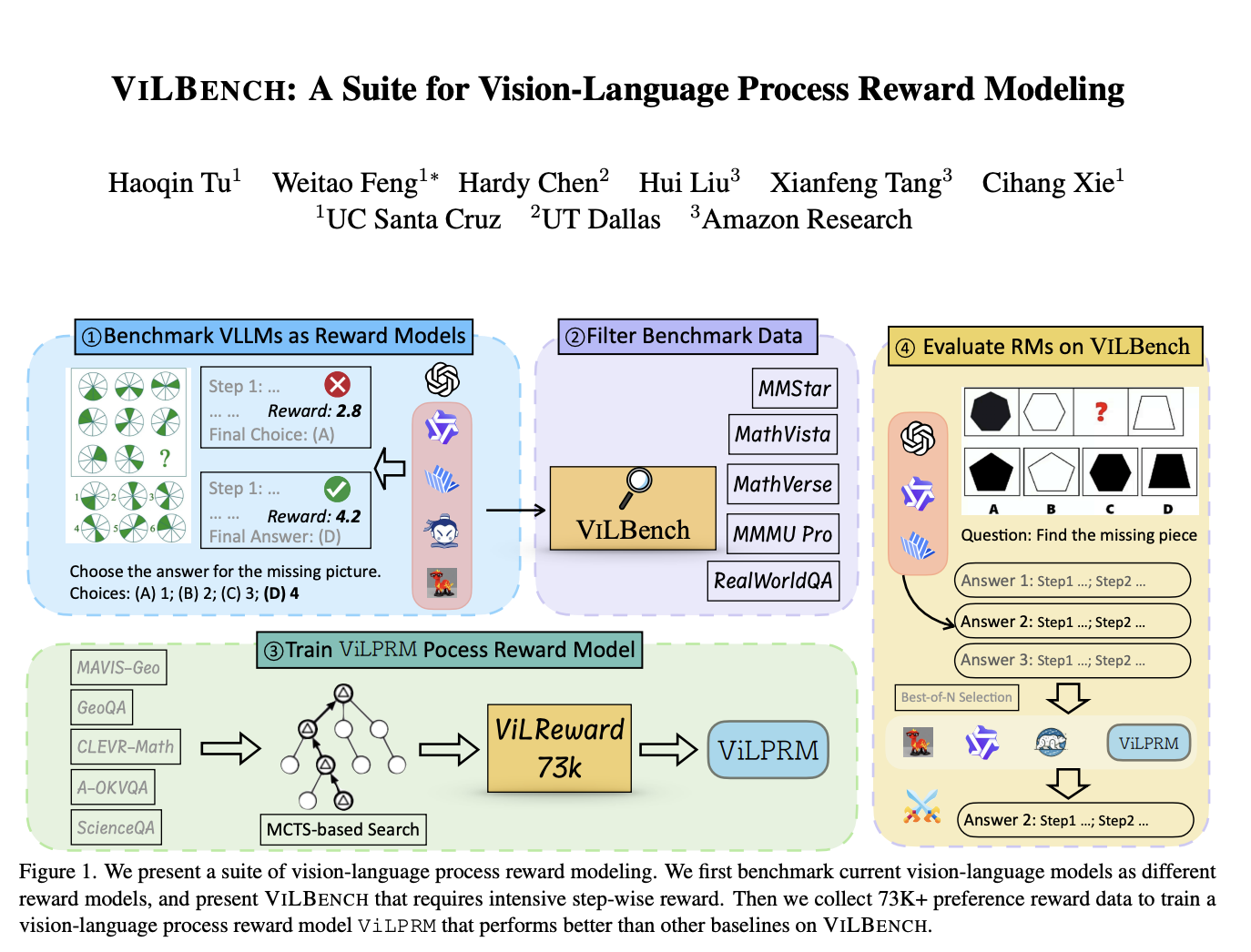
In this tutorial, we demonstrate how to efficiently fine-tune the Llama-2 7B Chat model for Python code generation using advanced techniques such as QLoRA, gradient checkpointing, and supervised fine-tuning with the SFTTrainer. Leveraging the Alpaca-14k dataset, we walk through setting up the environment, configuring LoRA parameters, and applying memory optimization strategies to train a model that excels in generating high-quality Python code. This step-by-step guide is designed for practitioners seeking to harness the power of LLMs with minimal computational overhead.
!pip install -q accelerate !pip install -q peft !pip install -q transformers !pip install -q trlFirst, install the required libraries for our project. They include accelerate, peft, transformers, and trl from the Python Package Index. The -q flag (quiet mode) keeps the output minimal.
import os from datasets import load_dataset from transformers import ( AutoModelForCausalLM, AutoTokenizer, HfArgumentParser, TrainingArguments, pipeline, logging, ) from peft import LoraConfig, PeftModel from trl import SFTTrainerImport the essential modules for our training setup. They include utilities for dataset loading, model/tokenizer, training arguments, logging, LoRA configuration, and the SFTTrainer.
# The model to train from the Hugging Face hub model_name = "NousResearch/llama-2-7b-chat-hf" # The instruction dataset to use dataset_name = "user/minipython-Alpaca-14k" # Fine-tuned model name new_model = "https://www.marktechpost.com/kaggle/working/llama-2-7b-codeAlpaca"We specify the base model from the Hugging Face hub, the instruction dataset, and the new model’s name.
# QLoRA parameters # LoRA attention dimension lora_r = 64 # Alpha parameter for LoRA scaling lora_alpha = 16 # Dropout probability for LoRA layers lora_dropout = 0.1Define the LoRA parameters for our model. `lora_r` sets the LoRA attention dimension, `lora_alpha` scales LoRA updates, and `lora_dropout` controls dropout probability.
# TrainingArguments parameters # Output directory where the model predictions and checkpoints will be stored output_dir = "https://www.marktechpost.com/kaggle/working/llama-2-7b-codeAlpaca" # Number of training epochs num_train_epochs = 1 # Enable fp16 training (set to True for mixed precision training) fp16 = True # Batch size per GPU for training per_device_train_batch_size = 8 # Batch size per GPU for evaluation per_device_eval_batch_size = 8 # Number of update steps to accumulate the gradients for gradient_accumulation_steps = 2 # Enable gradient checkpointing gradient_checkpointing = True # Maximum gradient norm (gradient clipping) max_grad_norm = 0.3 # Initial learning rate (AdamW optimizer) learning_rate = 2e-4 # Weight decay to apply to all layers except bias/LayerNorm weights weight_decay = 0.001 # Optimizer to use optim = "adamw_torch" # Learning rate schedule lr_scheduler_type = "constant" # Group sequences into batches with the same length # Saves memory and speeds up training considerably group_by_length = True # Ratio of steps for a linear warmup warmup_ratio = 0.03 # Save checkpoint every X updates steps save_steps = 100 # Log every X updates steps logging_steps = 10These parameters configure the training process. They include output paths, number of epochs, precision (fp16), batch sizes, gradient accumulation, and checkpointing. Additional settings like learning rate, optimizer, and scheduling help fine-tune training behavior. Warmup and logging settings control how the model starts training and how we monitor progress.
import torch print("PyTorch Version:", torch.__version__) print("CUDA Version:", torch.version.cuda)Import PyTorch and print both the installed PyTorch version and the corresponding CUDA version.
This command shows the GPU information, including driver version, CUDA version, and current GPU usage.
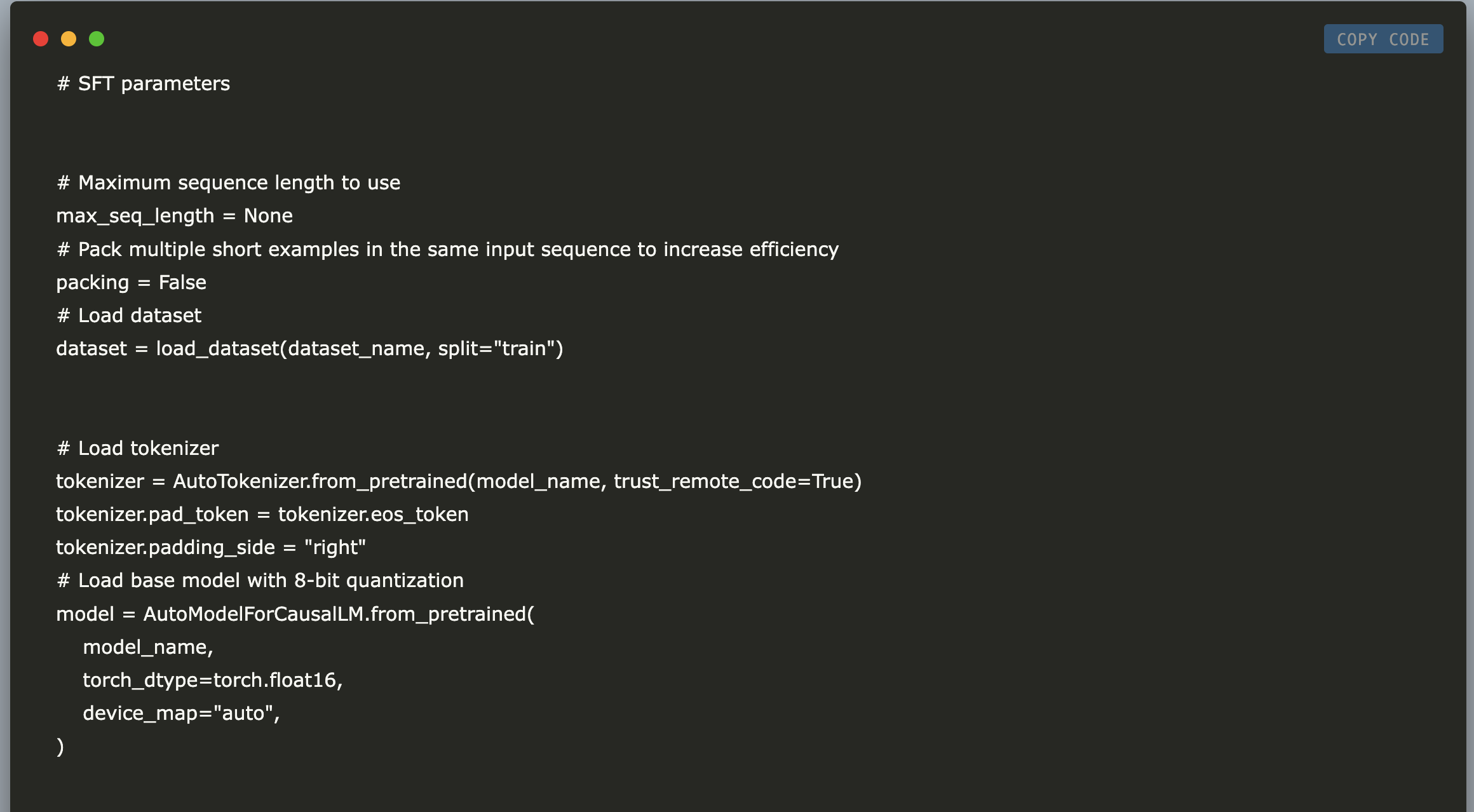
# SFT parameters # Maximum sequence length to use max_seq_length = None # Pack multiple short examples in the same input sequence to increase efficiency packing = False # Load the entire model on the GPU 0 device_map = {"": 0}Define SFT parameters, such as the maximum sequence length, whether to pack multiple examples, and mapping the entire model to GPU 0.
# SFT parameters # Maximum sequence length to use max_seq_length = None # Pack multiple short examples in the same input sequence to increase efficiency packing = False # Load dataset dataset = load_dataset(dataset_name, split="train") # Load tokenizer tokenizer = AutoTokenizer.from_pretrained(model_name, trust_remote_code=True) tokenizer.pad_token = tokenizer.eos_token tokenizer.padding_side = "right" # Load base model with 8-bit quantization model = AutoModelForCausalLM.from_pretrained( model_name, torch_dtype=torch.float16, device_map="auto", ) # Prepare model for training model.gradient_checkpointing_enable() model.enable_input_require_grads() Set additional SFT parameters and load our dataset and tokenizer. We configure padding tokens for the tokenizer and load the base model with 8-bit quantization. Finally, we enable gradient checkpointing and ensure the model requires input gradients for training.
from peft import get_peft_modelImport the `get_peft_model` function, which applies parameter-efficient fine-tuning (PEFT) to our base model.
# Load LoRA configuration peft_config = LoraConfig( lora_alpha=lora_alpha, lora_dropout=lora_dropout, r=lora_r, bias="none", task_type="CAUSAL_LM", ) # Apply LoRA to the model model = get_peft_model(model, peft_config) # Set training parameters training_arguments = TrainingArguments( output_dir=output_dir, num_train_epochs=num_train_epochs, per_device_train_batch_size=per_device_train_batch_size, gradient_accumulation_steps=gradient_accumulation_steps, optim=optim, save_steps=save_steps, logging_steps=logging_steps, learning_rate=learning_rate, weight_decay=weight_decay, fp16=fp16, max_grad_norm=max_grad_norm, warmup_ratio=warmup_ratio, group_by_length=True, lr_scheduler_type=lr_scheduler_type, ) # Set supervised fine-tuning parameters trainer = SFTTrainer( model=model, train_dataset=dataset, dataset_text_field="text", max_seq_length=max_seq_length, tokenizer=tokenizer, args=training_arguments, packing=packing, ) Configure and apply LoRA to our model using `LoraConfig` and `get_peft_model`. We then create `TrainingArguments` for model training, specifying epoch counts, batch sizes, and optimization settings. Lastly, we set up the `SFTTrainer`, passing it the model, dataset, tokenizer, and training arguments.
# Train model trainer.train() # Save trained model trainer.model.save_pretrained(new_model) Initiate the supervised fine-tuning process (`trainer.train()`) and then save the trained LoRA model to the specified directory.
# Run text generation pipeline with the fine-tuned model prompt = "How can I write a Python program that calculates the mean, standard deviation, and coefficient of variation of a dataset from a CSV file?" pipe = pipeline(task="text-generation", model=trainer.model, tokenizer=tokenizer, max_length=400) result = pipe(f"[INST] {prompt} [/INST]") print(result[0]['generated_text'])Create a text generation pipeline using our fine-tuned model and tokenizer. Then, we provide a prompt, generate text using the pipeline, and print the output.
from kaggle_secrets import UserSecretsClient user_secrets = UserSecretsClient() secret_value_0 = user_secrets.get_secret("HF_TOKEN")Access Kaggle Secrets to retrieve a stored Hugging Face token (`HF_TOKEN`). This token is used for authentication with the Hugging Face Hub.
# Empty VRAM # del model # del pipe # del trainer # del dataset del tokenizer import gc gc.collect() gc.collect() torch.cuda.empty_cache() The above snippet shows how to free up GPU memory by deleting references and clearing caches. We delete the tokenizer, run garbage collection, and empty the CUDA cache to reduce VRAM usage.
import torch # Check the number of GPUs available num_gpus = torch.cuda.device_count() print(f"Number of GPUs available: {num_gpus}") # Check if CUDA device 1 is available if num_gpus > 1: print("cuda:1 is available.") else: print("cuda:1 is not available.")We import PyTorch and check the number of GPUs detected. Then, we print the count and conditionally report whether the GPU with ID 1 is available.
import torch from transformers import AutoModelForCausalLM, AutoTokenizer from peft import PeftModel # Specify the device ID for your desired GPU (e.g., 0 for the first GPU, 1 for the second GPU) device_id = 1 # Change this based on your available GPUs device = f"cuda:{device_id}" # Load the base model on the specified GPU base_model = AutoModelForCausalLM.from_pretrained( model_name, low_cpu_mem_usage=True, return_dict=True, torch_dtype=torch.float16, device_map="auto", # Use auto to load on the available device ) # Load the LoRA weights lora_model = PeftModel.from_pretrained(base_model, new_model) # Move LoRA model to the specified GPU lora_model.to(device) # Merge the LoRA weights with the base model weights model = lora_model.merge_and_unload() # Ensure the merged model is on the correct device model.to(device) # Load tokenizer tokenizer = AutoTokenizer.from_pretrained(model_name, trust_remote_code=True) tokenizer.pad_token = tokenizer.eos_token tokenizer.padding_side = "right"Select a GPU device (device_id 1) and load the base model with specified precision and memory optimizations. Then, load and merge LoRA weights into the base model, ensuring the merged model is moved to the designated GPU. Finally, load the tokenizer and configure it with appropriate padding settings.
In conclusion, following this tutorial, you have successfully fine-tuned the Llama-2 7B Chat model to specialize in Python code generation. Integrating QLoRA, gradient checkpointing, and SFTTrainer demonstrates a practical approach to managing resource constraints while achieving high performance.
Download the Colab Notebook here. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. Don’t Forget to join our 75k+ ML SubReddit.

Asif Razzaq
Asif Razzaq is the CEO of Marktechpost Media Inc.. As a visionary entrepreneur and engineer, Asif is committed to harnessing the potential of Artificial Intelligence for social good. His most recent endeavor is the launch of an Artificial Intelligence Media Platform, Marktechpost, which stands out for its in-depth coverage of machine learning and deep learning news that is both technically sound and easily understandable by a wide audience. The platform boasts of over 2 million monthly views, illustrating its popularity among audiences.