
Diffusion Transformers have demonstrated outstanding performance in image generation tasks, surpassing traditional models, including GANs and autoregressive architectures. They operate […]
Category: Computer Vision

Long-Context Multimodal Understanding No Longer Requires Massive Models: NVIDIA AI Introduces Eagle 2.5, a Generalist Vision-Language Model that Matches GPT-4o on Video Tasks Using Just 8B Parameters
In recent years, vision-language models (VLMs) have advanced significantly in bridging image, video, and textual modalities. Yet, a persistent limitation […]

Stanford Researchers Propose FramePack: A Compression-based AI Framework to Tackle Drifting and Forgetting in Long-Sequence Video Generation Using Efficient Context Management and Sampling
Video generation, a branch of computer vision and machine learning, focuses on creating sequences of images that simulate motion and […]

Meta AI Released the Perception Language Model (PLM): An Open and Reproducible Vision-Language Model to Tackle Challenging Visual Recognition Tasks
Despite rapid advances in vision-language modeling, much of the progress in this field has been shaped by models trained on […]

Meta AI Introduces Perception Encoder: A Large-Scale Vision Encoder that Excels Across Several Vision Tasks for Images and Video
The Challenge of Designing General-Purpose Vision Encoders As AI systems grow increasingly multimodal, the role of visual perception models becomes […]

Do We Still Need Complex Vision-Language Pipelines? Researchers from ByteDance and WHU Introduce Pixel-SAIL—A Single Transformer Model for Pixel-Level Understanding That Outperforms 7B MLLMs
MLLMs have recently advanced in handling fine-grained, pixel-level visual understanding, thereby expanding their applications to tasks such as precise region-based […]
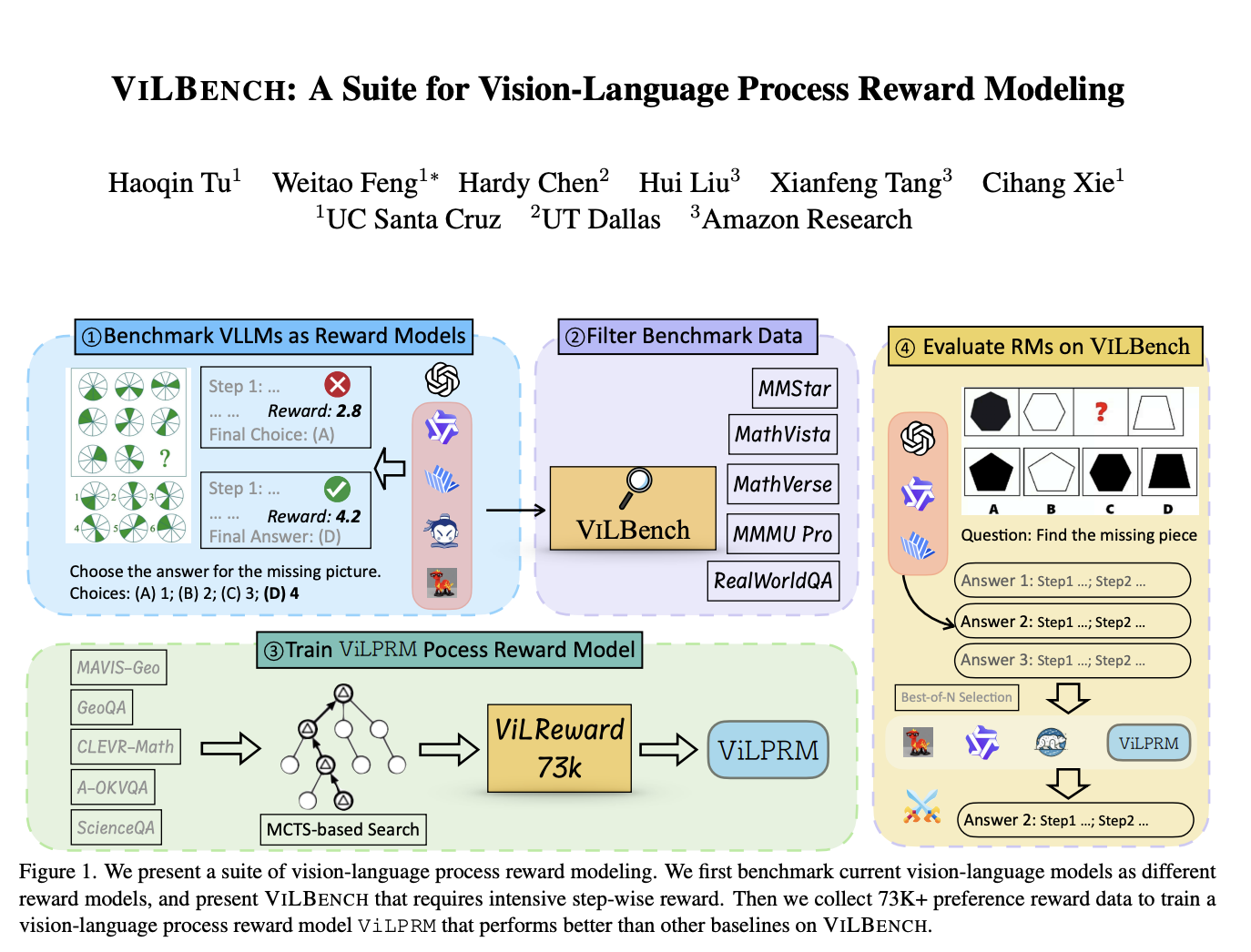
Advancing Vision-Language Reward Models: Challenges, Benchmarks, and the Role of Process-Supervised Learning
Process-supervised reward models (PRMs) offer fine-grained, step-wise feedback on model responses, aiding in selecting effective reasoning paths for complex tasks. […]

VideoMind: A Role-Based Agent for Temporal-Grounded Video Understanding
LLMs have shown impressive capabilities in reasoning tasks like Chain-of-Thought (CoT), enhancing accuracy and interpretability in complex problem-solving. While researchers […]

Meta Reality Labs Research Introduces Sonata: Advancing Self-Supervised Representation Learning for 3D Point Clouds
3D self-supervised learning (SSL) has faced persistent challenges in developing semantically meaningful point representations suitable for diverse applications with minimal […]

TokenBridge: Bridging The Gap Between Continuous and Discrete Token Representations In Visual Generation
Autoregressive visual generation models have emerged as a groundbreaking approach to image synthesis, drawing inspiration from language model token prediction […]