Moonshot AI, the Chinese AI lab behind the Kimi assistant, today open-sourced Kimi K2.6 — a native multimodal agentic model that pushes the boundaries of what an AI system can do when left to run autonomously on hard software engineering problems. The release targets practical deployment scenarios: long-running coding agents, front-end generation from natural language, massively parallel agent swarms coordinating hundreds of specialized sub-agents simultaneously, and a new open ecosystem where humans and agents from any device collaborate on the same task. The model is available now on Kimi.com, the Kimi App, the API, and Kimi Code CLI. Weights are published on Hugging Face under a Modified MIT License.
What Kind of Model is This, Technically?
Kimi K2.6 is a Mixture-of-Experts (MoE) model — an architecture that’s become increasingly dominant at frontier scale. Instead of activating all of a model’s parameters for every token it processes, a MoE model routes each token to a small subset of specialized ‘experts.’ This allows you to build a very large model while keeping inference compute tractable.
Kimi K2.6 has 1 trillion total parameters, but only 32 billion are activated per token. It has 384 experts in total, with 8 selected per token, plus 1 shared expert that is always active. The model has 61 layers (including one dense layer), uses an attention hidden dimension of 7,168, a MoE hidden dimension of 2,048 per expert, and 64 attention heads.
Beyond text, K2.6 is a native multimodal model — meaning vision is baked in architecturally, not bolted on. It uses a MoonViT vision encoder with 400M parameters and supports image and video input natively. Other architectural details: it uses Multi-head Latent Attention (MLA) as its attention mechanism, SwiGLU as the activation function, a vocabulary size of 160K tokens, and a context length of 256K tokens.
For deployment, K2.6 is recommended to run on vLLM, SGLang, or KTransformers. It shares the same architecture as Kimi K2.5, so existing deployment configurations can be reused directly. The required transformers version is >=4.57.1, <5.0.0.
The Long-Horizon Coding Headline Numbers
The metric that will likely get the most attention from dev teams is SWE-Bench Pro — a benchmark testing whether a model can resolve real-world GitHub issues in professional software repositories.
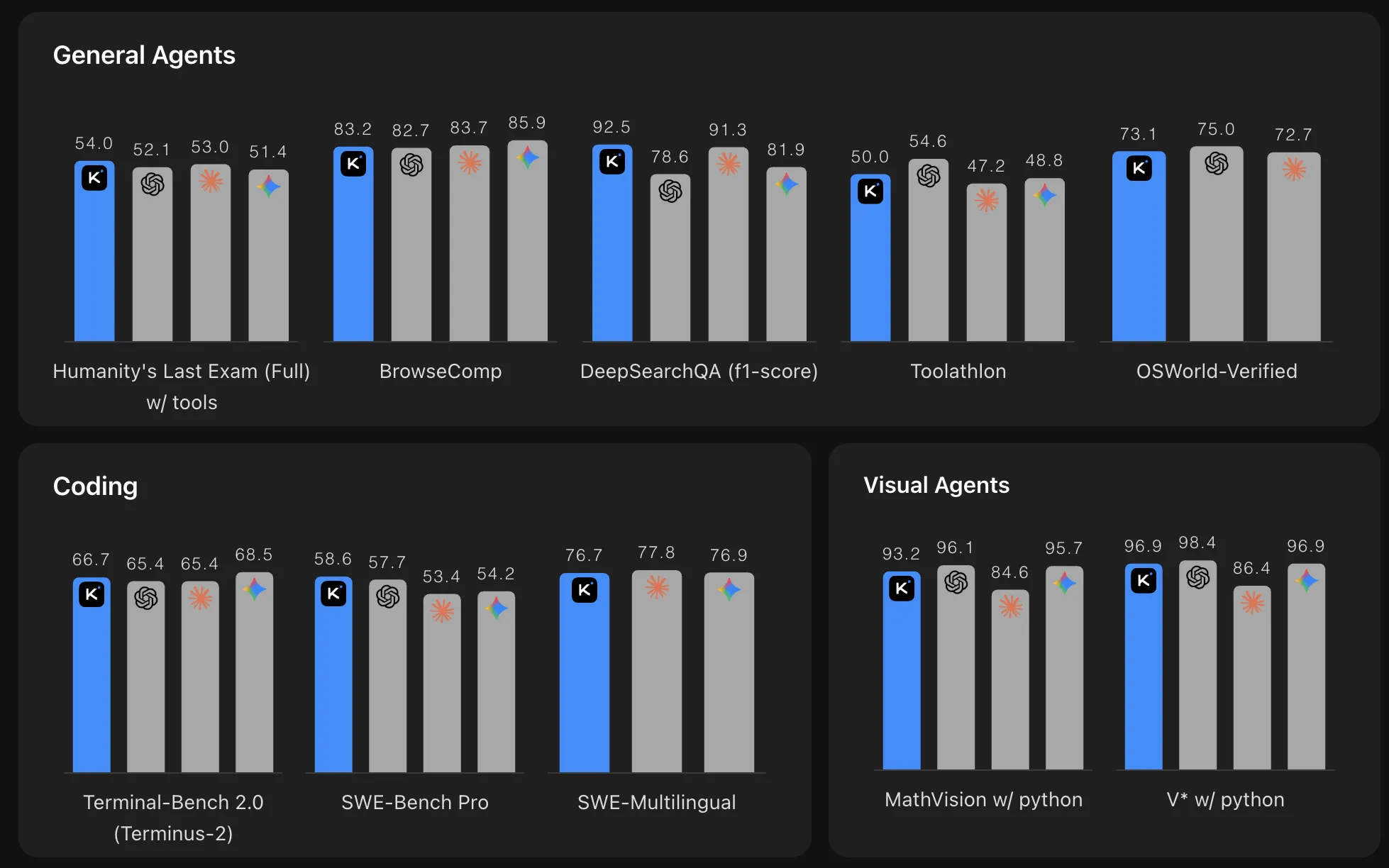
Kimi K2.6 scores 58.6 on SWE-Bench Pro, compared to 57.7 for GPT-5.4 (xhigh), 53.4 for Claude Opus 4.6 (max effort), 54.2 for Gemini 3.1 Pro (thinking high), and 50.7 for Kimi K2.5. On SWE-Bench Verified it scores 80.2, sitting within a tight band of top-tier models.
On Terminal-Bench 2.0 using the Terminus-2 agent framework, K2.6 achieves 66.7, compared to 65.4 for both GPT-5.4 and Claude Opus 4.6, and 68.5 for Gemini 3.1 Pro. On LiveCodeBench (v6), it scores 89.6 vs. Claude Opus 4.6’s 88.8.
Perhaps the most striking number for agentic workloads is Humanity’s Last Exam (HLE-Full) with tools: K2.6 scores 54.0 — leading every model in the comparison, including GPT-5.4 (52.1), Claude Opus 4.6 (53.0), and Gemini 3.1 Pro (51.4). HLE is widely considered one of the hardest knowledge benchmarks, and the with-tools variant specifically tests how well a model can leverage external resources autonomously. Internally, Moonshot evaluates long-horizon coding gains using their Kimi Code Bench, an internal benchmark covering diverse, complicated end-to-end tasks across languages and domains, where K2.6 demonstrates significant improvements over K2.5.
What 13 Hours of Autonomous Coding Actually Looks Like
Two engineering case studies in the release document what ‘long-horizon coding’ means in practice.
In the first, Kimi K2.6 successfully downloaded and deployed the Qwen3.5-0.8B model locally on a Mac, then implemented and optimized model inference in Zig — a highly niche programming language — demonstrating exceptional out-of-distribution generalization. Across 4,000+ tool calls, over 12 hours of continuous execution, and 14 iterations, K2.6 improved throughput from approximately 15 to approximately 193 tokens/sec, ultimately achieving speeds approximately 20% faster than LM Studio.
In the second, Kimi K2.6 autonomously overhauled exchange-core, an 8-year-old open-source financial matching engine. Over a 13-hour execution, the model iterated through 12 optimization strategies, initiating over 1,000 tool calls to precisely modify more than 4,000 lines of code. Acting as an expert systems architect, K2.6 analyzed CPU and allocation flame graphs to pinpoint hidden bottlenecks and reconfigured the core thread topology from 4ME+2RE to 2ME+1RE — extracting a 185% medium throughput leap (from 0.43 to 1.24 MT/s) and a 133% performance throughput gain (from 1.23 to 2.86 MT/s).
Agent Swarms: Scaling Horizontally, Not Just Vertically
One of K2.6’s most architecturally interesting capabilities is its Agent Swarm — an approach to parallelizing complex tasks across many specialized sub-agents, rather than relying on a single, deeper reasoning chain.
The architecture scales horizontally to 300 sub-agents executing across 4,000 coordinated steps simultaneously, a substantial expansion from K2.5’s 100 sub-agents and 1,500 steps. The swarm dynamically decomposes tasks into heterogeneous subtasks — combining broad web search with deep research, large-scale document analysis with long-form writing, and multi-format content generation in parallel — then delivers consolidated outputs including documents, websites, slides, and spreadsheets within a single autonomous run. The swarm also introduces a concrete Skills capability: it can convert any high-quality PDF, spreadsheet, slide, or Word document into a reusable Skill. K2.6 captures and maintains the document’s structural and stylistic DNA, allowing it to reproduce the same quality and format in future tasks — think of it as teaching the swarm by example rather than prompt.
Concrete demonstrations include: a 100-sub-agent run that matched a single uploaded CV against 100 relevant roles in California and delivered 100 fully customized resumes; another that identified 30 retail stores in Los Angeles without websites from Google Maps and generated landing pages for each; and one that turned an astrophysics paper into a reusable academic skill and then produced a 40-page, 7,000-word research paper alongside a structured dataset with 20,000+ entries and 14 astronomy-grade charts.
On the BrowseComp benchmark in Agent Swarm mode, K2.6 scores 86.3 compared to 78.4 for Kimi K2.5. On DeepSearchQA (f1-score), K2.6 scores 92.5 against 78.6 for GPT-5.4.
Bring Your Own Agents: Claw Groups
Beyond Moonshot’s own swarm infrastructure, K2.6 introduces Claw Groups as a research preview — a new feature that opens the agent swarm architecture to an external, heterogeneous ecosystem.
The key design principle: multiple agents and humans operate as genuine collaborators in a shared operational space. Users can onboard agents from any device, running any model, each carrying their own specialized toolkits, skills, and persistent memory contexts — whether deployed on local laptops, mobile devices, or cloud instances. At the center of this swarm, K2.6 serves as an adaptive coordinator: it dynamically matches tasks to agents based on their specific skill profiles and available tools, detects when an agent encounters failure or stalls, automatically reassigns the task or regenerates subtasks, and manages the full lifecycle of deliverables from initiation through validation to completion.
Moonshot has been using Claw Groups internally to run their own content production and launch campaigns, with specialized agents including Demo Makers, Benchmark Makers, Social Media Agents, and Video Makers working in parallel — with K2.6 coordinating the process. For devs thinking about multi-agent orchestration architectures, this is worth looking into: it represents a shift from ‘AI does tasks for you’ to ‘AI coordinates a team of heterogeneous agents, some of which you built, on your behalf.’
Proactive Agents: 5 Days of Autonomous Operation
K2.6 demonstrates strong performance in persistent, proactive agents such as OpenClaw and Hermes, which operate across multiple applications with continuous, 24/7 execution. These workflows require AI to proactively manage schedules, execute code, and orchestrate cross-platform operations without human oversight.
Moonshot’s own RL infrastructure team used a K2.6-backed agent that operated autonomously for 5 days, managing monitoring, incident response, and system operations — demonstrating persistent context, multi-threaded task handling, and full-cycle execution from alert to resolution.
Performance in this regime is measured by an internal Claw Bench, an evaluation suite spanning five domains: Coding Tasks, IM Ecosystem Integration, Information Research & Analysis, Scheduled Task Management, and Memory Utilization. Across all five, K2.6 significantly outperforms K2.5 in task completion rates and tool invocation accuracy — particularly in workflows requiring sustained autonomous operation without human oversight.
Two Operational Modes: Thinking and Instant
For devs integrating via API, K2.6 exposes two inference modes that matter for latency/quality tradeoffs:
Thinking mode activates full chain-of-thought reasoning — the model reasons through a problem before producing a final answer. This is recommended for complex coding and agentic tasks, with a recommended temperature of 1.0. There is also a preserve thinking mode, which retains full reasoning content across multi-turn interactions and enhances performance in coding agent scenarios — disabled by default, but worth enabling when building agents that need to maintain coherent reasoning state across many steps.
Instant mode disables extended reasoning for lower-latency responses. To use Instant mode via the official API, pass {'thinking': {'type': 'disabled'}} in extra_body. For vLLM or SGLang deployments, pass {'chat_template_kwargs': {"thinking": False}} instead, with a recommended temperature of 0.6 and top-p of 0.95.
Key Takeaways
- Kimi K2.6 is a 1-trillion-parameter, native multimodal MoE model with only 32B parameters activated per token, released fully open-source under a Modified MIT License.
- K2.6 leads all frontier models on HLE-Full with tools (54.0), outperforming GPT-5.4 (52.1), Claude Opus 4.6 (53.0), and Gemini 3.1 Pro (51.4) on one of AI’s hardest agentic benchmarks.
- In real-world tests, K2.6 autonomously overhauled an 8-year-old financial matching engine over 13 hours, delivering a 185% medium throughput leap and a 133% performance throughput gain.
- The Agent Swarm architecture scales to 300 sub-agents executing 4,000 coordinated steps simultaneously, and can convert any PDF, spreadsheet, or slide into a reusable Skill that preserves structural and stylistic DNA.
- Claw Groups, introduced as a research preview, lets humans and agents from any device running any model collaborate in a shared swarm, with K2.6 serving as an adaptive coordinator that dynamically assigns tasks, detects failures, and manages full delivery lifecycles.
Check out the Model Weights, API Access and Technical details. Also, feel free to follow us on Twitter and don’t forget to join our 130k+ ML SubReddit and Subscribe to our Newsletter. Wait! are you on telegram? now you can join us on telegram as well.
Need to partner with us for promoting your GitHub Repo OR Hugging Face Page OR Product Release OR Webinar etc.? Connect with us


