
NVIDIA has released Audex (Nemotron-Labs-Audex-30B-A3B), a unified audio-text large language model. It understands and generates both audio and speech. It […]
Category: Software Engineering

Tencent Releases Hy3: An Open 295B Mixture-of-Experts (MoE) Model with 21B Active Parameters and 256K Context
Tencent’s Hy team released Hy3. Hy3 is a 295B-parameter Mixture-of-Experts (MoE) model. It activates only 21B parameters per token. The […]

OpenAI Releases GPT-Realtime-2.1 and GPT-Realtime-2.1-mini for Low-Latency Voice Agents in the API
OpenAI has released two new Realtime models in its API. They are named gpt-realtime-2.1 and gpt-realtime-2.1-mini. Both target low-latency voice […]

Sakana AI Launches Sakana Translate, a Namazu-Powered Japanese–English–Chinese Translation Tool With Translate, Proofread, and Ask Modes
Sakana AI has added a new feature called Sakana Translate to its chat service, Sakana Chat. It handles bidirectional translation […]

Meituan Releases LongCat-2.0: A 1.6T-Parameter Open MoE Model with Native 1M Context and LongCat Sparse Attention
Meituan has released LongCat-2.0, a large-scale Mixture-of-Experts (MoE) language model. It carries 1.6 trillion total parameters and activates about 48 […]

Structured PDF-to-JSON: A Guide to Open-Source Extraction Models in 2026
Most enterprise data still sits inside PDFs, scans, and slide decks. Large language models and agents cannot use that data […]

Anthropic Launches Claude Science Beta: A Multi-Agent AI Workbench for Reproducible Genomics, Proteomics, and Cheminformatics Pipelines
This week, Anthropic released Claude Science. It is an app for scientists, available in beta. It runs on Anthropic’s existing […]
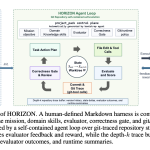
NVIDIA HORIZON: A Hands-Free Agent that Evolves Git Worktrees and Hits 100% RTL Benchmark Completion
NVIDIA Research introduced HORIZON, a hands-free agent framework for hardware design. It treats hardware design as repository-level code evolution. This […]

NVIDIA AI Introduces ASPIRE: A Self-Improving Robotics Framework Reaching 31% Zero-Shot on LIBERO-Pro Long Tasks
Traditional robot programming is hard to scale. It requires orchestrating multimodal perception, physical contact dynamics, diverse configurations, and execution failures […]

Mistral AI Releases Leanstral 1.5: An Apache-2.0 Lean 4 Code Agent Model Solving 587 of 672 PutnamBench Problems
Today, Mistral AI released Leanstral 1.5. It is a code agent model built for Lean 4. The release targets automated […]