
An OpenAI spokesperson told Reuters that “an IPO is not our focus, so we could not possibly have set a […]
Category: AI infrastructure

Nvidia hits record $5 trillion mark as CEO dismisses AI bubble concerns
Partnerships and government contracts fuel optimism At the GTC conference on Tuesday, Nvidia’s CEO went out of his way to […]

Expert panel will determine AGI arrival in new Microsoft-OpenAI agreement
In May, OpenAI abandoned its plan to fully convert to a for-profit company after pressure from regulators and critics. The […]
Meet ‘kvcached’: A Machine Learning Library to Enable Virtualized, Elastic KV Cache for LLM Serving on Shared GPUs
Large language model serving often wastes GPU memory because engines pre-reserve large static KV cache regions per model, even when […]

Ars Live recap: Is the AI bubble about to pop? Ed Zitron weighs in.
Despite connection hiccups, we covered OpenAI’s finances, nuclear power, and Sam Altman. On Tuesday of last week, Ars Technica hosted […]

Nvidia sells tiny new computer that puts big AI on your desktop
On Tuesday, Nvidia announced it will begin taking orders for the DGX Spark, a $4,000 desktop AI computer that wraps […]

MoonshotAI Released Checkpoint-Engine: A Simple Middleware to Update Model Weights in LLM Inference Engines, Effective for Reinforcement Learning
MoonshotAI has open-sourced checkpoint-engine, a lightweight middleware aimed at solving one of the key bottlenecks in large language model (LLM) […]
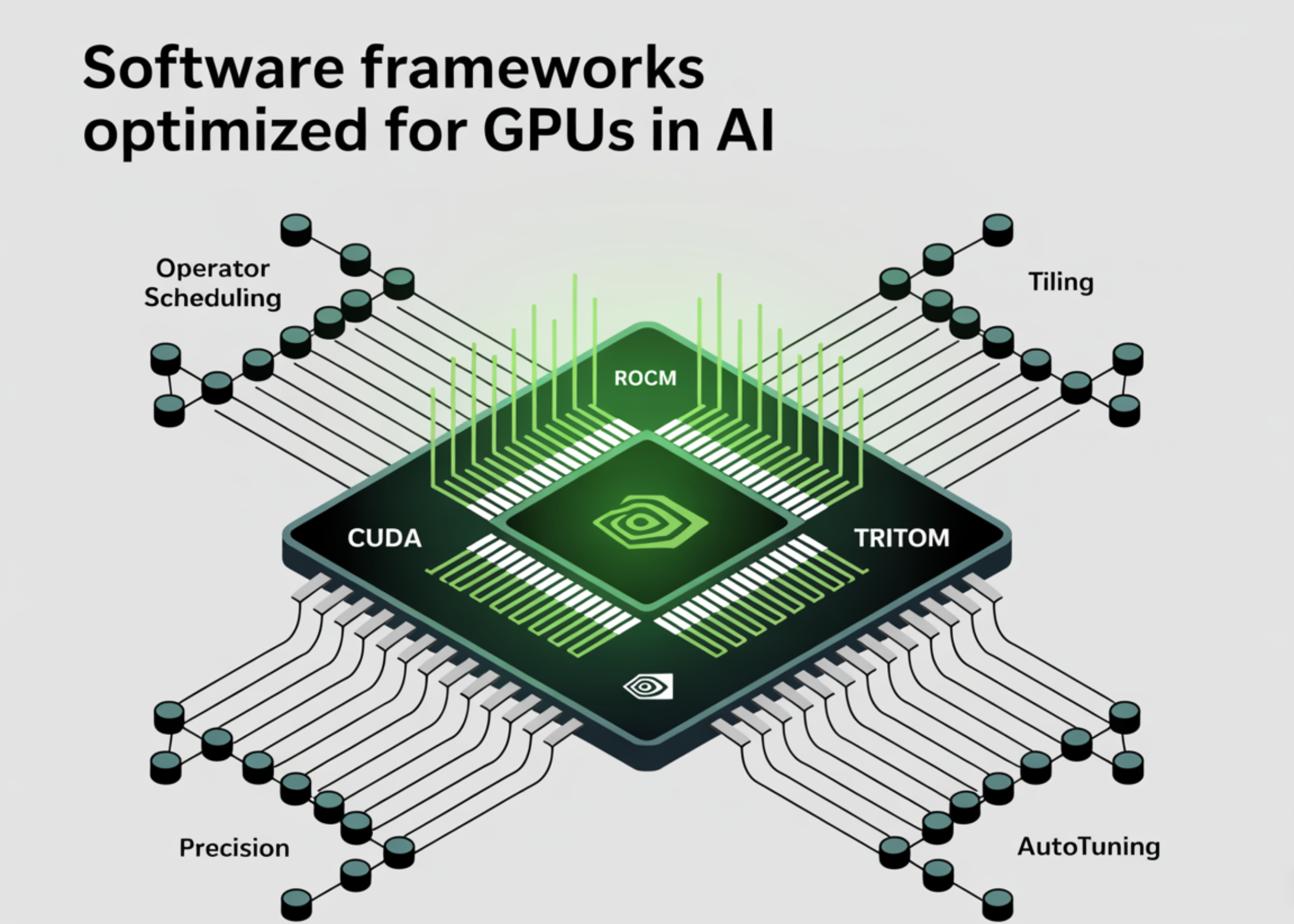
Software Frameworks Optimized for GPUs in AI: CUDA, ROCm, Triton, TensorRT—Compiler Paths and Performance Implications
Table of contents What actually determines performance on modern GPUs CUDA: nvcc/ptxas, cuDNN, CUTLASS, and CUDA Graphs ROCm: HIP/Clang toolchain, […]

Developers joke about “coding like cavemen” as AI service suffers major outage
Growing dependency on AI coding tools The speed at which news of the outage spread shows how deeply embedded AI […]

ParaThinker: Scaling LLM Test-Time Compute with Native Parallel Thinking to Overcome Tunnel Vision in Sequential Reasoning
Why Do Sequential LLMs Hit a Bottleneck? Test-time compute scaling in LLMs has traditionally relied on extending single reasoning paths. […]