
Musk has also apparently used the Grok chatbots as an automated extension of his trolling habits, showing examples of Grok […]
Category: Machine Learning
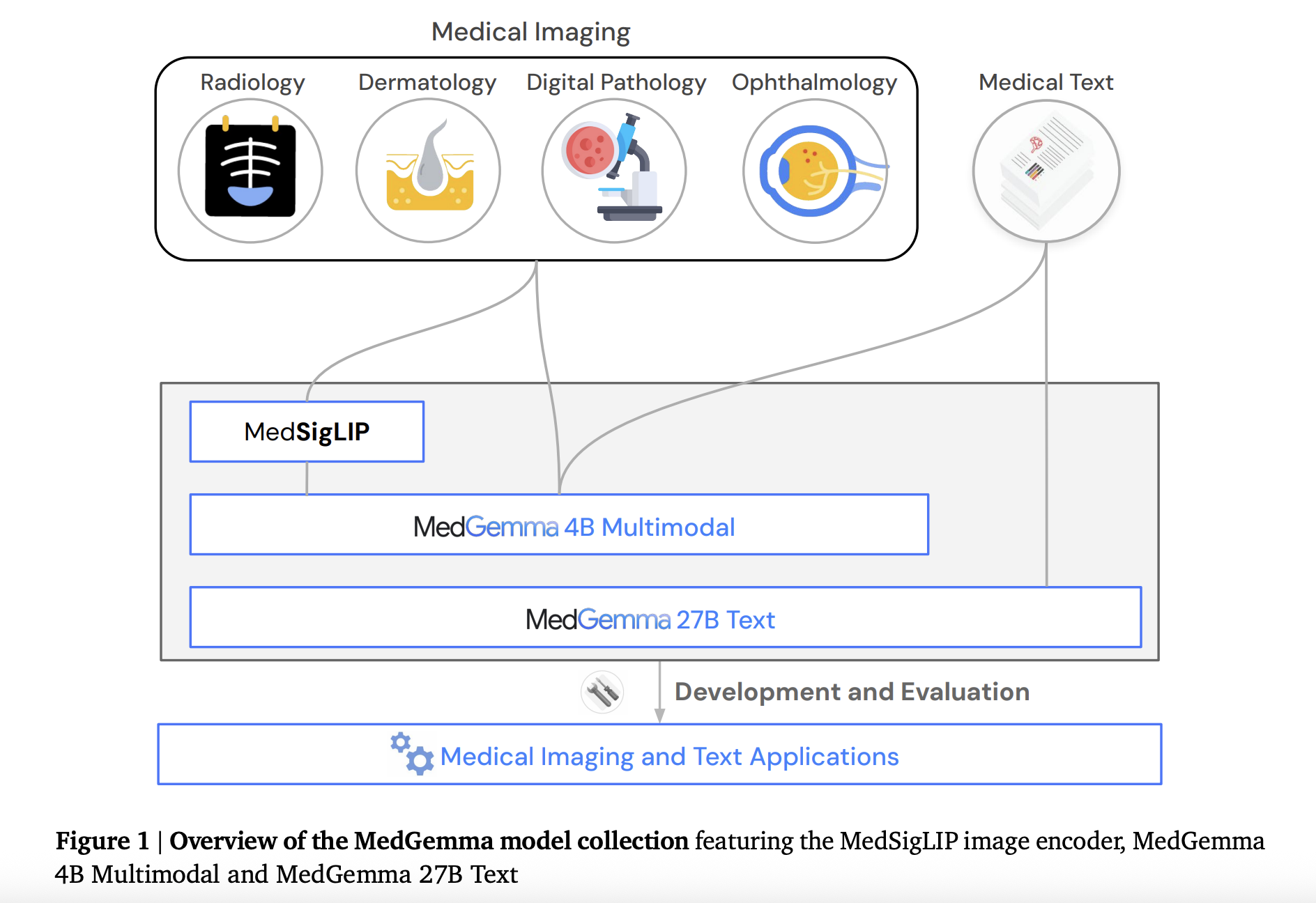
Google AI Open-Sourced MedGemma 27B and MedSigLIP for Scalable Multimodal Medical Reasoning
In a strategic move to advance open-source development in medical AI, Google DeepMind and Google Research have introduced two new […]

ChatGPT made up a product feature out of thin air, so this company created it
On Monday, sheet music platform Soundslice says it developed a new feature after discovering that ChatGPT was incorrectly telling users […]

AI mania pushes Nvidia to record $4 trillion valuation
On Wednesday, Nvidia became the first company in history to reach $4 trillion market valuation as shares rose more than […]

Hugging Face Releases SmolLM3: A 3B Long-Context, Multilingual Reasoning Model
Hugging Face just released SmolLM3, the latest version of its “Smol” language models, designed to deliver strong multilingual reasoning over […]

What is AGI? Nobody agrees, and it’s tearing Microsoft and OpenAI apart.
Several definitions make measuring “human-level” AI an exercise in moving goalposts. When is an AI system intelligent enough to be […]
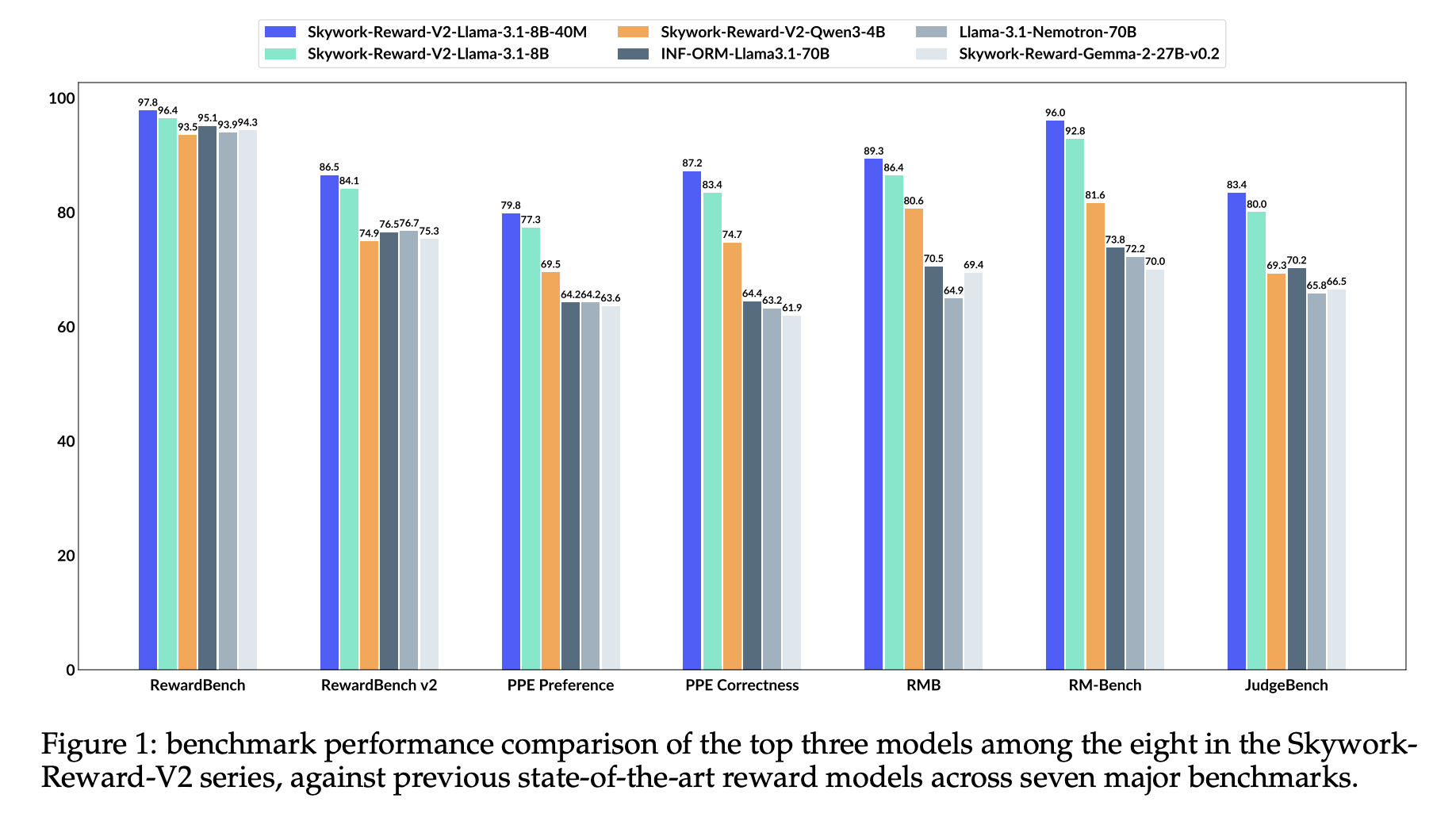
SynPref-40M and Skywork-Reward-V2: Scalable Human-AI Alignment for State-of-the-Art Reward Models
Understanding Limitations of Current Reward Models Although reward models play a crucial role in Reinforcement Learning from Human Feedback (RLHF), […]
What Is Context Engineering in AI? Techniques, Use Cases, and Why It Matters
Introduction: What is Context Engineering? Context engineering refers to the discipline of designing, organizing, and manipulating the context that is […]
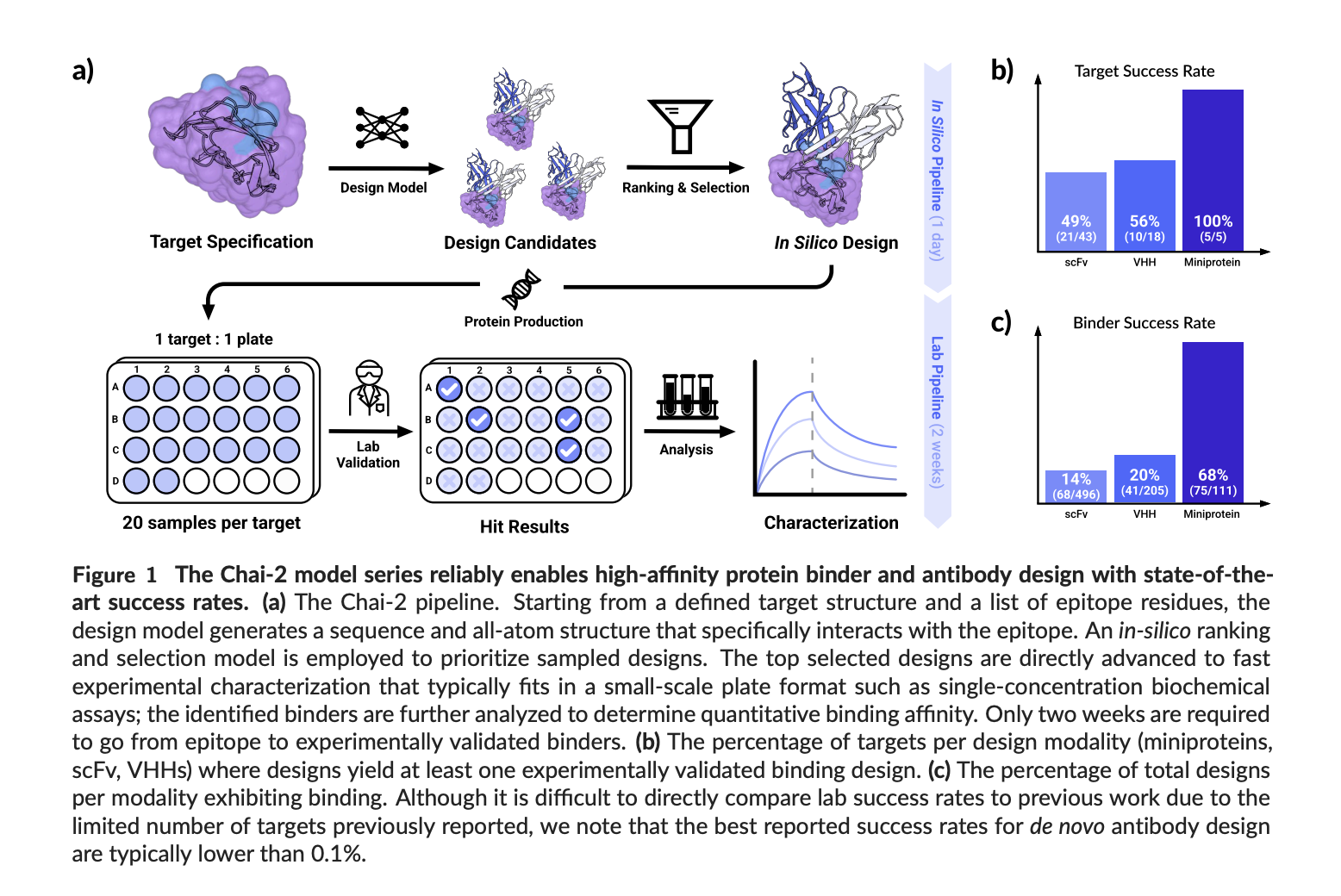
Chai Discovery Team Releases Chai-2: AI Model Achieves 16% Hit Rate in De Novo Antibody Design
TLDR: Chai Discovery Team introduces Chai-2, a multimodal AI model that enables zero-shot de novo antibody design. Achieving a 16% […]

AbstRaL: Teaching LLMs Abstract Reasoning via Reinforcement to Boost Robustness on GSM Benchmarks
Recent research indicates that LLMs, particularly smaller ones, frequently struggle with robust reasoning. They tend to perform well on familiar […]