
Microsoft has released Phi-4-reasoning-vision-15B, a 15 billion parameter open-weight multimodal reasoning model designed for image and text tasks that require […]
Category: Vision Language Model

Physical Intelligence Team Unveils MEM for Robots: A Multi-Scale Memory System Giving Gemma 3-4B VLAs 15-Minute Context for Complex Tasks
Current end-to-end robotic policies, specifically Vision-Language-Action (VLA) models, typically operate on a single observation or a very short history. This […]
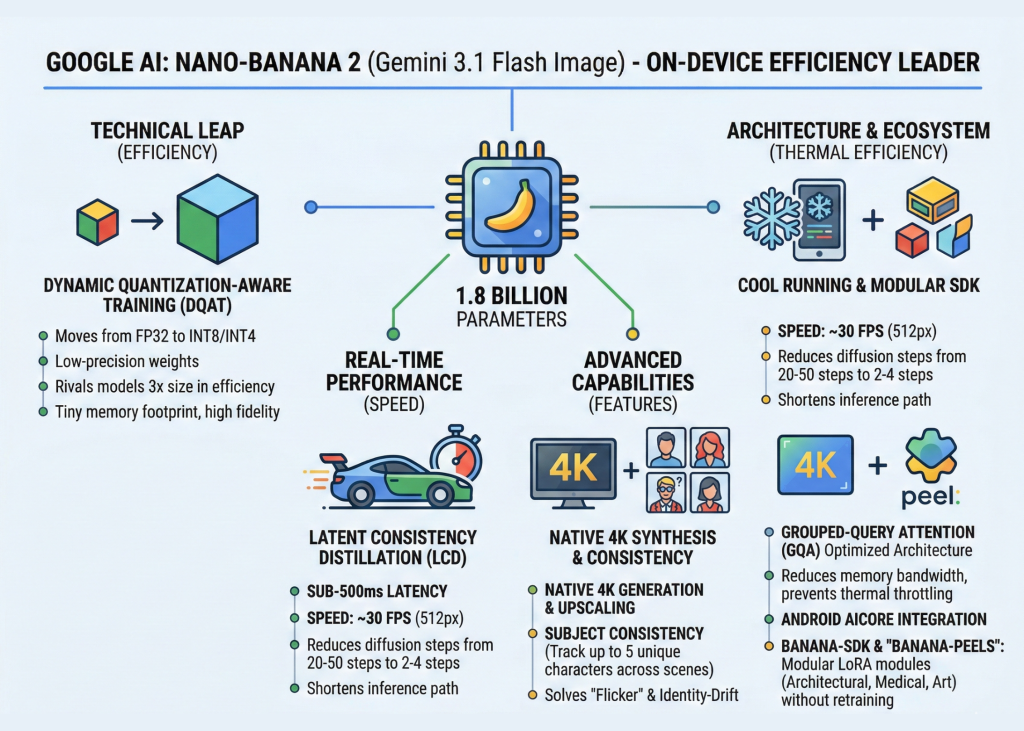
Google AI Just Released Nano-Banana 2: The New AI Model Featuring Advanced Subject Consistency and Sub-Second 4K Image Synthesis Performance
In the escalating ‘race of “smaller, faster, cheaper’ AI, Google just dropped a heavy-hitting payload. The tech giant officially unveiled […]

NVIDIA Releases DreamDojo: An Open-Source Robot World Model Trained on 44,711 Hours of Real-World Human Video Data
Building simulators for robots has been a long term challenge. Traditional engines require manual coding of physics and perfect 3D […]

Google Introduces Agentic Vision in Gemini 3 Flash for Active Image Understanding
Frontier multimodal models usually process an image in a single pass. If they miss a serial number on a chip […]

Ant Group Releases LingBot-VLA, A Vision Language Action Foundation Model For Real World Robot Manipulation
How do you build a single vision language action model that can control many different dual arm robots in the […]
Liquid AI Releases LFM2.5: A Compact AI Model Family For Real On Device Agents
Liquid AI has introduced LFM2.5, a new generation of small foundation models built on the LFM2 architecture and focused at […]

Zhipu AI Releases GLM-4.6V: A 128K Context Vision Language Model with Native Tool Calling
Zhipu AI has open sourced the GLM-4.6V series as a pair of vision language models that treat images, video and […]

Jina AI Releases Jina-VLM: A 2.4B Multilingual Vision Language Model Focused on Token Efficient Visual QA
Jina AI has released Jina-VLM, a 2.4B parameter vision language model that targets multilingual visual question answering and document understanding […]
Tencent Hunyuan Releases HunyuanOCR: a 1B Parameter End to End OCR Expert VLM
Tencent Hunyuan has released HunyuanOCR, a 1B parameter vision language model that is specialized for OCR and document understanding. The […]