At first glance, adding more features to a model seems like an obvious way to improve performance. If a model […]
Category: Artificial Intelligence

How to Build Progress Monitoring Using Advanced tqdm for Async, Parallel, Pandas, Logging, and High-Performance Workflows
In this tutorial, we explore tqdm in depth and demonstrate how we build powerful, real-time progress tracking into modern Python […]

Yann LeCun’s New AI Paper Argues AGI Is Misdefined and Introduces Superhuman Adaptable Intelligence (SAI) Instead
What if the AI industry is optimizing for a goal that cannot be clearly defined or reliably measured? That is […]

Google Launches TensorFlow 2.21 And LiteRT: Faster GPU Performance, New NPU Acceleration, And Seamless PyTorch Edge Deployment Upgrades
Google has officially released TensorFlow 2.21. The most significant update in this release is the graduation of LiteRT from its […]

Microsoft Releases Phi-4-Reasoning-Vision-15B: A Compact Multimodal Model for Math, Science, and GUI Understanding
Microsoft has released Phi-4-reasoning-vision-15B, a 15 billion parameter open-weight multimodal reasoning model designed for image and text tasks that require […]

Google’s new command-line tool can plug OpenClaw into your Workspace data
The command line is hot again. For some people, command lines were never not hot, of course, but it’s becoming […]

Microsoft is working to add a screenshot tool to Copilot in Windows 11
Having invested so much time, money and effort in Copilot, it would seem obvious that Microsoft is not giving up […]
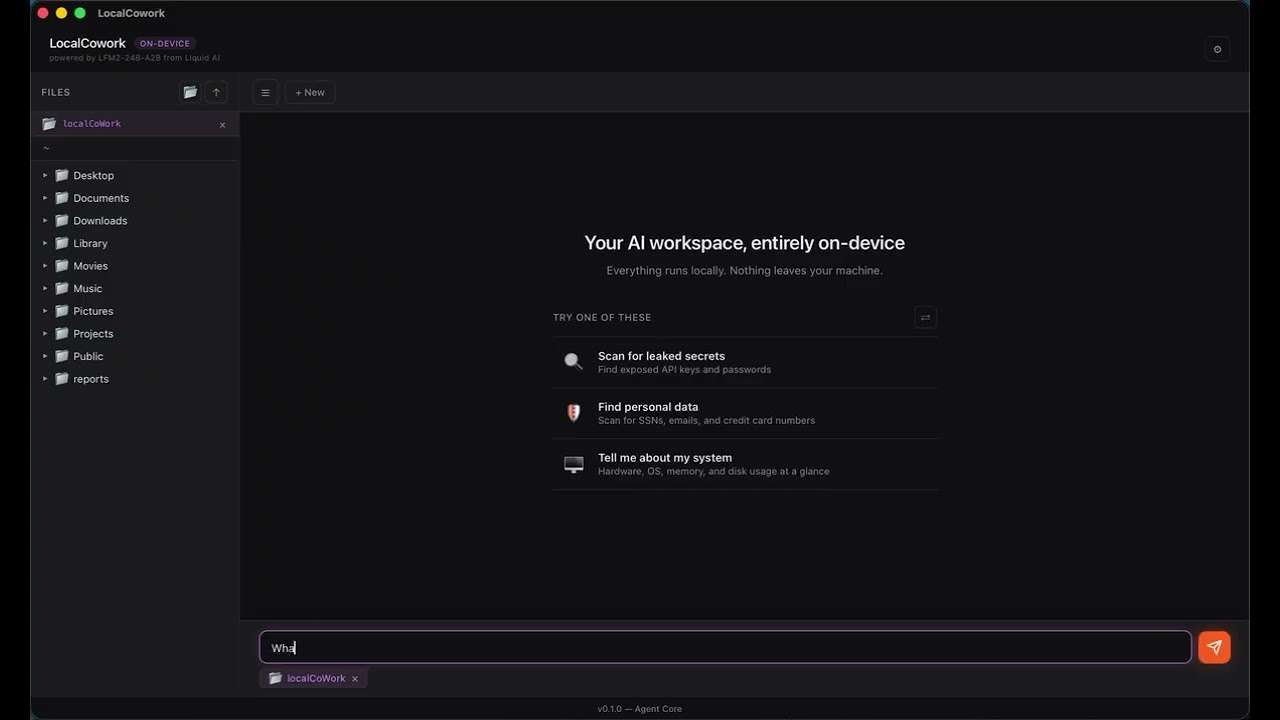
Liquid AI Releases LocalCowork Powered By LFM2-24B-A2B to Execute Privacy-First Agent Workflows Locally Via Model Context Protocol (MCP)
Liquid AI has released LFM2-24B-A2B, a model optimized for local, low-latency tool dispatch, alongside LocalCowork, an open-source desktop agent application […]

A Coding Guide to Build a Scalable End-to-End Machine Learning Data Pipeline Using Daft for High-Performance Structured and Image Data Processing
In this tutorial, we explore how we use Daft as a high-performance, Python-native data engine to build an end-to-end analytical […]

Apple Music is adding new metadata to increase transparency about AI usage
With many people loving the use of AI in creative endeavors and many hating it, the way forward would seem […]