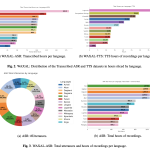
Speech technology still has a data distribution problem. Automatic Speech Recognition (ASR) and Text-to-Speech (TTS) systems have improved rapidly for […]
Category: Sound

Fish Audio Releases Fish Audio S2: A New Generation of Expressive Text-to-Speech (TTS) with Absurdly Controllable Emotion
The landscape of Text-to-Speech (TTS) is moving away from modular pipelines toward integrated Large Audio Models (LAMs). Fish Audio’s release […]

Qwen Researchers Release Qwen3-TTS: an Open Multilingual TTS Suite with Real-Time Latency and Fine-Grained Voice Control
Alibaba Cloud’s Qwen team has open-sourced Qwen3-TTS, a family of multilingual text-to-speech models that target three core tasks in one […]
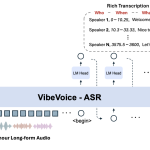
Microsoft Releases VibeVoice-ASR: A Unified Speech-to-Text Model Designed to Handle 60-Minute Long-Form Audio in a Single Pass
Microsoft has released VibeVoice-ASR as part of the VibeVoice family of open source frontier voice AI models. VibeVoice-ASR is described […]

FlashLabs Researchers Release Chroma 1.0: A 4B Real Time Speech Dialogue Model With Personalized Voice Cloning
Chroma 1.0 is a real time speech to speech dialogue model that takes audio as input and returns audio as […]

Inworld AI Releases TTS-1.5 For Realtime, Production Grade Voice Agents
Inworld AI has introduced Inworld TTS-1.5, an upgrade to its TTS-1 family that targets realtime voice agents with strict constraints […]

How to Design a Fully Streaming Voice Agent with End-to-End Latency Budgets, Incremental ASR, LLM Streaming, and Real-Time TTS
In this tutorial, we build an end-to-end streaming voice agent that mirrors how modern low-latency conversational systems operate in real […]
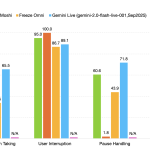
NVIDIA Releases PersonaPlex-7B-v1: A Real-Time Speech-to-Speech Model Designed for Natural and Full-Duplex Conversations
NVIDIA Researchers released PersonaPlex-7B-v1, a full duplex speech to speech conversational model that targets natural voice interactions with precise persona […]

Google Researchers Release Magenta RealTime: An Open-Weight Model for Real-Time AI Music Generation
Google’s Magenta team has introduced Magenta RealTime (Magenta RT), an open-weight, real-time music generation model that brings unprecedented interactivity to […]

Omni-R1: Advancing Audio Question Answering with Text-Driven Reinforcement Learning and Auto-Generated Data
Recent developments have shown that RL can significantly enhance the reasoning abilities of LLMs. Building on this progress, the study […]