
In this tutorial, we implement a reinforcement learning agent using RLax, a research-oriented library developed by Google DeepMind for building […]
Category: Reinforcement Learning
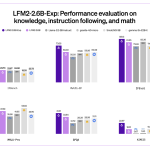
Liquid AI’s LFM2-2.6B-Exp Uses Pure Reinforcement Learning RL And Dynamic Hybrid Reasoning To Tighten Small Model Behavior
Liquid AI has introduced LFM2-2.6B-Exp, an experimental checkpoint of its LFM2-2.6B language model that is trained with pure reinforcement learning […]

How We Learn Step-Level Rewards from Preferences to Solve Sparse-Reward Environments Using Online Process Reward Learning
In this tutorial, we explore Online Process Reward Learning (OPRL) and demonstrate how we can learn dense, step-level reward signals […]

How to Build, Train, and Compare Multiple Reinforcement Learning Agents in a Custom Trading Environment Using Stable-Baselines3
In this tutorial, we explore advanced applications of Stable-Baselines3 in reinforcement learning. We design a fully functional, custom trading environment, […]
Sigmoidal Scaling Curves Make Reinforcement Learning RL Post-Training Predictable for LLMs
Reinforcement Learning RL post-training is now a major lever for reasoning-centric LLMs, but unlike pre-training, it hasn’t had predictive scaling […]

NVIDIA Researchers Propose Reinforcement Learning Pretraining (RLP): Reinforcement as a Pretraining Objective for Building Reasoning During Pretraining
NVIDIA AI has introduced Reinforcement Learning Pretraining (RLP), a training objective that injects reinforcement learning into the pretraining stage rather […]

MoonshotAI Released Checkpoint-Engine: A Simple Middleware to Update Model Weights in LLM Inference Engines, Effective for Reinforcement Learning
MoonshotAI has open-sourced checkpoint-engine, a lightweight middleware aimed at solving one of the key bottlenecks in large language model (LLM) […]

- AI
- AI alignment
- AI behavior
- AI deception
- AI ethics
- AI research
- AI safety
- ai safety testing
- AI security
- Alignment research
- Andrew Deck
- Anthropic
- Biz & IT
- Claude Opus 4
- Generative AI
- goal misgeneralization
- Jeffrey Ladish
- large language models
- Machine Learning
- o3 model
- openai
- Palisade Research
- Reinforcement Learning
- Technology
Is AI really trying to escape human control and blackmail people?
Mankind behind the curtain Opinion: Theatrical testing scenarios explain why AI models produce alarming outputs—and why we fall for it. […]

NVIDIA AI Releases ProRLv2: Advancing Reasoning in Language Models with Extended Reinforcement Learning RL
Table of contents What Is ProRLv2? Key Innovations in ProRLv2 How ProRLv2 Expands LLM Reasoning Why It Matters Using Nemotron-Research-Reasoning-Qwen-1.5B-v2 […]

How a big shift in training LLMs led to a capability explosion
Skip to content Reinforcement learning, explained with a minimum of math and jargon. Credit: Aurich Lawson | Getty Images Credit: […]