
Serving Large Language Models (LLMs) at scale is a massive engineering challenge because of Key-Value (KV) cache management. As models […]
Category: AI Shorts

Google AI Introduces Natively Adaptive Interfaces (NAI): An Agentic Multimodal Accessibility Framework Built on Gemini for Adaptive UI Design
Google Research is proposing a new way to build accessible software with Natively Adaptive Interfaces (NAI), an agentic framework where […]
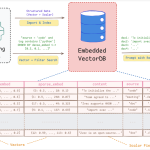
Alibaba Open-Sources Zvec: An Embedded Vector Database Bringing SQLite-like Simplicity and High-Performance On-Device RAG to Edge Applications
Alibaba Tongyi Lab research team released ‘Zvec’, an open source, in-process vector database that targets edge and on-device retrieval workloads. […]
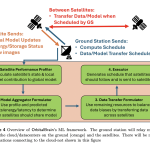
Microsoft AI Proposes OrbitalBrain: Enabling Distributed Machine Learning in Space with Inter-Satellite Links and Constellation-Aware Resource Optimization Strategies
Earth observation (EO) constellations capture huge volumes of high-resolution imagery every day, but most of it never reaches the ground […]

Google AI Introduces PaperBanana: An Agentic Framework that Automates Publication Ready Methodology Diagrams and Statistical Plots
Generating publication-ready illustrations is a labor-intensive bottleneck in the research workflow. While AI scientists can now handle literature reviews and […]

NVIDIA AI releases C-RADIOv4 vision backbone unifying SigLIP2, DINOv3, SAM3 for classification, dense prediction, segmentation workloads at scale
How do you combine SigLIP2, DINOv3, and SAM3 into a single vision backbone without sacrificing dense or segmentation performance? NVIDIA’s […]

Waymo Introduces the Waymo World Model: A New Frontier Simulator Model for Autonomous Driving and Built on Top of Genie 3
Waymo is introducing the Waymo World Model, a frontier generative model that drives its next generation of autonomous driving simulation. […]
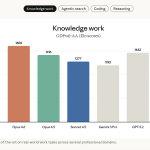
Anthropic Releases Claude Opus 4.6 With 1M Context, Agentic Coding, Adaptive Reasoning Controls, and Expanded Safety Tooling Capabilities
Anthropic has launched Claude Opus 4.6, its most capable model to date, focused on long-context reasoning, agentic coding, and high-value […]

Qwen Team Releases Qwen3-Coder-Next: An Open-Weight Language Model Designed Specifically for Coding Agents and Local Development
Qwen team has just released Qwen3-Coder-Next, an open-weight language model designed for coding agents and local development. It sits on […]

NVIDIA AI Brings Nemotron-3-Nano-30B to NVFP4 with Quantization Aware Distillation (QAD) for Efficient Reasoning Inference
NVIDIA has released Nemotron-Nano-3-30B-A3B-NVFP4, a production checkpoint that runs a 30B parameter reasoning model in 4 bit NVFP4 format while […]