Puzzle-based experiments reveal limitations of simulated reasoning, but others dispute findings.
An illustration of Tower of Hanoi from Popular Science in 1885. Credit: Public Domain
In early June, Apple researchers released a study suggesting that simulated reasoning (SR) models, such as OpenAI’s o1 and o3, DeepSeek-R1, and Claude 3.7 Sonnet Thinking, produce outputs consistent with pattern-matching from training data when faced with novel problems requiring systematic thinking. The researchers found similar results to a recent study by the United States of America Mathematical Olympiad (USAMO) in April, showing that these same models achieved low scores on novel mathematical proofs.
The new study, titled “The Illusion of Thinking: Understanding the Strengths and Limitations of Reasoning Models via the Lens of Problem Complexity,” comes from a team at Apple led by Parshin Shojaee and Iman Mirzadeh, and it includes contributions from Keivan Alizadeh, Maxwell Horton, Samy Bengio, and Mehrdad Farajtabar.
The researchers examined what they call “large reasoning models” (LRMs), which attempt to simulate a logical reasoning process by producing a deliberative text output sometimes called “chain-of-thought reasoning” that ostensibly assists with solving problems in a step-by-step fashion.
To do that, they pitted the AI models against four classic puzzles—Tower of Hanoi (moving disks between pegs), checkers jumping (eliminating pieces), river crossing (transporting items with constraints), and blocks world (stacking blocks)—scaling them from trivially easy (like one-disk Hanoi) to extremely complex (20-disk Hanoi requiring over a million moves).
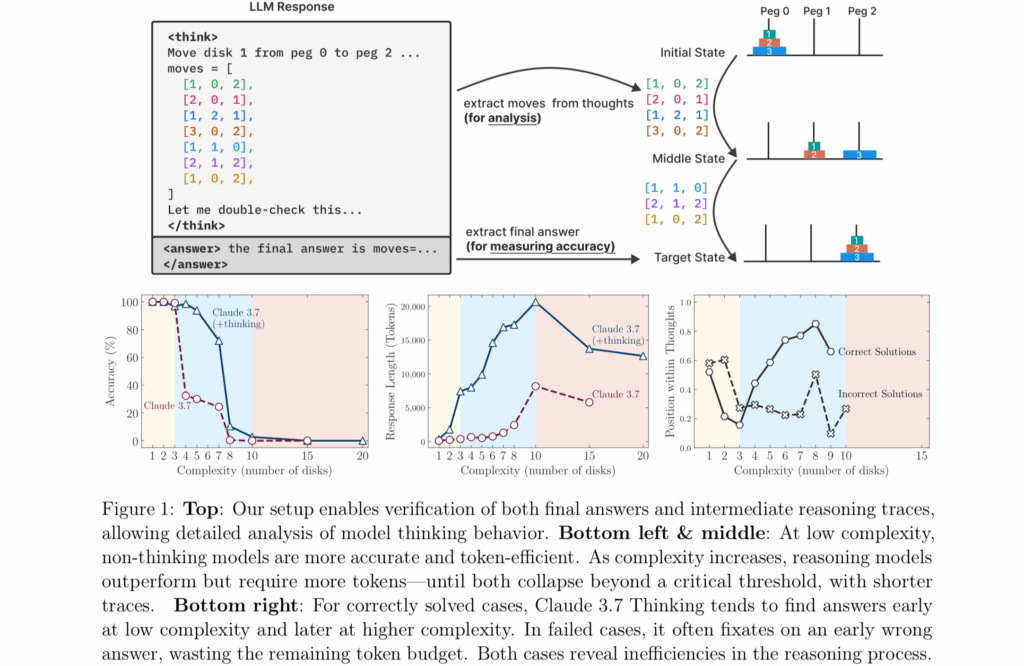
Figure 1 from Apple’s “The Illusion of Thinking” research paper. Credit: Apple
“Current evaluations primarily focus on established mathematical and coding benchmarks, emphasizing final answer accuracy,” the researchers write. In other words, today’s tests only care if the model gets the right answer to math or coding problems that may already be in its training data—they don’t examine whether the model actually reasoned its way to that answer or simply pattern-matched from examples it had seen before.
Ultimately, the researchers found results consistent with the aforementioned USAMO research, showing that these same models achieved mostly under 5 percent on novel mathematical proofs, with only one model reaching 25 percent, and not a single perfect proof among nearly 200 attempts. Both research teams documented severe performance degradation on problems requiring extended systematic reasoning.
Known skeptics and new evidence
AI researcher Gary Marcus, who has long argued that neural networks struggle with out-of-distribution generalization, called the Apple results “pretty devastating to LLMs.” While Marcus has been making similar arguments for years and is known for his AI skepticism, the new research provides fresh empirical support for his particular brand of criticism.
“It is truly embarrassing that LLMs cannot reliably solve Hanoi,” Marcus wrote, noting that AI researcher Herb Simon solved the puzzle in 1957 and many algorithmic solutions are available on the web. Marcus pointed out that even when researchers provided explicit algorithms for solving Tower of Hanoi, model performance did not improve—a finding that study co-lead Iman Mirzadeh argued shows “their process is not logical and intelligent.”
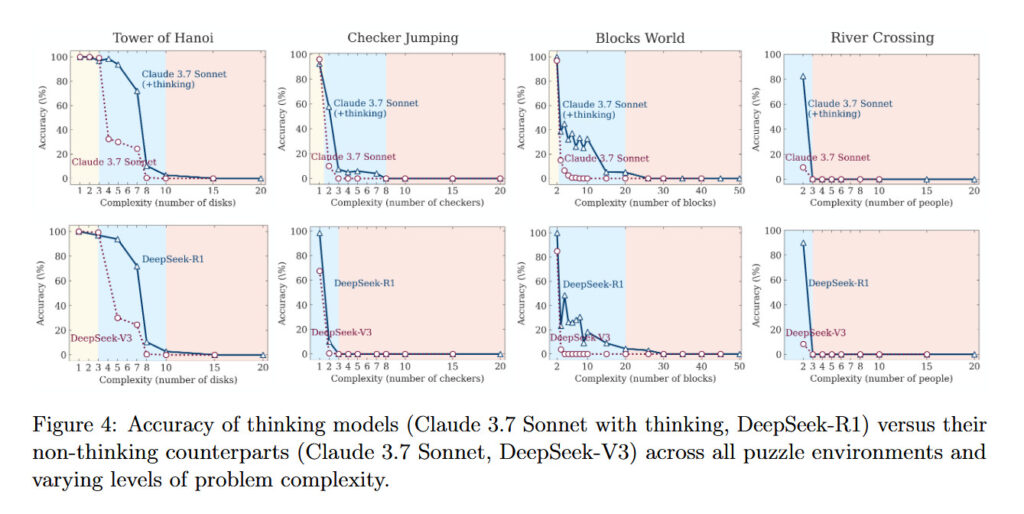
Figure 4 from Apple’s “The Illusion of Thinking” research paper. Credit: Apple
The Apple team found that simulated reasoning models behave differently from “standard” models (like GPT-4o) depending on puzzle difficulty. On easy tasks, such as Tower of Hanoi with just a few disks, standard models actually won because reasoning models would “overthink” and generate long chains of thought that led to incorrect answers. On moderately difficult tasks, SR models’ methodical approach gave them an edge. But on truly difficult tasks, including Tower of Hanoi with 10 or more disks, both types failed entirely, unable to complete the puzzles, no matter how much time they were given.
The researchers also identified what they call a “counterintuitive scaling limit.” As problem complexity increases, simulated reasoning models initially generate more thinking tokens but then reduce their reasoning effort beyond a threshold, despite having adequate computational resources.
The study also revealed puzzling inconsistencies in how models fail. Claude 3.7 Sonnet could perform up to 100 correct moves in Tower of Hanoi but failed after just five moves in a river crossing puzzle—despite the latter requiring fewer total moves. This suggests the failures may be task-specific rather than purely computational.
Competing interpretations emerge
However, not all researchers agree with the interpretation that these results demonstrate fundamental reasoning limitations. University of Toronto economist Kevin A. Bryan argued on X that the observed limitations may reflect deliberate training constraints rather than inherent inabilities.
“If you tell me to solve a problem that would take me an hour of pen and paper, but give me five minutes, I’ll probably give you an approximate solution or a heuristic. This is exactly what foundation models with thinking are RL’d to do,” Bryan wrote, suggesting that models are specifically trained through reinforcement learning (RL) to avoid excessive computation.
Bryan suggests that unspecified industry benchmarks show “performance strictly increases as we increase in tokens used for inference, on ~every problem domain tried,” but notes that deployed models intentionally limit this to prevent “overthinking” simple queries. This perspective suggests the Apple paper may be measuring engineered constraints rather than fundamental reasoning limits.
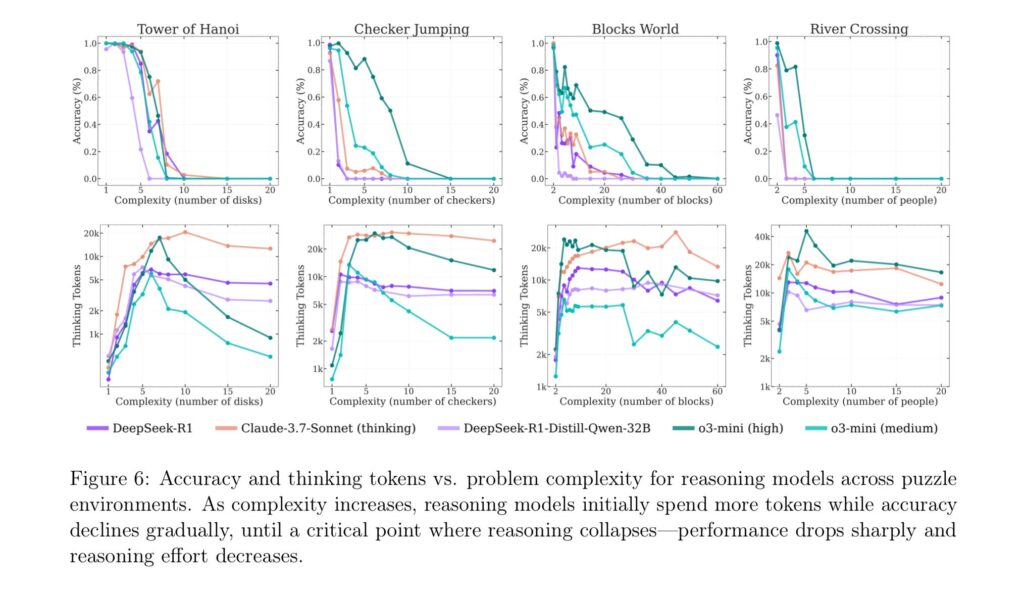
Figure 6 from Apple’s “The Illusion of Thinking” research paper. Credit: Apple
Software engineer Sean Goedecke offered a similar critique of the Apple paper on his blog, noting that when faced with Tower of Hanoi requiring over 1,000 moves, DeepSeek-R1 “immediately decides ‘generating all those moves manually is impossible,’ because it would require tracking over a thousand moves. So it spins around trying to find a shortcut and fails.” Goedecke argues this represents the model choosing not to attempt the task rather than being unable to complete it.
Other researchers also question whether these puzzle-based evaluations are even appropriate for LLMs. Independent AI researcher Simon Willison told Ars Technica in an interview that the Tower of Hanoi approach as “not exactly a sensible way to apply LLMs, with or without reasoning,” and suggesting the failures might simply reflect running out of tokens in the context window (the maximum amount of text an AI model can process) rather than reasoning deficits. He characterized the paper as potentially overblown research that gained attention primarily due to its “irresistible headline” about Apple claiming LLMs don’t reason.
The Apple researchers themselves caution against over-extrapolating the results of their study, acknowledging in their limitations section that “puzzle environments represent a narrow slice of reasoning tasks and may not capture the diversity of real-world or knowledge-intensive reasoning problems.” The paper also acknowledges that reasoning models show improvements in the “medium complexity” range and continue to demonstrate utility in some real-world applications.
Implications remain contested
Have the credibility of claims about AI reasoning models been completely destroyed by these two studies? Not necessarily.
What these studies may suggest instead is that the kinds of extended context reasoning hacks used by SR models may not be a pathway to general intelligence, like some have hoped. In that case, the path to more robust reasoning capabilities may require fundamentally different approaches rather than refinements to current methods.
As Willison noted above, the results of the Apple study have so far been explosive in the AI community. Generative AI is a controversial topic, with many people gravitating toward extreme positions in an ongoing ideological battle over the models’ general utility. Many proponents of generative AI have contested the Apple results, while critics have latched onto the study as a definitive knockout blow for LLM credibility.
Apple’s results, combined with the USAMO findings, seem to strengthen the case made by critics like Marcus that these systems rely on elaborate pattern-matching rather than the kind of systematic reasoning their marketing might suggest. To be fair, much of the generative AI space is so new that even its inventors do not yet fully understand how or why these techniques work. In the meantime, AI companies might build trust by tempering some claims about reasoning and intelligence breakthroughs.
However, that doesn’t mean these AI models are useless. Even elaborate pattern-matching machines can be useful in performing labor-saving tasks for the people that use them, given an understanding of their drawbacks and confabulations. As Marcus concedes, “At least for the next decade, LLMs (with and without inference time “reasoning”) will continue have their uses, especially for coding and brainstorming and writing.”

Benj Edwards is Ars Technica’s Senior AI Reporter and founder of the site’s dedicated AI beat in 2022. He’s also a tech historian with almost two decades of experience. In his free time, he writes and records music, collects vintage computers, and enjoys nature. He lives in Raleigh, NC.