
Datalab’s Lift is a focused document extraction tool with a specific promise: give it a PDF or image plus a […]
Category: Editors Pick

Robbyant Releases LingBot-VLA 2.0: An Open-Source 6B Vision-Language-Action (VLA) Model for Cross-Embodiment Robot Manipulation
Ant Group’s Robbyant has released LingBot-VLA 2.0, a Vision-Language-Action (VLA) foundation model for robots. The release includes a technical report, […]

SpaceXAI Releases Grok 4.5, a Cursor-Trained Model for Coding, Agentic Tasks, and Knowledge Work at $2/M Input
SpaceXAI just released Grok 4.5. The company calls it its smartest model to date. It targets coding, agentic tasks, and […]
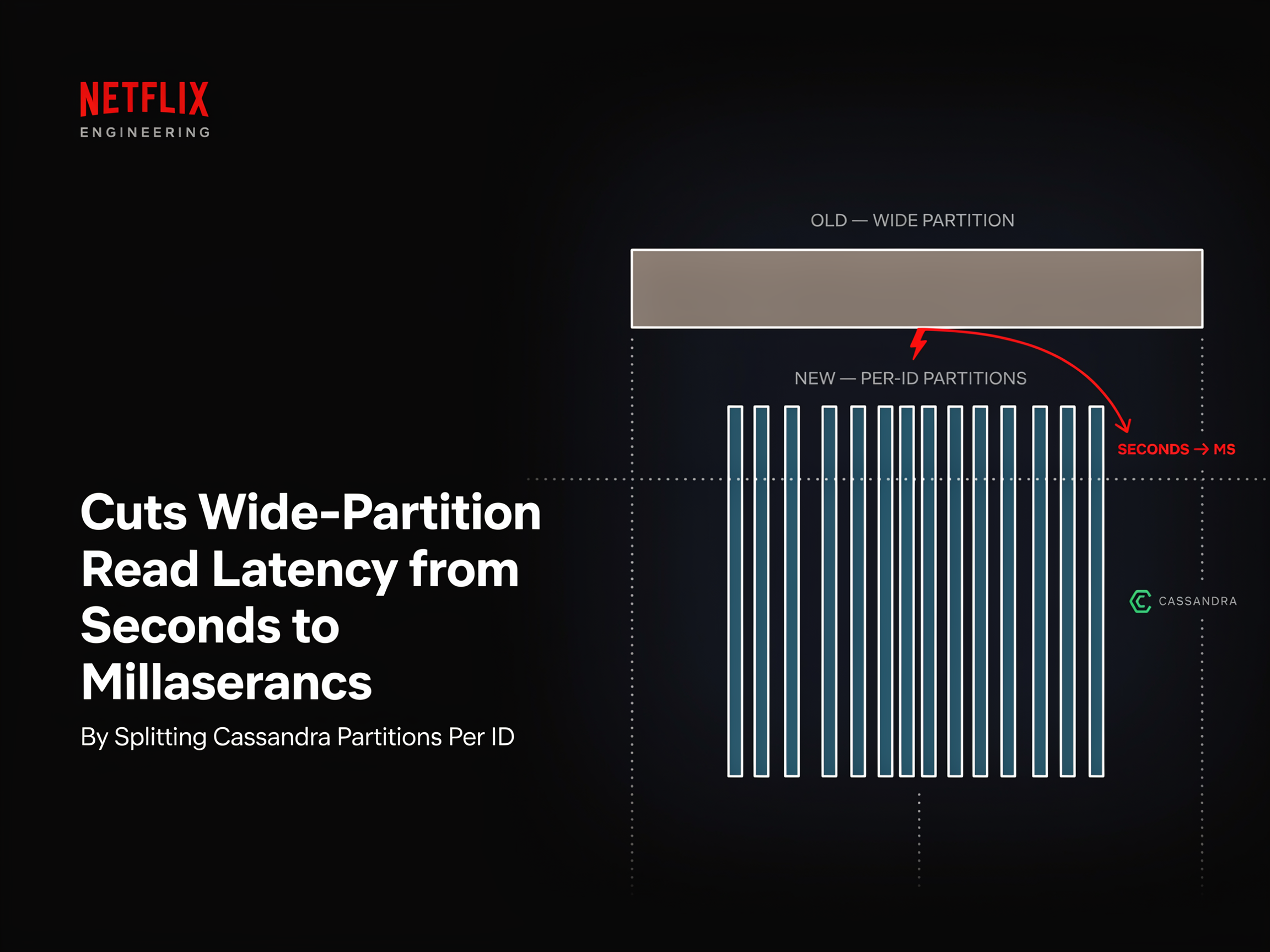
Netflix AI Team Cuts Wide-Partition Read Latency from Seconds to Milliseconds by Splitting Cassandra Partitions Per ID
Netflix’s engineering team published a method for handling wide partitions in Apache Cassandra. The research work targets Netflix’s TimeSeries Abstraction, […]

Google AI Studio Adds ‘Import from GitHub’ to Build Mode, Turning an Existing Repo Into an Editable, Deployable App
Google AI Studio is rolling out an ‘import from GitHub’ feature inside its Build mode. It takes a repo and […]

OpenAI Releases GPT-Live and GPT-Live-1 mini: Full-Duplex Voice Models That Delegate Deeper Reasoning to GPT-5.5
Today, OpenAI released GPT-Live. It is a new generation of voice models. GPT-Live now powers the ChatGPT Voice experience. The […]

NVIDIA’s Cosmos-Framework Tutorial: Designing a Colab-Friendly Miniature of Cosmos 3 World Models with Omnimodal Mixture-of-Transformers
In this tutorial, we explore NVIDIA’s cosmos-framework from a practical Colab-friendly angle while staying honest about the hardware limits of […]

Ant Group’s Robbyant Open-Sources LingBot-Vision: A 1B Boundary-Centric Vision Foundation Model for Dense Spatial Perception
Robbyant, the embodied-AI company within Ant Group, has open-sourced LingBot-Vision, a family of self-supervised Vision Transformers built for dense spatial […]

NVIDIA Releases Audex (Nemotron-Labs-Audex-30B-A3B): A Unified Audio-Text LLM That Preserves the Text Intelligence of Its Backbone
NVIDIA has released Audex (Nemotron-Labs-Audex-30B-A3B), a unified audio-text large language model. It understands and generates both audio and speech. It […]

Liquid AI Open-Sources Antidoom: A Final Token Preference Optimization (FTPO) Method that Reduces Doom Loops in Reasoning Models
Liquid AI has released Antidoom, an open-source method that targets a common failure mode in reasoning models. That failure mode […]