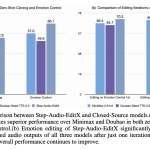
How can speech editing become as direct and controllable as simply rewriting a line of text? StepFun AI has open […]
Category: Audio Language Model
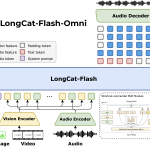
LongCat-Flash-Omni: A SOTA Open-Source Omni-Modal Model with 560B Parameters with 27B activated, Excelling at Real-Time Audio-Visual Interaction
How do you design a single model that can listen, see, read and respond in real time across text, image, […]

UT Austin and ServiceNow Research Team Releases AU-Harness: An Open-Source Toolkit for Holistic Evaluation of Audio LLMs
Voice AI is becoming one of the most important frontiers in multimodal AI. From intelligent assistants to interactive agents, the […]

Deepdub Introduces Lightning 2.5: A Real-Time AI Voice Model With 2.8x Throughput Gains for Scalable AI Agents and Enterprise AI
Deepdub, an Israeli Voice AI startup, has introduced Lightning 2.5, a real-time foundational voice model designed to power scalable, production-grade […]
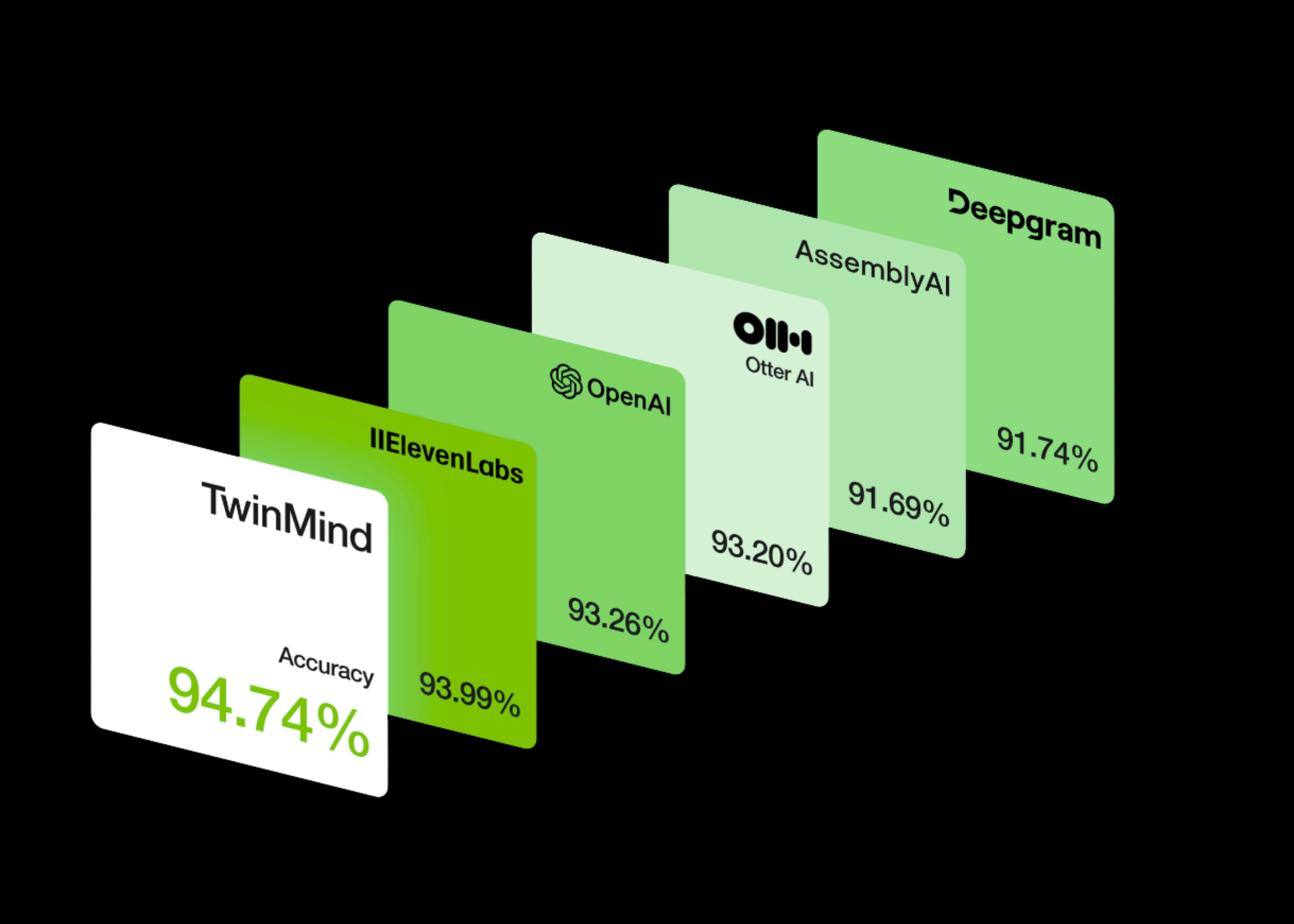
TwinMind Introduces Ear-3 Model: A New Voice AI Model that Sets New Industry Records in Accuracy, Speaker Labeling, Languages and Price
TwinMind, a California-based Voice AI startup, unveiled Ear-3 speech-recognition model, claiming state-of-the-art performance on several key metrics and expanded multilingual […]

Alibaba Qwen Team Releases Qwen3-ASR: A New Speech Recognition Model Built Upon Qwen3-Omni Achieving Robust Speech Recogition Performance
Alibaba Cloud’s Qwen team unveiled Qwen3-ASR Flash, an all-in-one automatic speech recognition (ASR) model (available as API service) built upon […]

Microsoft AI Lab Unveils MAI-Voice-1 and MAI-1-Preview: New In-House Models for Voice AI
Microsoft AI lab officially launched MAI-Voice-1 and MAI-1-preview, marking a new phase for the company’s artificial intelligence research and development […]
OpenAI Releases an Advanced Speech-to-Speech Model and New Realtime API Capabilities including MCP Server Support, Image Input, and SIP Phone Calling Support
OpenAI has officially launched Realtime API and gpt-realtime, its most advanced speech-to-speech model, moving the Realtime API out of beta […]

NVIDIA AI Just Released Streaming Sortformer: A Real-Time Speaker Diarization that Figures Out Who’s Talking in Meetings and Calls Instantly
NVIDIA has released its Streaming Sortformer, a breakthrough in real-time speaker diarization that instantly identifies and labels participants in meetings, […]

NVIDIA AI Just Released the Largest Open-Source Speech AI Dataset and State-of-the-Art Models for European Languages
Nvidia has taken a major leap in the development of multilingual speech AI, unveiling Granary, the largest open-source speech dataset […]