
Google Research team has announced the launch of Gemini-SQL2 on X. They described this system as a breakthrough text-to-SQL capability […]
Category: Databases

Upstash for Redis vs Supabase vs Neon: Which One Fits Vibe Coding Workflows in 2026?
The short answer most comparison articles skip: these three tools are not competing for the same job. Before picking one, […]

Twin brothers wipe 96 gov’t databases minutes after being fired
“Yeah, they could,” Sohaib agreed. Muneeb noted that an employee they knew would “have some work to do” when the […]

Best Vector Databases in 2026: Pricing, Scale Limits, and Architecture Tradeoffs Across Nine Leading Systems
Vector databases have graduated from experimental tooling to mission-critical infrastructure. In 2026, vector databases serve as the core retrieval layer […]

An Implementation Guide to Building a DuckDB-Python Analytics Pipeline with SQL, DataFrames, Parquet, UDFs, and Performance Profiling
In this tutorial, we build a comprehensive, hands-on understanding of DuckDB-Python by working through its features directly in code on […]

Meet OpenViking: An Open-Source Context Database that Brings Filesystem-Based Memory and Retrieval to AI Agent Systems like OpenClaw
OpenViking is an open-source Context Database for AI Agents from Volcengine. The project is built around a simple architectural concept: […]
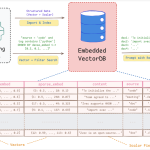
Alibaba Open-Sources Zvec: An Embedded Vector Database Bringing SQLite-like Simplicity and High-Performance On-Device RAG to Edge Applications
Alibaba Tongyi Lab research team released ‘Zvec’, an open source, in-process vector database that targets edge and on-device retrieval workloads. […]

A Coding, Data-Driven Guide to Measuring, Visualizing, and Enforcing Cognitive Complexity in Python Projects Using complexipy
In this tutorial, we build an end-to-end cognitive complexity analysis workflow using complexipy. We start by measuring complexity directly from […]

How to Build Production-Grade Data Validation Pipelines Using Pandera, Typed Schemas, and Composable DataFrame Contracts
Schemas, and Composable DataFrame ContractsIn this tutorial, we demonstrate how to build robust, production-grade data validation pipelines using Pandera with […]

How to Build Portable, In-Database Feature Engineering Pipelines with Ibis Using Lazy Python APIs and DuckDB Execution
In this tutorial, we demonstrate how we use Ibis to build a portable, in-database feature engineering pipeline that looks and […]