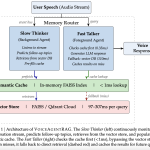
In the world of voice AI, the difference between a helpful assistant and an awkward interaction is measured in milliseconds. […]
Category: AI Paper Summary
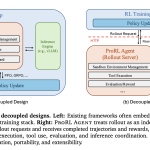
NVIDIA AI Unveils ProRL Agent: A Decoupled Rollout-as-a-Service Infrastructure for Reinforcement Learning of Multi-Turn LLM Agents at Scale
NVIDIA researchers introduced ProRL AGENT, a scalable infrastructure designed for reinforcement learning (RL) training of multi-turn LLM agents. By adopting […]

Meta Releases TRIBE v2: A Brain Encoding Model That Predicts fMRI Responses Across Video, Audio, and Text Stimuli
Neuroscience has long been a field of divide and conquer. Researchers typically map specific cognitive functions to isolated brain regions—like […]

NVIDIA AI Introduces PivotRL: A New AI Framework Achieving High Agentic Accuracy With 4x Fewer Rollout Turns Efficiently
Post-training Large Language Models (LLMs) for long-horizon agentic tasks—such as software engineering, web browsing, and complex tool use—presents a persistent […]
Google Introduces TurboQuant: A New Compression Algorithm that Reduces LLM Key-Value Cache Memory by 6x and Delivers Up to 8x Speedup, All with Zero Accuracy Loss
The scaling of Large Language Models (LLMs) is increasingly constrained by memory communication overhead between High-Bandwidth Memory (HBM) and SRAM. […]
This AI Paper Introduces TinyLoRA, A 13-Parameter Fine-Tuning Method That Reaches 91.8 Percent GSM8K on Qwen2.5-7B
Researchers from FAIR at Meta, Cornell University, and Carnegie Mellon University have demonstrated that large language models (LLMs) can learn […]
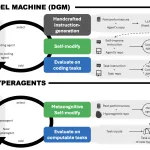
Meta AI’s New Hyperagents Don’t Just Solve Tasks—They Rewrite the Rules of How They Learn
The dream of recursive self-improvement in AI—where a system doesn’t just get better at a task, but gets better at […]
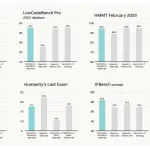
NVIDIA Releases Nemotron-Cascade 2: An Open 30B MoE with 3B Active Parameters, Delivering Better Reasoning and Strong Agentic Capabilities
NVIDIA has announced the release of Nemotron-Cascade 2, an open-weight 30B Mixture-of-Experts (MoE) model with 3B activated parameters. The model […]

Meet Mamba-3: A New State Space Model Frontier with 2x Smaller States and Enhanced MIMO Decoding Hardware Efficiency
The scaling of inference-time compute has become a primary driver for Large Language Model (LLM) performance, shifting architectural focus toward […]
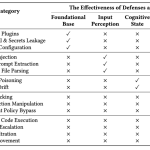
Tsinghua and Ant Group Researchers Unveil a Five-Layer Lifecycle-Oriented Security Framework to Mitigate Autonomous LLM Agent Vulnerabilities in OpenClaw
Autonomous LLM agents like OpenClaw are shifting the paradigm from passive assistants to proactive entities capable of executing complex, long-horizon […]