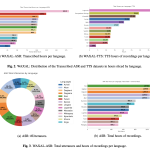
Speech technology still has a data distribution problem. Automatic Speech Recognition (ASR) and Text-to-Speech (TTS) systems have improved rapidly for […]
Category: Voice AI
IBM AI Releases Granite 4.0 1B Speech as a Compact Multilingual Speech Model for Edge AI and Translation Pipelines
IBM has released Granite 4.0 1B Speech, a compact speech-language model designed for multilingual automatic speech recognition (ASR) and bidirectional […]

Fish Audio Releases Fish Audio S2: A New Generation of Expressive Text-to-Speech (TTS) with Absurdly Controllable Emotion
The landscape of Text-to-Speech (TTS) is moving away from modular pipelines toward integrated Large Audio Models (LAMs). Fish Audio’s release […]

Beyond Simple API Requests: How OpenAI’s WebSocket Mode Changes the Game for Low Latency Voice Powered AI Experiences
In the world of Generative AI, latency is the ultimate killer of immersion. Until recently, building a voice-enabled AI agent […]

Google DeepMind Releases Lyria 3: An Advanced Music Generation AI Model that Turns Photos and Text into Custom Tracks with Included Lyrics and Vocals
Google DeepMind is pushing the boundaries of generative AI again. This time, the focus is not on text or images. […]
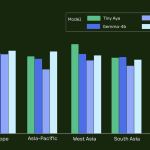
Cohere Releases Tiny Aya: A 3B-Parameter Small Language Model that Supports 70 Languages and Runs Locally Even on a Phone
Cohere AI Labs has released Tiny Aya, a family of small language models (SLMs) that redefines multilingual performance. While many […]

Meet ‘Kani-TTS-2’: A 400M Param Open Source Text-to-Speech Model that Runs in 3GB VRAM with Voice Cloning Support
The landscape of generative audio is shifting toward efficiency. A new open-source contender, Kani-TTS-2, has been released by the team […]
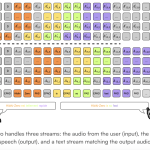
Kyutai Releases Hibiki-Zero: A3B Parameter Simultaneous Speech-to-Speech Translation Model Using GRPO Reinforcement Learning Without Any Word-Level Aligned Data
Kyutai has released Hibiki-Zero, a new model for simultaneous speech-to-speech translation (S2ST) and speech-to-text translation (S2TT). The system translates source […]

Mistral AI Launches Voxtral Transcribe 2: Pairing Batch Diarization And Open Realtime ASR For Multilingual Production Workloads At Scale
Automatic speech recognition (ASR) is becoming a core building block for AI products, from meeting tools to voice agents. Mistral’s […]

Qwen Researchers Release Qwen3-TTS: an Open Multilingual TTS Suite with Real-Time Latency and Fine-Grained Voice Control
Alibaba Cloud’s Qwen team has open-sourced Qwen3-TTS, a family of multilingual text-to-speech models that target three core tasks in one […]