live web — fetching a competitor’s pricing page, extracting structured […]
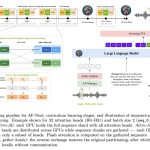
NVIDIA and the University of Maryland Researchers Released Audio Flamingo Next (AF-Next): A Super Powerful and Open Large Audio-Language Model
Understanding audio has always been the multimodal frontier that lags behind vision. While image-language models have rapidly scaled toward real-world […]

Google AI Research Proposes Vantage: An LLM-Based Protocol for Measuring Collaboration, Creativity, and Critical Thinking
Standardized tests can tell you whether a student knows calculus or can parse a passage of text. What they cannot […]
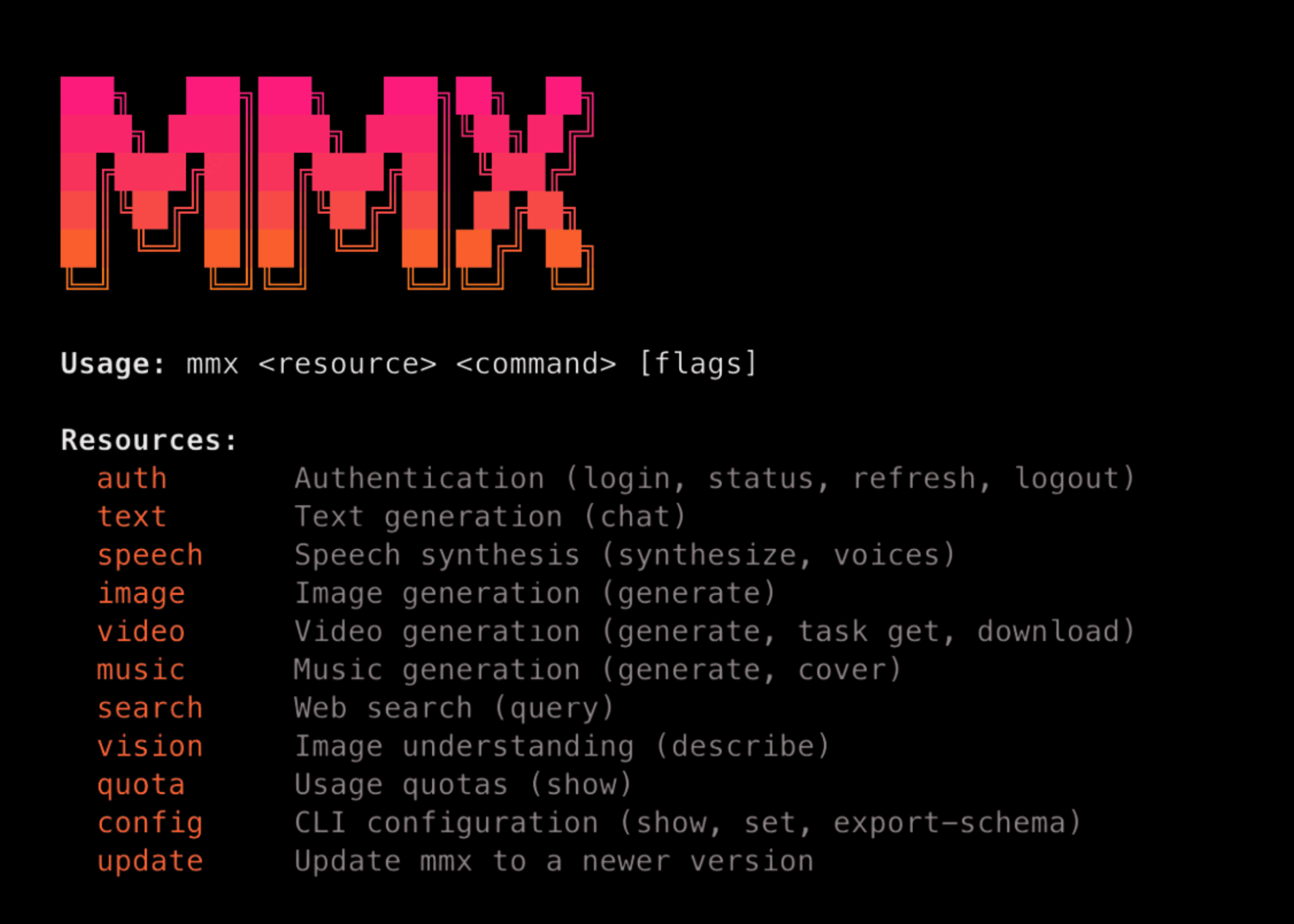
MiniMax Releases MMX-CLI: A Command-Line Interface That Gives AI Agents Native Access to Image, Video, Speech, Music, Vision, and Search
MiniMax, the AI research company behind the MiniMax omni-modal model stack, has released MMX-CLI — Node.js-based command-line interface that exposes […]

MiniMax Just Open Sourced MiniMax M2.7: A Self-Evolving Agent Model that Scores 56.22% on SWE-Pro and 57.0% on Terminal Bench 2
MiniMax has officially open-sourced MiniMax M2.7, making the model weights publicly available on Hugging Face. Originally announced on March 18, […]

Liquid AI Releases LFM2.5-VL-450M: a 450M-Parameter Vision-Language Model with Bounding Box Prediction, Multilingual Support, and Sub-250ms Edge Inference
Liquid AI just released LFM2.5-VL-450M, an updated version of its earlier LFM2-VL-450M vision-language model. The new release introduces bounding box […]

Researchers from MIT, NVIDIA, and Zhejiang University Propose TriAttention: A KV Cache Compression Method That Matches Full Attention at 2.5× Higher Throughput
Long-chain reasoning is one of the most compute-intensive tasks in modern large language models. When a model like DeepSeek-R1 or […]