
Alibaba has introduced Qwen3-MT (qwen-mt-turbo) via Qwen API, its latest and most advanced machine translation model, designed to break language barriers […]
Category: Audio Language Model
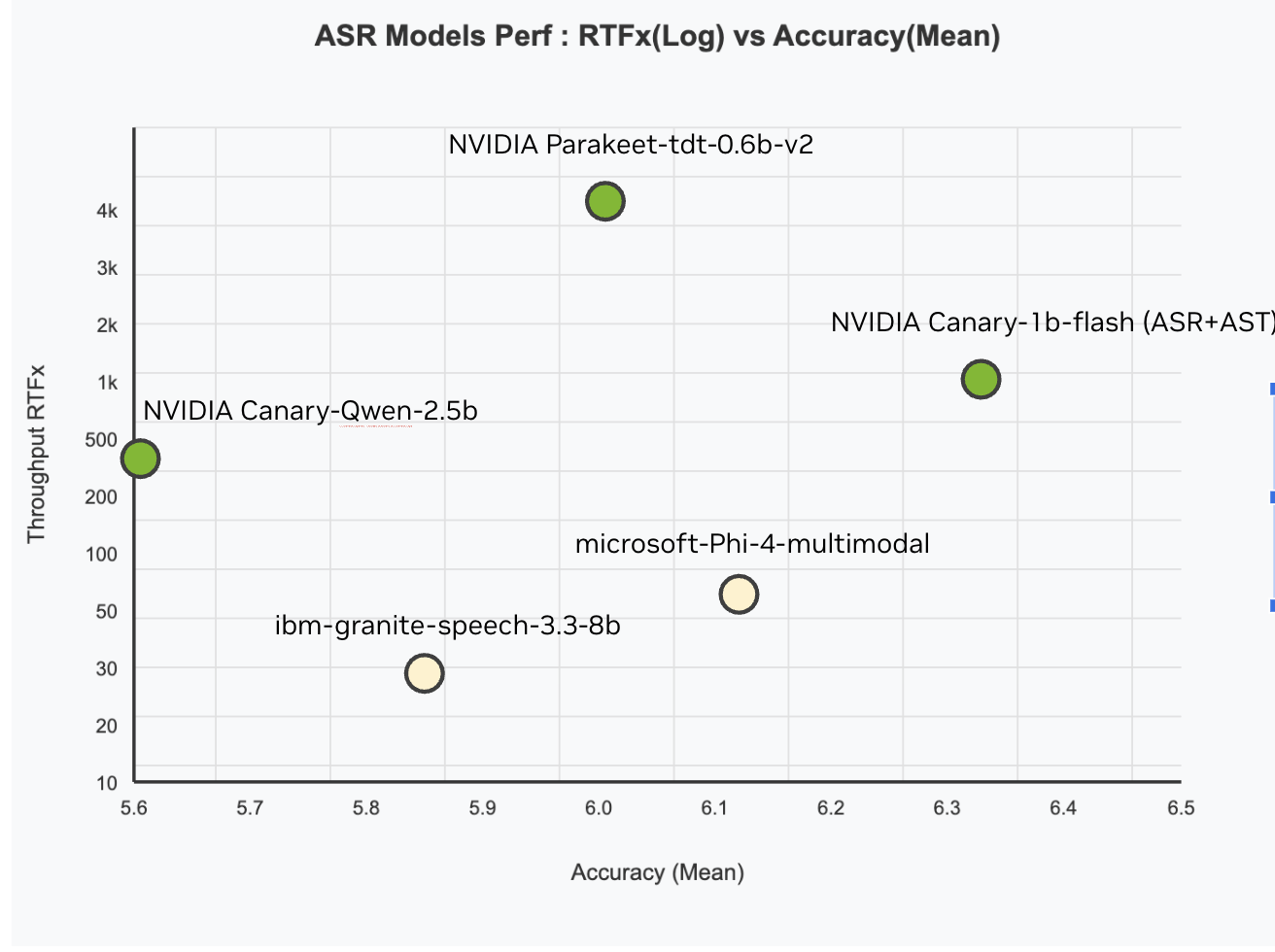
NVIDIA AI Releases Canary-Qwen-2.5B: A State-of-the-Art ASR-LLM Hybrid Model with SoTA Performance on OpenASR Leaderboard
NVIDIA has just released Canary-Qwen-2.5B, a groundbreaking automatic speech recognition (ASR) and language model (LLM) hybrid, which now tops the […]

Mistral AI Releases Voxtral: The World’s Best (and Open) Speech Recognition Models
Mistral AI has released Voxtral, a family of open-weight models—Voxtral-Small-24B and Voxtral-Mini-3B—designed to handle both audio and text inputs. Built […]

NVIDIA Just Released Audio Flamingo 3: An Open-Source Model Advancing Audio General Intelligence
Heard about Artificial General Intelligence (AGI)? Meet its auditory counterpart—Audio General Intelligence. With Audio Flamingo 3 (AF3), NVIDIA introduces a […]
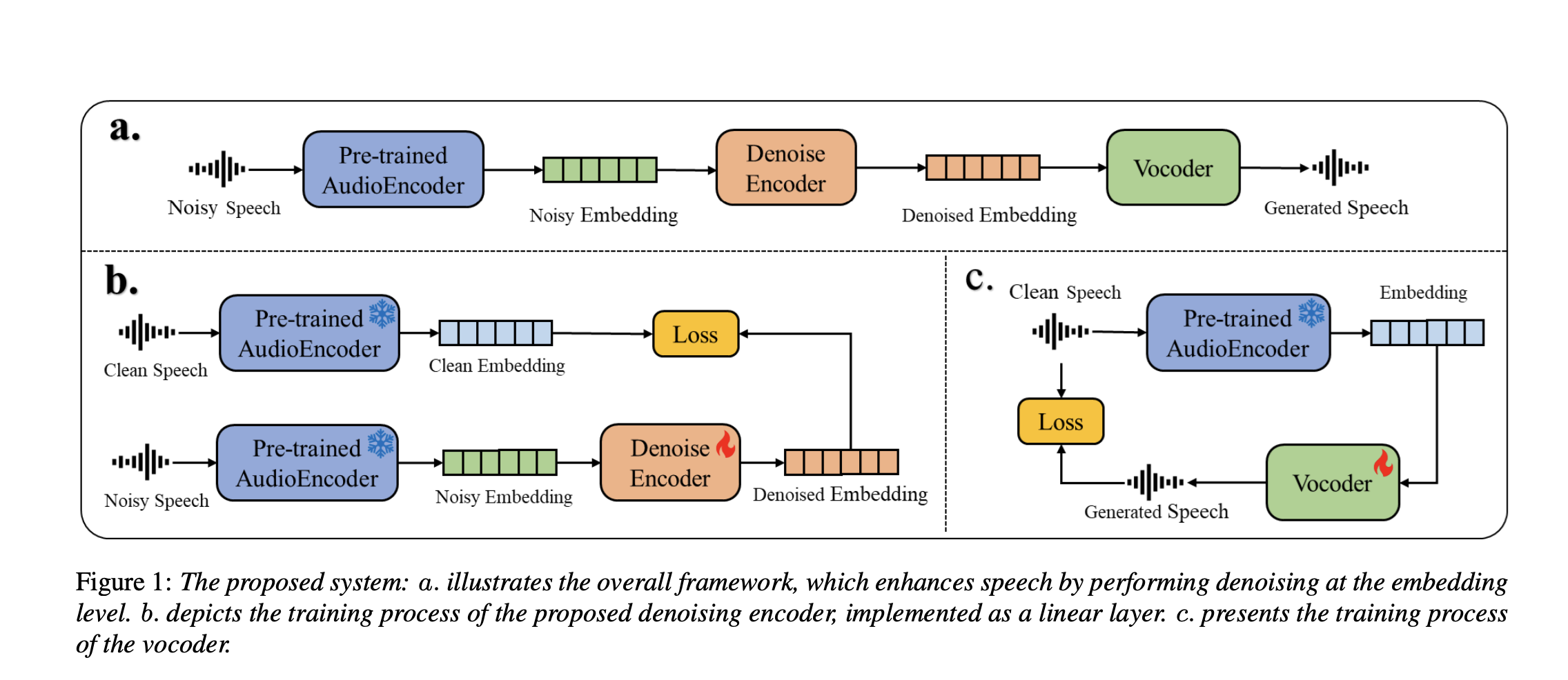
Efficient and Adaptable Speech Enhancement via Pre-trained Generative Audioencoders and Vocoders
Recent advances in speech enhancement (SE) have moved beyond traditional mask or signal prediction methods, turning instead to pre-trained audio […]
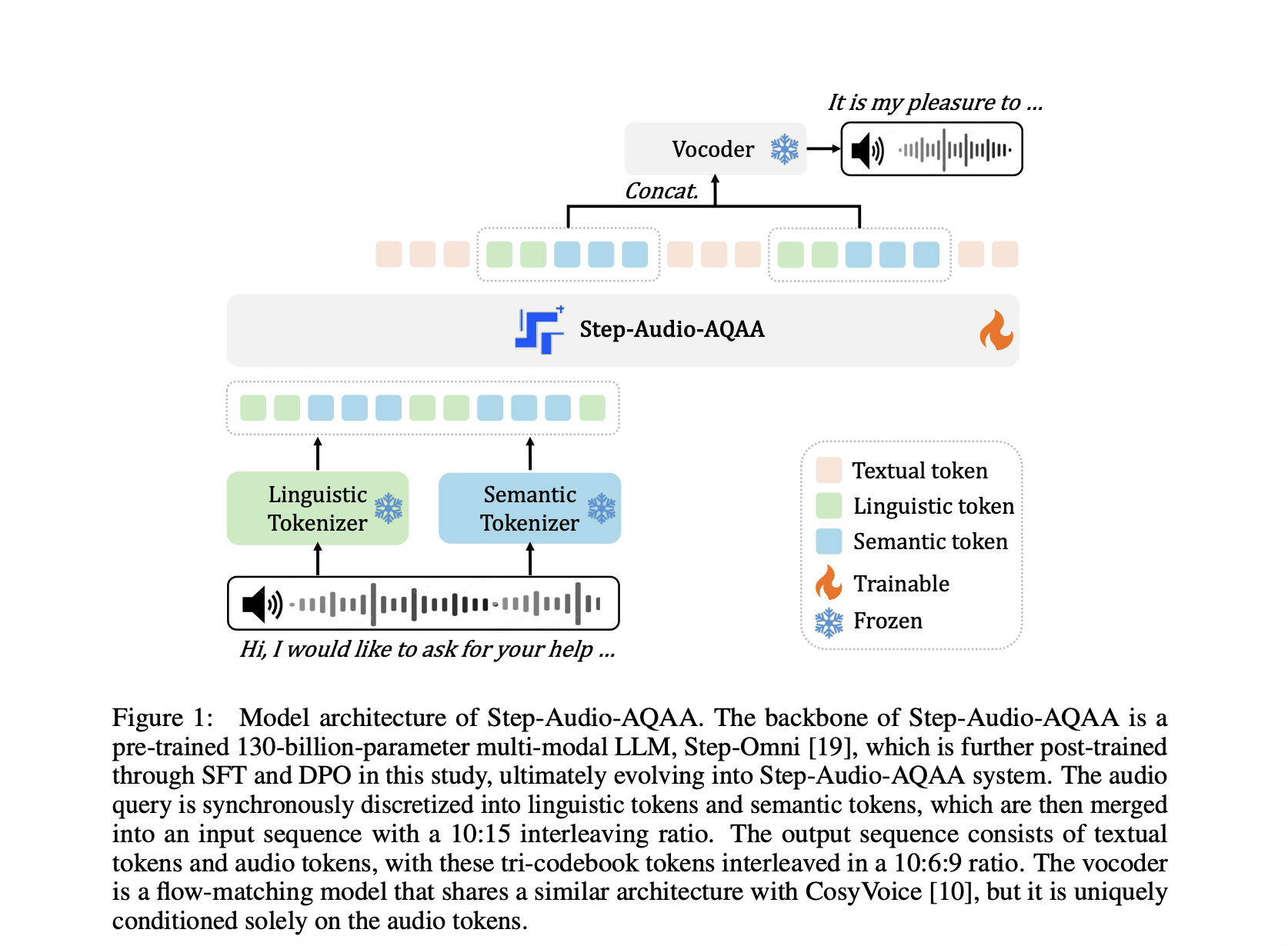
StepFun Introduces Step-Audio-AQAA: A Fully End-to-End Audio Language Model for Natural Voice Interaction
Rethinking Audio-Based Human-Computer Interaction Machines that can respond to human speech with equally expressive and natural audio have become a […]

NVIDIA Open Sources Parakeet TDT 0.6B: Achieving a New Standard for Automatic Speech Recognition ASR and Transcribes an Hour of Audio in One Second
NVIDIA has unveiled Parakeet TDT 0.6B, a state-of-the-art automatic speech recognition (ASR) model that is now fully open-sourced on Hugging […]
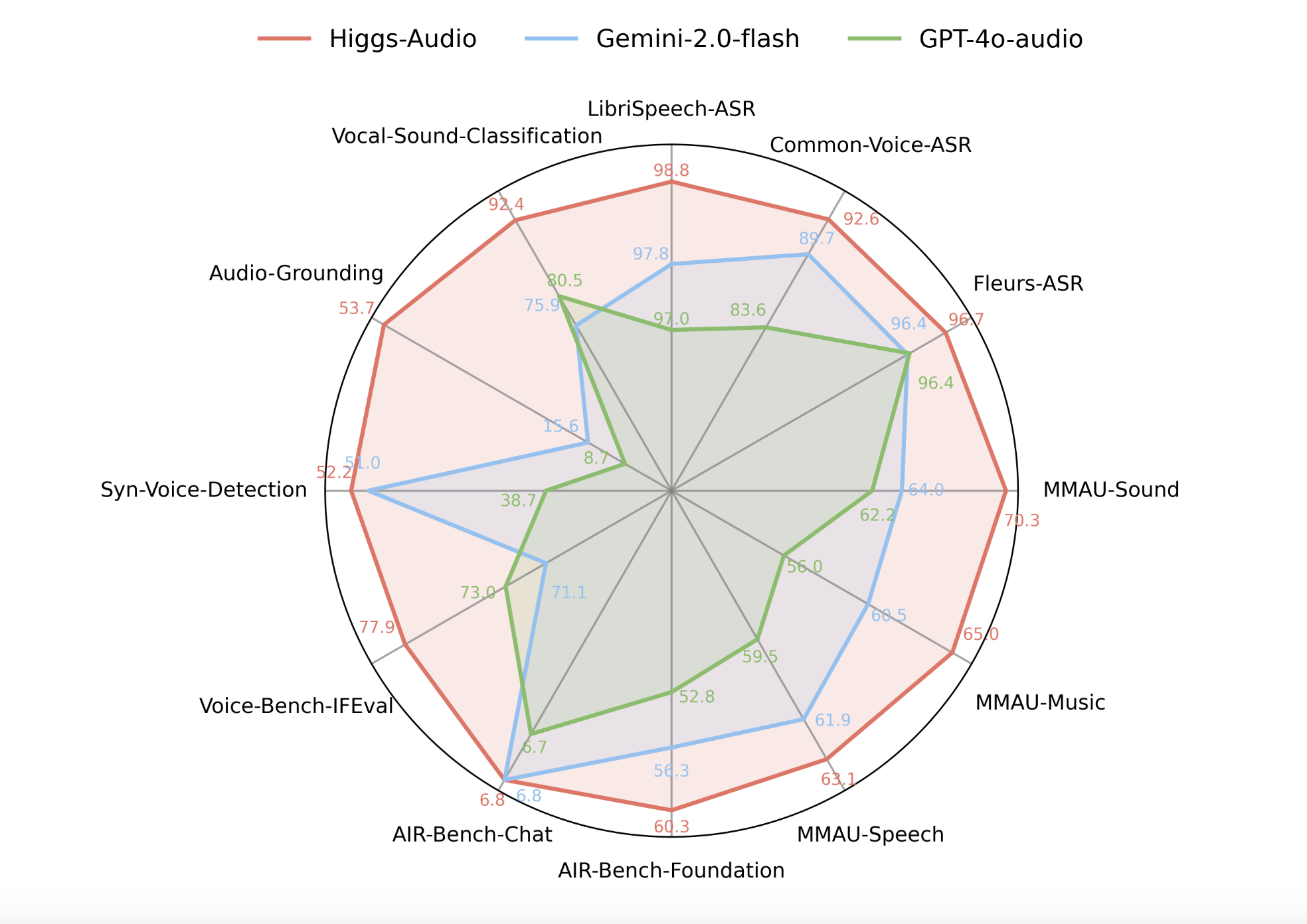
Boson AI Introduces Higgs Audio Understanding and Higgs Audio Generation: An Advanced AI Solution with Real-Time Audio Reasoning and Expressive Speech Synthesis for Enterprise Applications
In today’s enterprise landscape—especially in insurance and customer support —voice and audio data are more than just recordings; they’re valuable […]

Meta AI Just Released Llama 4 Scout and Llama 4 Maverick: The First Set of Llama 4 Models
Today, Meta AI announced the release of its latest generation multimodal models, Llama 4, featuring two variants: Llama 4 Scout […]

Zyphra Introduces the Beta Release of Zonos: A Highly Expressive TTS Model with High Fidelity Voice Cloning
Text-to-speech (TTS) technology has made significant strides in recent years, but challenges remain in creating natural, expressive, and high-fidelity speech […]