
Google has officially released TensorFlow 2.21. The most significant update in this release is the graduation of LiteRT from its […]
Category: AI

Microsoft Releases Phi-4-Reasoning-Vision-15B: A Compact Multimodal Model for Math, Science, and GUI Understanding
Microsoft has released Phi-4-reasoning-vision-15B, a 15 billion parameter open-weight multimodal reasoning model designed for image and text tasks that require […]

A Production-Style NetworKit 11.2.1 Coding Tutorial for Large-Scale Graph Analytics, Communities, Cores, and Sparsification
In this tutorial, we implement a production-grade, large-scale graph analytics pipeline in NetworKit, focusing on speed, memory efficiency, and version-safe […]

OpenAI Introduces Codex Security in Research Preview for Context-Aware Vulnerability Detection, Validation, and Patch Generation Across Codebases
OpenAI has introduced Codex Security, an application security agent that analyzes a codebase, validates likely vulnerabilities, and proposes fixes that […]

Google’s new command-line tool can plug OpenClaw into your Workspace data
The command line is hot again. For some people, command lines were never not hot, of course, but it’s becoming […]

Google AI Releases Android Bench: An Evaluation Framework and Leaderboard for LLMs in Android Development
Google has officially released Android Bench, a new leaderboard and evaluation framework designed to measure how Large Language Models (LLMs) […]

Musk fails to block California data disclosure law he fears will ruin xAI
Musk can’t convince judge public doesn’t care about where AI training data comes from. Elon Musk’s xAI has lost its […]

AI startup sues ex-CEO, saying he took 41GB of email and lied on résumé
Per the 21-page civil complaint, the saga began in early 2024, when Carson is said to have surreptitiously sold over […]

Microsoft is working to add a screenshot tool to Copilot in Windows 11
Having invested so much time, money and effort in Copilot, it would seem obvious that Microsoft is not giving up […]
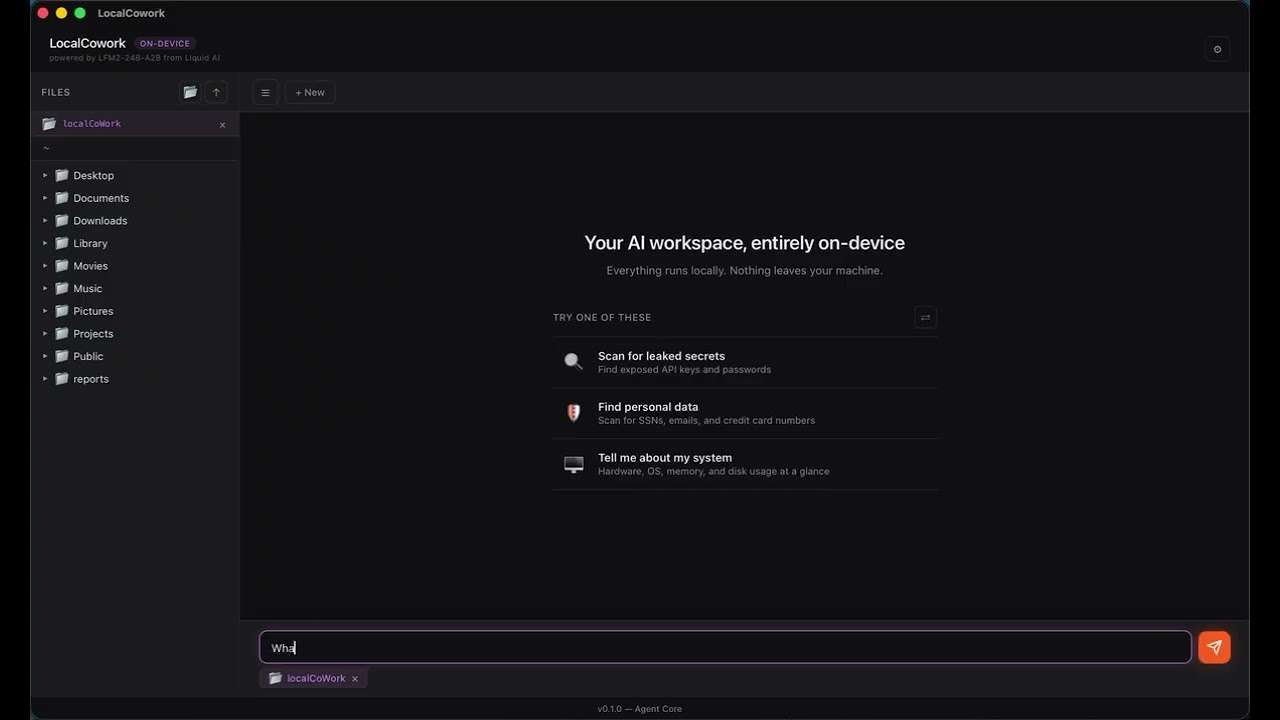
Liquid AI Releases LocalCowork Powered By LFM2-24B-A2B to Execute Privacy-First Agent Workflows Locally Via Model Context Protocol (MCP)
Liquid AI has released LFM2-24B-A2B, a model optimized for local, low-latency tool dispatch, alongside LocalCowork, an open-source desktop agent application […]