
Alibaba’s Qwen team has made Qwen3.8-Max broadly available and confirmed that its open weights ship next week. A second checkpoint, […]
Category: Staff

Cogent AI Team Releases VR-1: A Frontier Cyber Reasoning Model That Composes and Verifies Enterprise Attack Paths
Cogent AI team released Cogent VR-1, a reasoning model post-trained specifically for cybersecurity rather than picking up cyber capability as […]

Onton Releases Ontology 1: A Neurosymbolic Search Model That is 2.7x More Accurate than the World’s Best E-commerce Search Engines
Onton, a San Francisco-based search and discovery company, has released Ontology 1, a neurosymbolic model for complex, conversational, multimodal product […]

A Tutorial on GeoAI: Designing Footprint Extraction from NAIP Imagery Using U-Net, Grounding DINO, SAM, and Mask R-CNN
In this tutorial, we design a complete GeoAI workflow for extracting building footprints from high-resolution NAIP aerial imagery. We begin […]

End-to-End Forecasting with TimesFM 2.5: Backtesting, Covariates, Anomaly Detection, and Scalable Colab Deployment
In this tutorial, we build an advanced end-to-end time-series forecasting workflow with TimesFM 2.5. We begin by configuring the runtime, […]

Accelerating Transformer Training with NVIDIA Transformer Engine, Fused Kernels, BF16, FP8, and GPU Benchmarking
In this tutorial, we explore how NVIDIA Transformer Engine accelerates transformer workloads by combining fused GPU kernels, BF16 computation, and […]

Supabase Releases Evals: an Open Source Benchmark That Scores Claude Code, Codex and OpenCode on Real Supabase Tasks
Supabase has open sourced Supabase Evals, its benchmark and framework for testing how well AI agents build using Supabase. It […]

MiniMax Releases MiniMax H3: An Omni-Modal Video Model That Generates 15-Second 2K Clips With Native Stereo Audio
MiniMax releases MiniMax H3, a general-purpose multimodal generation model. MiniMax H3 is not a text-to-video model with add-ons. MiniMax describes […]

DeepSeek Upgrades DeepSeek-V4-Flash-0731 with Major Agentic and Coding Gains
DeepSeek published DeepSeek-V4-Flash-0731 on Hugging Face and moved the official V4-Flash API into public beta on July 31, 2026. The […]
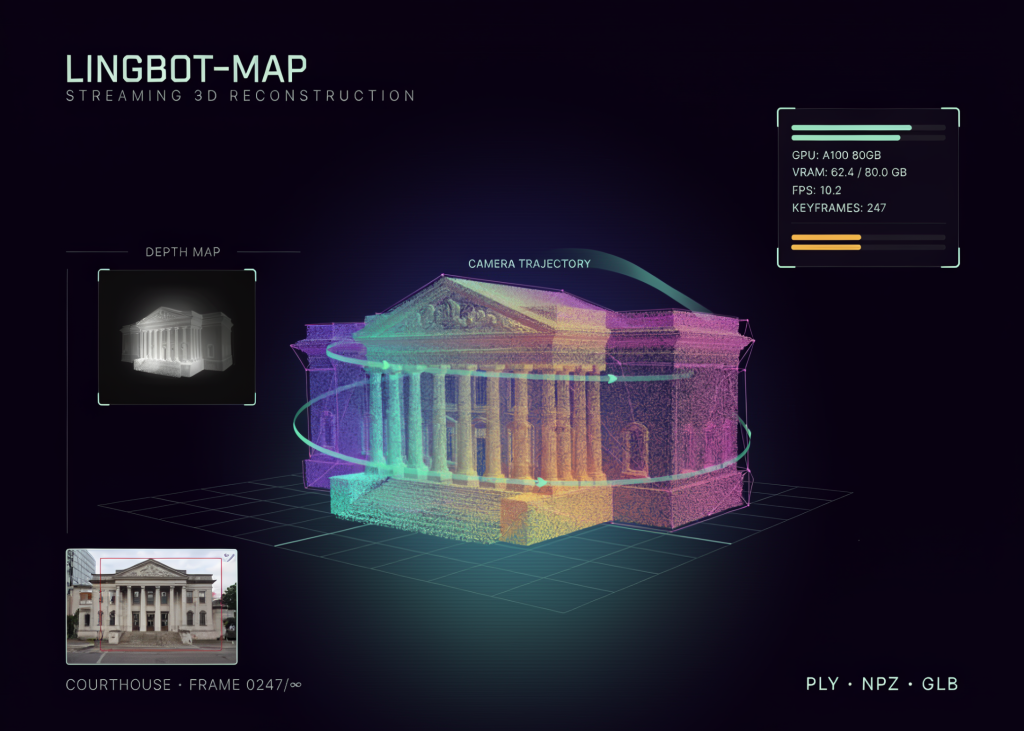
LingBot-Map Tutorial: GPU-Aware Inference and Point Cloud Export
In this tutorial, we implement an end-to-end streaming 3D reconstruction pipeline with LingBot-Map. We begin by configuring the input source, […]