
Tencent’s Hy team released Hy3. Hy3 is a 295B-parameter Mixture-of-Experts (MoE) model. It activates only 21B parameters per token. The […]
Category: Machine Learning

OpenAI Releases GPT-Realtime-2.1 and GPT-Realtime-2.1-mini for Low-Latency Voice Agents in the API
OpenAI has released two new Realtime models in its API. They are named gpt-realtime-2.1 and gpt-realtime-2.1-mini. Both target low-latency voice […]

Building a Scaffold-Split Random Forest QSAR Co-Scientist for EGFR Inhibitor Discovery Using ChEMBL, RDKit, SHAP, and BRICS
In this tutorial, we build an end-to-end autonomous AI co-scientist workflow for next-generation EGFR inhibitor discovery, focusing on the C797S […]

Sakana AI Launches Sakana Translate, a Namazu-Powered Japanese–English–Chinese Translation Tool With Translate, Proofread, and Ask Modes
Sakana AI has added a new feature called Sakana Translate to its chat service, Sakana Chat. It handles bidirectional translation […]

Synthetic Sciences Releases OpenScience: An Open-Source, Model-Agnostic AI Workbench for Machine Learning, Biology, Physics, and Chemistry Research
Synthetic Sciences has released OpenScience, an open-source AI workbench for scientific research. It is licensed under Apache 2.0 and runs […]
Training Gemma-3 for Structured Mathematical Reasoning with Tunix GRPO, LoRA Adapters, and GSM8K Rewards
In this tutorial, we build an end-to-end GRPO training workflow that teaches Gemma-3 to reason through GSM8K math problems using […]
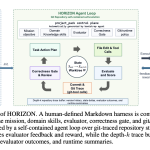
NVIDIA HORIZON: A Hands-Free Agent that Evolves Git Worktrees and Hits 100% RTL Benchmark Completion
NVIDIA Research introduced HORIZON, a hands-free agent framework for hardware design. It treats hardware design as repository-level code evolution. This […]

Mistral AI Releases Leanstral 1.5: An Apache-2.0 Lean 4 Code Agent Model Solving 587 of 672 PutnamBench Problems
Today, Mistral AI released Leanstral 1.5. It is a code agent model built for Lean 4. The release targets automated […]

Meet WebBrain: An Open-Source, Local-First AI Browser Agent That Reads Pages and Automates Tasks in Chrome and Firefox
WebBrain is a free, open-source browser agent for Chrome and Firefox. It reads pages, extracts data, and automates multi-step tasks. […]

Meet Alibaba’s Page Agent: A JavaScript In-Page GUI Agent That Controls Web Interfaces With Natural Language Through the DOM
Most browser automation runs from the outside. Playwright, Puppeteer, Selenium, and browser-use all drive a browser from an external process. […]