In this tutorial, we build an advanced hands-on workflow with the Deepgram Python SDK and explore how modern voice AI […]
Category: Voice AI
xAI Launches Standalone Grok Speech-to-Text and Text-to-Speech APIs, Targeting Enterprise Voice Developers
Elon Musk’s AI company xAI has launched two standalone audio APIs — a Speech-to-Text (STT) API and a Text-to-Speech (TTS) […]

Google AI Launches Gemini 3.1 Flash TTS: A New Benchmark in Expressive and Controllable AI Voice
Google has introduced Gemini 3.1 Flash TTS, a preview text-to-speech model focused on improving speech quality, expressive control, and multilingual […]
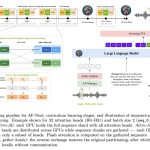
NVIDIA and the University of Maryland Researchers Released Audio Flamingo Next (AF-Next): A Super Powerful and Open Large Audio-Language Model
Understanding audio has always been the multimodal frontier that lags behind vision. While image-language models have rapidly scaled toward real-world […]

A Hands-On Coding Tutorial for Microsoft VibeVoice Covering Speaker-Aware ASR, Real-Time TTS, and Speech-to-Speech Pipelines
In this tutorial, we explore Microsoft VibeVoice in Colab and build a complete hands-on workflow for both speech recognition and […]
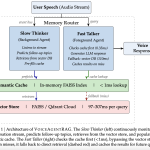
Salesforce AI Research Releases VoiceAgentRAG: A Dual-Agent Memory Router that Cuts Voice RAG Retrieval Latency by 316x
In the world of voice AI, the difference between a helpful assistant and an awkward interaction is measured in milliseconds. […]
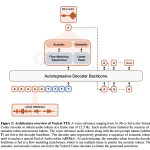
Mistral AI Releases Voxtral TTS: A 4B Open-Weight Streaming Speech Model for Low-Latency Multilingual Voice Generation
Mistral AI has released Voxtral TTS, an open-weight text-to-speech model that marks the company’s first major move into audio generation. […]
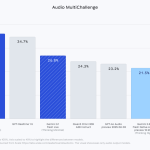
Google Releases Gemini 3.1 Flash Live: A Real-Time Multimodal Voice Model for Low-Latency Audio, Video, and Tool Use for AI Agents
Google has released Gemini 3.1 Flash Live in preview for developers through the Gemini Live API in Google AI Studio. […]
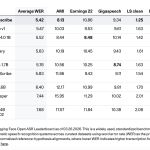
Cohere AI Releases Cohere Transcribe: A SOTA Automatic Speech Recognition (ASR) Model Powering Enterprise Speech Intelligence
In the landscape of enterprise AI, the bridge between unstructured audio and actionable text has often been a bottleneck of […]
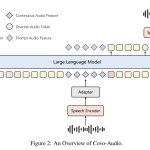
Tencent AI Open Sources Covo-Audio: A 7B Speech Language Model and Inference Pipeline for Real-Time Audio Conversations and Reasoning
Tencent AI Lab has released Covo-Audio, a 7B-parameter end-to-end Large Audio Language Model (LALM). The model is designed to unify […]