
Inworld AI has introduced Inworld TTS-1.5, an upgrade to its TTS-1 family that targets realtime voice agents with strict constraints […]
Category: Audio Language Model

How to Design a Fully Streaming Voice Agent with End-to-End Latency Budgets, Incremental ASR, LLM Streaming, and Real-Time TTS
In this tutorial, we build an end-to-end streaming voice agent that mirrors how modern low-latency conversational systems operate in real […]
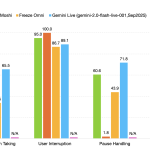
NVIDIA Releases PersonaPlex-7B-v1: A Real-Time Speech-to-Speech Model Designed for Natural and Full-Duplex Conversations
NVIDIA Researchers released PersonaPlex-7B-v1, a full duplex speech to speech conversational model that targets natural voice interactions with precise persona […]
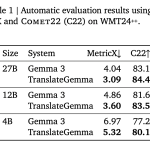
Google AI Releases TranslateGemma: A New Family of Open Translation Models Built on Gemma 3 with Support for 55 Languages
Google AI has released TranslateGemma, a suite of open machine translation models built on Gemma 3 and targeted at 55 […]
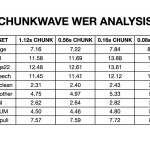
NVIDIA AI Released Nemotron Speech ASR: A New Open Source Transcription Model Designed from the Ground Up for Low-Latency Use Cases like Voice Agents
NVIDIA has just released its new streaming English transcription model (Nemotron Speech ASR) built specifically for low latency voice agents […]
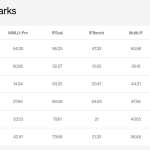
Liquid AI Releases LFM2.5: A Compact AI Model Family For Real On Device Agents
Liquid AI has introduced LFM2.5, a new generation of small foundation models built on the LFM2 architecture and focused at […]

Tencent Researchers Release Tencent HY-MT1.5: A New Translation Models Featuring 1.8B and 7B Models Designed for Seamless on-Device and Cloud Deployment
Tencent Hunyuan researchers have released HY-MT1.5, a multilingual machine translation family that targets both mobile devices and cloud systems with […]
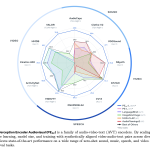
Meta AI Open-Sourced Perception Encoder Audiovisual (PE-AV): The Audiovisual Encoder Powering SAM Audio And Large Scale Multimodal Retrieval
Meta researchers have introduced Perception Encoder Audiovisual, PEAV, as a new family of encoders for joint audio and video understanding. […]

Meta AI Releases SAM Audio: A State-of-the-Art Unified Model that Uses Intuitive and Multimodal Prompts for Audio Separation
Meta has released SAM Audio, a prompt driven audio separation model that targets a common editing bottleneck, isolating one sound […]
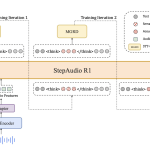
StepFun AI Releases Step-Audio-R1: A New Audio LLM that Finally Benefits from Test Time Compute Scaling
Why do current audio AI models often perform worse when they generate longer reasoning instead of grounding their decisions in […]