NVIDIA has released Nemotron-Labs-TwoTower, a diffusion language model built on a pretrained autoregressive backbone. It ships as open weights under the NVIDIA Nemotron Open Model License. The release targets a throughput bottleneck in text generation.
Autoregressive (AR) models decode one token at a time. That serial process caps generation throughput. Discrete diffusion language models take another route. They generate tokens in parallel and refine them iteratively.
Most diffusion language models use one network for two jobs. It represents clean tokens and denoises corrupted ones at every step. TwoTower separates these jobs into two towers. It keeps 98.7% of the AR baseline’s aggregate benchmark quality. It also reports 2.42× higher wall-clock generation throughput.
TL;DR
- TwoTower splits diffusion into a frozen AR context tower and a trained denoiser tower.
- It retains 98.7% of AR quality at 2.42× throughput (γ=0.8, S=16, 2×H100).
- The denoiser trained on ~2.1T tokens; the backbone used 25T.
- One checkpoint runs diffusion, mock-AR, and AR decoding modes.
TwoTower is a block-wise autoregressive diffusion model. It is instantiated on Nemotron-3-Nano-30B-A3B, an open-weight hybrid backbone. That backbone interleaves Mamba-2, self-attention, and mixture-of-experts (MoE) layers.
Each tower has 52 layers: 23 Mamba-2, 6 self-attention, and 23 MoE. The released checkpoint ships both towers, roughly 60B total parameters. Active parameters per token are about 3B per tower. The MoE uses 128 routable experts, of which 6 activate, plus 2 shared experts.
Both towers start as copies of the same backbone checkpoint. Only the denoiser tower is trained. The AR context tower stays frozen. The denoiser was trained on ~2.1T tokens, a fraction of the backbone’s 25T-token pretraining.
How the Two Towers Work
The AR context tower runs causally over the prompt and committed tokens. It produces per-layer KV cache and final Mamba-2 states. It preserves the backbone’s autoregressive capability.
The diffusion denoiser tower refines noisy blocks. Within a block, it uses bidirectional in-block attention. It stays causal with respect to past clean blocks.
The towers connect layer-by-layer. Denoiser layer i cross-attends to context tower layer i. This layer-aligned cross-attention gives multi-scale access to the backbone’s representations. Prior approaches broadcast only the last hidden state.
Two more denoiser modifications matter. Mamba-2 layers seed their initial state from the context tower’s Mamba state. The diffusion timestep modulates each layer through adaLN-single time conditioning. That adaLN module adds only ~1.5M parameters.
Generation runs block by block. Each block starts as S [MASK] tokens. The denoiser refines it over T steps, then commits it. The context tower then processes committed tokens to update its caches.
This explains why multiple denoising steps can still beat one-token decoding. Autoregressive decoding commits exactly one token per step. TwoTower commits multiple tokens per step early in refinement.
Benchmarks
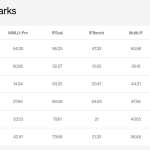
Evaluations use BF16 on 2×H100 GPUs. The default operating point is confidence unmasking, threshold γ=0.8, block size S=16. The table compares the AR baseline against TwoTower diffusion decoding.
| Task | Nemotron-3-Nano-30B-A3B (AR) | Nemotron-Labs-TwoTower (diffusion) |
|---|---|---|
| MMLU (5-shot, acc) | 78.56 | 78.24 |
| MMLU-Pro (5-shot, CoT EM) | 62.59 | 60.93 |
| ARC-Challenge (25-shot, acc_norm) | 91.72 | 92.66 |
| WinoGrande (5-shot, acc) | 76.09 | 76.09 |
| RACE (0-shot, acc) | 88.90 | 88.90 |
| HumanEval (0-shot) | 79.27 | 75.58 |
| MBPP-Sanitized (3-shot) | 74.71 | 74.28 |
| GSM8K (8-shot, acc) | 92.49 | 90.14 |
| MATH-500 (4-shot) | 84.40 | 80.60 |
| MMLU Global Lite (5-shot) | 73.97 | 73.94 |
| MGSM (8-shot, avg acc) | 80.80 | 80.40 |
| Quality retained | 100% | 98.7% |
| Generation throughput (× AR) | 1.0× | 2.42× |
General knowledge stays within about one point of the AR baseline. Code and math show modest degradation. Commonsense and multilingual scores are recovered or slightly improved. Lowering γ commits more tokens per step and raises throughput, with reduced quality.
Running It: Three Generation Modes
The checkpoint exposes three inference paths. Full two-tower diffusion uses 2 GPUs, about 59GB per GPU in BF16. AR-only mode runs on a single 80GB GPU.
import torch from transformers import AutoTokenizer, AutoModelForCausalLM model_name = "nvidia/Nemotron-Labs-TwoTower-30B-A3B-Base-BF16" tokenizer = AutoTokenizer.from_pretrained(model_name) model = AutoModelForCausalLM.from_pretrained( model_name, torch_dtype=torch.bfloat16, trust_remote_code=True, ) # context tower -> GPU 0, denoiser tower -> GPU 1 model.place_towers_on_devices("cuda:0", "cuda:1") model.eval() prompt = "France is a country " inputs = tokenizer(prompt, return_tensors="pt").to("cuda:0") outputs = model.generate_mask_diffusion( inputs["input_ids"], max_new_tokens=128, block_size=16, steps_per_block=16, mask_token_id=3, temperature=0.1, confidence_threshold=0.8, eos_token_id=tokenizer.eos_token_id, ) print(tokenizer.decode(outputs[0][inputs["input_ids"].shape[1]:], skip_special_tokens=True))The three modes are generate_mask_diffusion(), generate_mock_ar(), and generate_ar(). Mask diffusion commits up to block_size tokens per step. Mock-AR and AR commit one token per step.
Where It Fits: Use Cases
The most direct use case is faster batch generation. A data team producing synthetic text can trade a small quality drop for throughput. At γ=0.8, that trade is 1.3% quality for 2.42× speed.
A second use case is tuning the quality–throughput trade-off. Raising γ preserves more quality, as per the NVIDIA’s paper. Lowering γ commits more tokens per step for speed.
A third use case is drop-in adaptation. The context tower keeps its LM head for speculative decoding, verification, or AR scoring. Teams can run AR and diffusion from one checkpoint.
Strengths and Weaknesses
Strengths:
- Open weights under the NVIDIA Nemotron Open Model License; ready for commercial use
- 98.7% of AR quality retained at 2.42× throughput at the default operating point
- One checkpoint supports diffusion, mock-AR, and AR decoding
- Denoiser trained on ~2.1T tokens, not a full re-pretrain
- Sequence-length cache memory scales like the AR baseline
Weaknesses:
- Full two-tower diffusion needs 2 GPUs and ~59GB per GPU in BF16
- Code and math degrade more than general knowledge (HumanEval 79.27 → 75.58)
- Keeping both towers resident raises the fixed model-weight memory footprint
- Released checkpoint is a base model, before instruction tuning or alignment
- Throughput past 3× comes with larger quality loss
Interactive Explainer
Check out the Paper and Weights. Also, feel free to follow us on Twitter and don’t forget to join our 150k+ML SubReddit and Subscribe to our Newsletter. Wait! are you on telegram? now you can join us on telegram as well.
Need to partner with us for promoting your GitHub Repo OR Hugging Face Page OR Product Release OR Webinar etc.? Connect with us