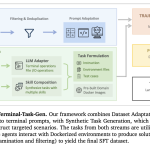
The race to build autonomous AI agents has hit a massive bottleneck: data. While frontier models like Claude Code and […]
Category: Editors Pick
How to Build a Risk-Aware AI Agent with Internal Critic, Self-Consistency Reasoning, and Uncertainty Estimation for Reliable Decision-Making
In this tutorial, we build an advanced agent system that goes beyond simple response generation by integrating an internal critic […]

ByteDance Releases DeerFlow 2.0: An Open-Source SuperAgent Harness that Orchestrates Sub-Agents, Memory, and Sandboxes to do Complex Tasks
The era of the ‘Copilot’ is officially getting an upgrade. While the tech world has spent the last two years […]

Andrew Ng’s Team Releases Context Hub: An Open Source Tool that Gives Your Coding Agent the Up-to-Date API Documentation It Needs
In the fast-moving world of agentic workflows, the most powerful AI model is still only as good as its documentation. […]
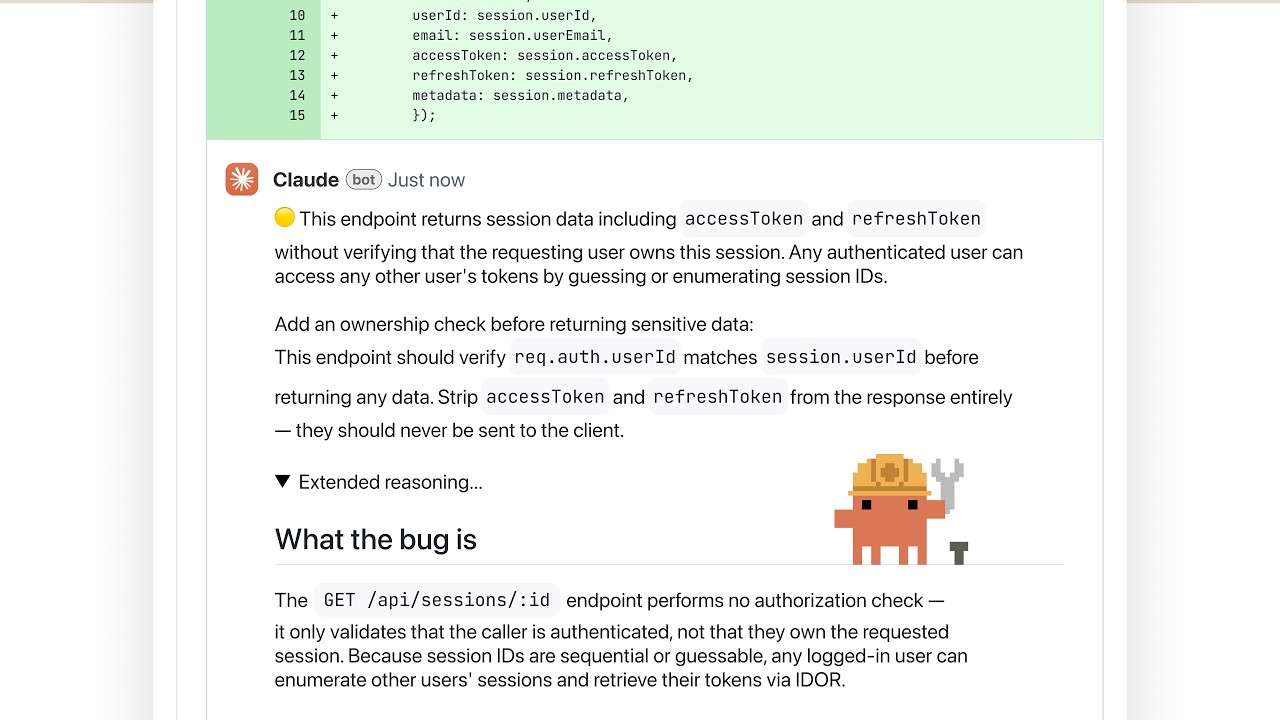
Anthropic Introduces Code Review via Claude Code to Automate Complex Security Research Using Advanced Agentic Multi-Step Reasoning Loops
In the frantic arms race of ‘AI for code,’ we’ve moved past the era of the glorified autocomplete. Today, Anthropic […]

The ‘Bayesian’ Upgrade: Why Google AI’s New Teaching Method is the Key to LLM Reasoning
Large Language Models (LLMs) are the world’s best mimics, but when it comes to the cold, hard logic of updating […]

A Coding Guide to Build a Complete Single Cell RNA Sequencing Analysis Pipeline Using Scanpy for Clustering Visualization and Cell Type Annotation
In this tutorial, we build a complete pipeline for single-cell RNA sequencing analysis using Scanpy. We start by installing the […]

Andrej Karpathy Open-Sources ‘Autoresearch’: A 630-Line Python Tool Letting AI Agents Run Autonomous ML Experiments on Single GPUs
Andrej Karpathy released autoresearch, a minimalist Python tool designed to enable AI agents to autonomously conduct machine learning experiments. The […]
Beyond Accuracy: Quantifying the Production Fragility Caused by Excessive, Redundant, and Low-Signal Features in Regression
At first glance, adding more features to a model seems like an obvious way to improve performance. If a model […]
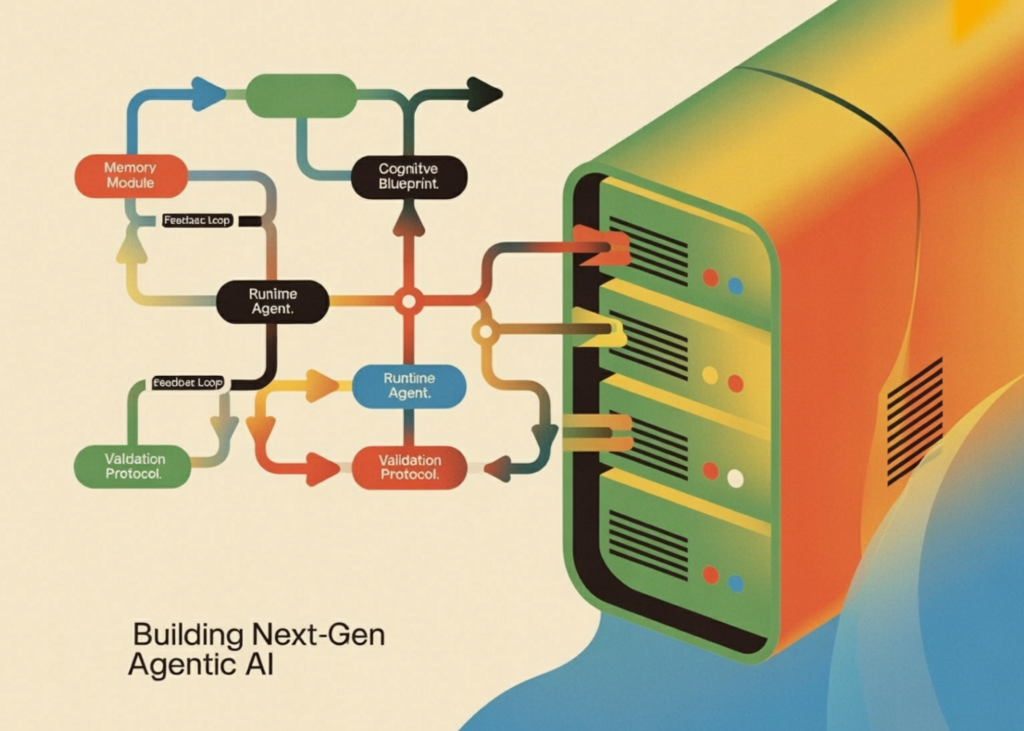
Building Next-Gen Agentic AI: A Complete Framework for Cognitive Blueprint Driven Runtime Agents with Memory Tools and Validation
In this tutorial, we build a complete cognitive blueprint and runtime agent framework. We define structured blueprints for identity, goals, […]